Redis 的幾種常見使用方式包括:
- Redis 單副本
- Redis 多副本(主從)
- Redis Sentinel(哨兵)
- Redis Cluster
Redis 單副本,采用單個 Redis 節點部署架構,沒有備用節點實時同步資料,不提供資料持久化和備份政策,适用于資料可靠性要求不高的純緩存業務場景。
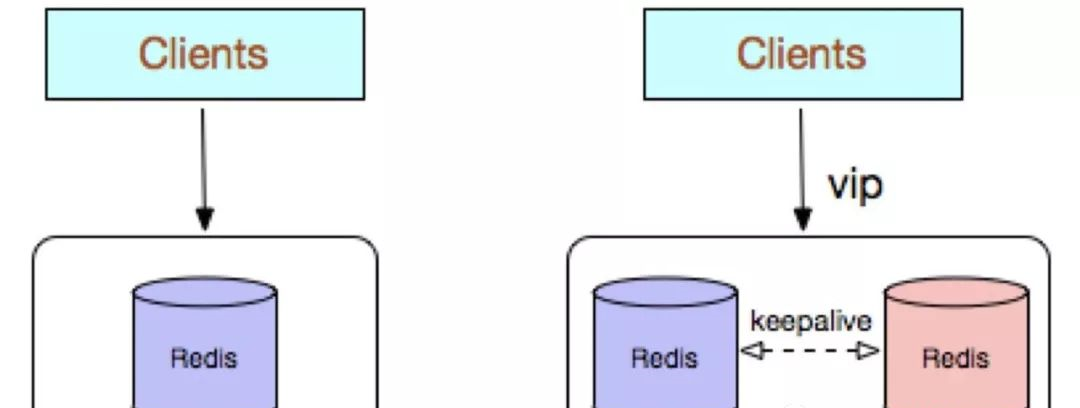
優點:
- 架構簡單,部署友善。
- 高成本效益:緩存使用時無需備用節點(單執行個體可用性可以用 supervisor 或 crontab 保證),當然為了滿足業務的高可用性,也可以犧牲一個備用節點,但同時刻隻有一個執行個體對外提供服務。
- 高性能。
缺點:
- 不保證資料的可靠性。
- 在緩存使用,程序重新開機後,資料丢失,即使有備用的節點解決高可用性,但是仍然不能解決緩存預熱問題,是以不适用于資料可靠性要求高的業務。
- 高性能受限于單核 CPU 的處理能力(Redis 是單線程機制),CPU 為主要瓶頸,是以适合操作指令簡單,排序、計算較少的場景。也可以考慮用 Memcached 替代。
Redis 多副本,采用主從(replication)部署結構,相較于單副本而言最大的特點就是主從執行個體間資料實時同步,并且提供資料持久化和備份政策。
主從執行個體部署在不同的實體伺服器上,根據公司的基礎環境配置,可以實作同時對外提供服務和讀寫分離政策。
- 高可靠性:一方面,采用雙機主備架構,能夠在主庫出現故障時自動進行主備切換,從庫提升為主庫提供服務,保證服務平穩運作;另一方面,開啟資料持久化功能和配置合理的備份政策,能有效的解決資料誤操作和資料異常丢失的問題。
- 讀寫分離政策:從節點可以擴充主庫節點的讀能力,有效應對大并發量的讀操作。
- 故障恢複複雜,如果沒有 Redis HA 系統(需要開發),當主庫節點出現故障時,需要手動将一個從節點晉升為主節點,同時需要通知業務方變更配置,并且需要讓其他從庫節點去複制新主庫節點,整個過程需要人為幹預,比較繁瑣。
- 主庫的寫能力受到單機的限制,可以考慮分片。
- 主庫的存儲能力受到單機的限制,可以考慮 Pika。
- 原生複制的弊端在早期的版本中也會比較突出,如:Redis 複制中斷後,Slave 會發起 psync,此時如果同步不成功,則會進行全量同步,主庫執行全量備份的同時可能會造成毫秒或秒級的卡頓。
又由于 COW 機制,導緻極端情況下的主庫記憶體溢出,程式異常退出或當機;主庫節點生成備份檔案導緻伺服器磁盤 IO 和 CPU(壓縮)資源消耗;發送數 GB 大小的備份檔案導緻伺服器出口帶寬暴增,阻塞請求,建議更新到最新版本。
Redis Sentinel 是社群版本推出的原生高可用解決方案,其部署架構主要包括兩部分:Redis Sentinel 叢集和 Redis 資料叢集。
其中 Redis Sentinel 叢集是由若幹 Sentinel 節點組成的分布式叢集,可以實作故障發現、故障自動轉移、配置中心和用戶端通知。Redis Sentinel 的節點數量要滿足 2n+1(n>=1)的奇數個。

- Redis Sentinel 叢集部署簡單;
- 能夠解決 Redis 主從模式下的高可用切換問題;
- 很友善實作 Redis 資料節點的線形擴充,輕松突破 Redis 自身單線程瓶頸,可極大滿足 Redis 大容量或高性能的業務需求;
- 可以實作一套 Sentinel 監控一組 Redis 資料節點或多組資料節點。
- 部署相對 Redis 主從模式要複雜一些,原理了解更繁瑣;
- 資源浪費,Redis 資料節點中 slave 節點作為備份節點不提供服務;
- Redis Sentinel 主要是針對 Redis 資料節點中的主節點的高可用切換,對 Redis 的資料節點做失敗判定分為主觀下線和客觀下線兩種,對于 Redis 的從節點有對節點做主觀下線操作,并不執行故障轉移。
- 不能解決讀寫分離問題,實作起來相對複雜。
建議:
- 如果監控同一業務,可以選擇一套 Sentinel 叢集監控多組 Redis 資料節點的方案,反之選擇一套 Sentinel 監控一組 Redis 資料節點的方案。
- sentinel monitor <master-name> <ip> <port> <quorum> 配置中的<quorum>建議設定成 Sentinel 節點的一半加 1,當 Sentinel 部署在多個 IDC 的時候,單個 IDC 部署的 Sentinel 數量不建議超過(Sentinel 數量 – quorum)。
-
合理設定參數,防止誤切,控制切換靈敏度控制:
a. quorum
b. down-after-milliseconds 30000
c. failover-timeout 180000
d. maxclient
e. timeout
- 部署的各個節點伺服器時間盡量要同步,否則日志的時序性會混亂。
- Redis 建議使用 pipeline 和 multi-keys 操作,減少 RTT 次數,提高請求效率。
- 自行搞定配置中心(zookeeper),友善用戶端對執行個體的連結通路。
Redis Cluster 是社群版推出的 Redis 分布式叢集解決方案,主要解決 Redis 分布式方面的需求,比如,當遇到單機記憶體,并發和流量等瓶頸的時候,Redis Cluster 能起到很好的負載均衡的目的。
Redis Cluster 叢集節點最小配置 6 個節點以上(3 主 3 從),其中主節點提供讀寫操作,從節點作為備用節點,不提供請求,隻作為故障轉移使用。
Redis Cluster 采用虛拟槽分區,所有的鍵根據哈希函數映射到 0~16383 個整數槽内,每個節點負責維護一部分槽以及槽所映射的鍵值資料。
- 無中心架構;
- 資料按照 slot 存儲分布在多個節點,節點間資料共享,可動态調整資料分布;
- 可擴充性:可線性擴充到 1000 多個節點,節點可動态添加或删除;
- 高可用性:部分節點不可用時,叢集仍可用。通過增加 Slave 做 standby 資料副本,能夠實作故障自動 failover,節點之間通過 gossip 協定交換狀态資訊,用投票機制完成 Slave 到 Master 的角色提升;
- 降低運維成本,提高系統的擴充性和可用性。
- Client 實作複雜,驅動要求實作 Smart Client,緩存 slots mapping 資訊并及時更新,提高了開發難度,用戶端的不成熟影響業務的穩定性。目前僅 JedisCluster 相對成熟,異常處理部分還不完善,比如常見的“max redirect exception”。
- 節點會因為某些原因發生阻塞(阻塞時間大于 clutser-node-timeout),被判斷下線,這種 failover 是沒有必要的。
- 資料通過異步複制,不保證資料的強一緻性。
- 多個業務使用同一套叢集時,無法根據統計區分冷熱資料,資源隔離性較差,容易出現互相影響的情況。
- Slave 在叢集中充當“冷備”,不能緩解讀壓力,當然可以通過 SDK 的合理設計來提高 Slave 資源的使用率。
- Key 批量操作限制,如使用 mset、mget 目前隻支援具有相同 slot 值的 Key 執行批量操作。對于映射為不同 slot 值的 Key 由于 Keys 不支援跨 slot 查詢,是以執行 mset、mget、sunion 等操作支援不友好。
- Key 事務操作支援有限,隻支援多 key 在同一節點上的事務操作,當多個 Key 分布于不同的節點上時無法使用事務功能。
- Key 作為資料分區的最小粒度,不能将一個很大的鍵值對象如 hash、list 等映射到不同的節點。
- 不支援多資料庫空間,單機下的 redis 可以支援到 16 個資料庫,叢集模式下隻能使用 1 個資料庫空間,即db 0 。
- 複制結構隻支援一層,從節點隻能複制主節點,不支援嵌套樹狀複制結構。
- 避免産生 hot-key,導緻主庫節點成為系統的短闆。
- 避免産生 big-key,導緻網卡撐爆、慢查詢等。
- 重試時間應該大于 cluster-node-time 時間。
- Redis Cluster 不建議使用 pipeline和multi-keys 操作,減少 max redirect 産生的場景。
上面都是redis的常見高可用實作方案的簡單概述和對比,下面對redis内部實作高可用的兩個具體場景的原理進行分析:
- 主從複制資料。
- 采用哨兵監控資料節點的運作情況,一旦主節點出現問題由從節點頂上繼續進行服務。
主從複制
redis中主從節點複制資料有全量複制和部分複制之分。
舊版本全量複制功能的實作
全量複制使用snyc指令來實作,其流程是:
- 從伺服器向主伺服器發送sync指令。
- 主伺服器在收到sync指令之後,調用bgsave指令生成最新的rdb檔案,将這個檔案同步給從伺服器,這樣從伺服器載入這個rdb檔案之後,狀态就會和主伺服器執行bgsave指令時候的一緻。
- 主伺服器将儲存在指令緩沖區中的寫指令同步給從伺服器,從伺服器執行這些指令,這樣從伺服器的狀态就跟主伺服器目前狀态一緻了。
舊版本全量複制功能,其最大的問題是從伺服器斷線重連時,即便在從伺服器上已經有一部分資料了,也需要進行全量複制,這樣做的效率很低,于是新版本的redis在這部分做了改進。
新版本全量複制功能的實作
新版本redis使用psync指令來代替sync指令,該指令既可以實作完整全同步也可以實作部分同步。
複制偏移量
執行複制的雙方,主從伺服器,分别會維護一個複制偏移量:
- 主伺服器每次向從伺服器同步了N位元組資料之後,将修改自己的複制偏移量+N。
- 從伺服器每次從主伺服器同步了N位元組資料之後,将修改自己的複制偏移量+N。
複制積壓緩沖區
主伺服器内部維護了一個固定長度的先進先出隊列做為複制積壓緩沖區,其預設大小為1MB。
在主伺服器進行指令傳播時,不僅會将寫指令同步到從伺服器,還會将寫指令寫入複制積壓緩沖區。
伺服器運作ID
每個redis伺服器,都有其運作ID,運作ID由伺服器在啟動時自動生成,主伺服器會将自己的運作ID發送給從伺服器,而從伺服器會将主伺服器的運作ID儲存起來。
從伺服器redis斷線重連之後進行同步時,就是根據運作ID來判斷同步的進度:
- 如果從伺服器上面儲存的主伺服器運作ID與目前主伺服器運作ID一緻,則認為這一次斷線重連連接配接的是之前複制的主伺服器,主伺服器可以繼續嘗試部分同步操作。
- 否則,如果前後兩次主伺服器運作ID不相同,則認為是完成全同步流程。
psync指令流程
有了前面的準備,下面開始分析psync指令的流程:
- 如果從伺服器之前沒有複制過任何主伺服器,或者之前執行過slaveof no one指令,那麼從伺服器就會向主伺服器發送psync ? -1指令,請求主伺服器進行資料的全量同步。
- 否則,如果前面從伺服器已經同步過部分資料,那麼從伺服器向主伺服器發送psync <runid> <offset>指令,其中runid是上一次主伺服器的運作id,offset是目前從伺服器的複制偏移量。
前面兩種情況主伺服器收到psync指令之後,會出現以下三種可能:
- 主伺服器傳回+fullresync <runid> <offset>回複,表示主伺服器要求與從伺服器進行完整的資料全量同步操作。其中,runid是目前主伺服器運作id,而offset是目前主伺服器的複制偏移量。
- 如果主伺服器應答+continue,那麼表示主伺服器與從伺服器進行部分資料同步操作,将從伺服器缺失的資料同步過來即可。
- 如果主伺服器應答-err,那麼表示主伺服器版本低于2.8,識别不了psync指令,此時從伺服器将向主伺服器發送sync指令,執行完整的全量資料同步。
哨兵機制
redis使用哨兵機制來實作高可用(HA),其大概工作原理是:
- redis使用一組哨兵(sentinel)節點來監控主從redis服務的可用性。
- 一旦發現redis主節點失效,将選舉出一個哨兵節點作為上司者(leader)。
- 哨兵上司者再從剩餘的從redis節點中選出一個redis節點作為新的主redis節點對外服務。
以上将redis節點分為兩類:
- 哨兵節點(sentinel):負責監控節點的運作情況。
- 資料節點:即正常服務用戶端請求的redis節點,有主從之分。
以上是大體的流程,這個流程需要解決以下幾個問題:
- 如何對redis資料節點進行監控?
- 如何确定一個redis資料節點失效?
- 如何選擇出一個哨兵上司者節點?
- 哨兵節點選擇新的主redis節點的依據是什麼?
以下來逐個回答這些問題。
三個監控任務
哨兵節點通過三個定時監控任務監控redis資料節點的服務可用性。
info指令
每隔10秒,每個哨兵節點都會向主、從redis資料節點發送info指令,擷取新的拓撲結構資訊。
redis拓撲結構資訊包括了:
- 本節點角色:主或從。
- 主從節點的位址、端口資訊。
這樣,哨兵節點就能從info指令中自動擷取到從節點資訊,是以那些後續才加入的從節點資訊不需要顯式配置就能自動感覺。
向__sentinel__:hello頻道同步資訊
每隔2秒,每個哨兵節點将會向redis資料節點的__sentinel__:hello頻道同步自身得到的主節點資訊以及目前哨兵節點的資訊,由于其他哨兵節點也訂閱了這個頻道,是以實際上這個操作可以交換哨兵節點之間關于主節點以及哨兵節點的資訊。
這一操作實際上完成了兩件事情:* 發現新的哨兵節點:如果有新的哨兵節點加入,此時儲存下來這個新哨兵節點的資訊,後續與該哨兵節點建立連接配接。* 交換主節點的狀态資訊,作為後續客觀判斷主節點下線的依據。
向資料節點做心跳探測
每隔1秒,每個哨兵節點向主、從資料節點以及其他sentinel節點發送ping指令做心跳探測,這個心跳探測是後續主觀判斷資料節點下線的依據。
主觀下線和客觀下線
主觀下線
上面三個監控任務中的第三個探測心跳任務,如果在配置的down-after-milliseconds之後沒有收到有效回複,那麼就認為該資料節點“主觀下線(sdown)”。
為什麼稱為“主觀下線”?因為在一個分布式系統中,有多個機器在一起關聯工作,網絡可能出現各種狀況,僅憑一個節點的判斷還不足以認為一個資料節點下線了,這就需要後面的“客觀下線”。
客觀下線
當一個哨兵節點認為主節點主觀下線時,該哨兵節點需要通過”sentinel is-master-down-by addr”指令向其他哨兵節點咨詢該主節點是否下線了,如果有超過半數的哨兵節點都回答了下線,此時認為主節點“客觀下線”。
選舉哨兵上司者
當主節點客觀下線時,需要選舉出一個哨兵節點做為哨兵上司者,以完成後續選出新的主節點的工作。
這個選舉的大體思路是:
- 每個哨兵節點通過向其他哨兵節點發送”sentinel is-master-down-by addr”指令來申請成為哨兵上司者。
- 而每個哨兵節點在收到一個”sentinel is-master-down-by addr”指令時,隻允許給第一個節點投票,其他節點的該指令都會被拒絕。
- 如果一個哨兵節點收到了半數以上的同意票,則成為哨兵上司者。
- 如果前面三步在一定時間内都沒有選出一個哨兵上司者,将重新開始下一次選舉。
可以看到,這個選舉上司者的流程很像raft中選舉leader的流程。
選出新的主節點
在剩下的redis從節點中,按照以下順序來選擇新的主節點:
- 過濾掉“不健康”的資料節點:比如主觀下線、斷線的從節點、五秒内沒有回複過哨兵節點ping指令的節點、與主節點失聯的從節點。
- 選擇slave-priority(從節點優先級)最高的從節點,如果存在則傳回不存在則繼續後面的流程。
- 選擇複制偏移量最大的從節點,這意味着這個從節點上面的資料最完整,如果存在則傳回不存在則繼續後面的流程。
到了這裡,所有剩餘從節點的狀态都是一樣的,選擇runid最小的從節點。
提升新的主節點
選擇了新的主節點之後,還需要最後的流程讓該節點成為新的主節點:
- 哨兵上司者向上一步選出的從節點發出“slaveof no one”指令,讓該節點成為主節點。
- 哨兵上司者向剩餘的從節點發送指令,讓它們成為新主節點的從節點。
- 哨兵節點集合會将原來的主節點更新為從節點,當其恢複之後指令它去複制新的主節點的資料。
推薦閱讀
架構實踐系列:
分布式唯一ID生成方案如何解決并發場景下扣款的資料一緻性問題?如何保障mysql和redis之間的資料一緻性?高并發系統下的緩存解決方案Redis如何實作異地多活?如何提升支付系統熱點賬戶沖扣性能?高并發高性能的DB資料複制方案再談Redis雙活實作方案高并發系統的限流方案如何實作?高并發系統下的降級如何實作?徹底弄懂Redis的記憶體淘汰政策實時動态更新配置究竟要怎麼做?億級資料DB如何實作秒級平滑擴容如何了解兩階段送出?
掃碼關注我們
網際網路架構師之路
過濾技術雜質,隻為精品呈現