1.概述
平時在使用Kafka的時候,可能關注的更多的是Kafka系統層面的。今天來給大家剖析一下Kafka的控制器,了解一下Kafka控制器的選舉流程。
2.内容
Kafka控制器,其實就是一個Kafka系統的Broker。它除了具有一般Broker的功能之外,還具有選舉主題分區Leader節點的功能。在啟動Kafka系統時,其中一個Broker會被選舉為控制器,負責管理主題分區和副本狀态,還會執行分區重新配置設定的管理任務。
如果在Kafka系統運作過程中,目前的控制器出現故障導緻不可用,那麼Kafka系統會從其他正常運作的Broker中重新選舉出新的控制器。
2.1 控制器啟動順序
在Kafka叢集中,每個Broker在啟動時會執行個體化一個KafkaController類。該類會執行一系列業務邏輯,選舉出主題分區的Leader節點,步驟如下:
- 第一個啟動的代理節點,會在Zookeeper系統裡面建立一個臨時節點/controller,并寫入該節點的注冊資訊,使該節點成為控制器;
- 其他的代理節點陸續啟動時,也會嘗試在Zookeeper系統中建立/controller節點,但是由于/controller節點已經存在,是以會抛出“建立/controller節點失敗異常”的資訊。建立失敗的代理節點會根據傳回的結果,判斷出在Kafka叢集中已經有一個控制器被成功建立了,是以放棄建立/controller節點,這樣就確定了Kafka叢集控制器的唯一性;
- 其他的代理節點,會在控制器上注冊相應的監聽器,各個監聽器負責監聽各自代理節點的狀态變化。當監聽到節點狀态發生變化時,會觸發相應的監聽函數進行處理。
2.2 如何檢視控制器優先級 ?
控制器建立的優先級是按照Kafka系統代理節點成功啟動的順序來建立的。使用者可以通過改變Kafka系統代理節點的啟動順序,來檢視控制器的建立優先級。之後,可以在Zookeeper系統中檢視/controller臨時節點的内容,例如:
# 進入Zookeeper叢集
[hadoop@dn1 bin]$ zkCli.sh -server dn1:2181
# 執行檢視指令
[zk: dn1:2181(CONNECTED) 1] get /controller 成功執行指令後,可以看到代理節點0(即dn1節點)上成功建立了控制器,如下圖所示:
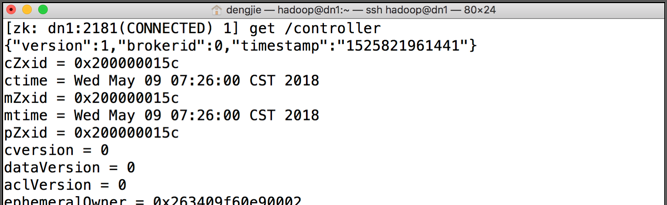
目前啟動順序為:dn1、dn2、dn3,修改啟動順序為:dn3、dn1、dn2。再次檢視Zookeeper系統中執行“get /controller”指令,輸出結果如下圖所示:

2.3 切換控制器所屬的代理節點
當控制器被關閉或者與Zookeeper系統斷開連接配接時,Zookeeper系統上的臨時節點就會被清除。Kafka叢集中的監聽器會接收到變更通知,各個代理節點會嘗試到Zookeeper系統中建立一個控制器的臨時節點。第一個成功在Zookeeper系統中建立的代理節點,将會成為新的控制器。每個新選舉出來的控制器,會在Zookeeper系統中擷取一個遞增的controller_epoch值。
3.主題分區Leader節點的選舉過程
選舉控制器的核心思路是:各個代理節點公平競争搶占Zookeeper系統中建立/controller臨時節點,最先建立成功的代理節點會成為控制器,并擁有選舉主題分區Leader節點的功能。選舉流程如下圖所示:
當Kafka系統執行個體化KafkaController類時,主題分區Leader節點的選舉流程便會開始。其中涉及的核心類包含KafkaController、ZookeeperLeaderElector、LeaderChangeListener、SessionExpirationListener。
- KafkaController:在執行個體化ZookeeperLeaderElector類時,分别設定了兩個關鍵的回調函數,即onControllerFailover和onControllerResignation;
- ZookeeperLeaderElector:實作主題分區的Leader節點選舉功能,但是它并不會處理“代理節點與Zookeeper系統之間出現的會話逾時”這種情況,它主要負責建立中繼資料存儲路徑、執行個體化變更監聽器等,并通過訂閱資料變更監聽器來實時監聽資料的變化,進而開始執行選舉Leader的邏輯;
- LeaderChangeListener:如果節點資料發送變化,則Kafka系統中的其他代理節點可能已經成為Leader,接着Kafka控制器會調用onResigningAsLeader函數。當Kafka代理節點當機或者被人為誤删除時,則處于該節點上的Leader會被重新選舉,通過調用onResigningAsLeader函數重新選擇其他正常運作的代理節點成為新的Leader;
- SessionExpirationListener:當Kafka系統的代理節點和Zookeeper系統建立連接配接後,SessionExpirationListener中的handleNewSession函數會被調用,對于Zookeeper系統中會話過期的連接配接,會先進行一次判斷。
4.注冊分區和副本狀态機
Kafka系統的控制器主要負責管理主題、分區和副本。 Kafka系統在操作主題、分區和副本時,控制器會在Zookeeper系統的/brokers/topics節點,以及其子節點路徑上注冊一系列的監聽器。 使用Kafka應用接口或者是Kafka系統腳本建立一個主題時,服務端會将建立後的結果傳回給用戶端。當用戶端收到建立成功的提示時,其實服務端并沒有實際建立主題,而隻是在Zookeeper系統的/brokers/topics節點中建立了該主題對應的子節點名稱。
代理節點調用onBecomingLeader()函數實際上調用的是onControllerFailover()函數,是以在控制器調用onControllerFailover()函數時,會在初始化階段分别建立分區狀态機和副本狀态機。代碼如下所示:
def onControllerFailover() {
if(isRunning) {
info("Broker %d starting become controller state
transition".format(config.brokerId))
readControllerEpochFromZookeeper()
incrementControllerEpoch(zkUtils.zkClient)
// 在/brokers/topics節點注冊監聽器
registerReassignedPartitionsListener()
registerIsrChangeNotificationListener()
registerPreferredReplicaElectionListener()
partitionStateMachine.registerListeners() // 注冊分區狀态機
replicaStateMachine.registerListeners() // 注冊副本狀态機
initializeControllerContext()
// 在控制器初始化之後,在狀态機啟動之前,需要發送更新中繼資料請求
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)
replicaStateMachine.startup() // 啟動副本狀态機
partitionStateMachine.startup() // 啟動分區狀态機
// 在自動故障轉移中為所有主題注冊分區更改監聽器
controllerContext.allTopics.foreach(topic => partitionStateMachine.
registerPartitionChangeListener(topic))
info("Broker %d is ready to serve as the new controller with epoch %d".
format(config.brokerId, epoch))
maybeTriggerPartitionReassignment()
maybeTriggerPreferredReplicaElection()
if (config.autoLeaderRebalanceEnable) {
info("starting the partition rebalance scheduler")
autoRebalanceScheduler.startup()
autoRebalanceScheduler.schedule("partition-rebalance-thread",
checkAndTriggerPartitionRebalance,
5,
config.leaderImbalanceCheckIntervalSeconds.toLong,
TimeUnit.SECONDS)
}
deleteTopicManager.start()
}
else
info("Controller has been shut down, aborting startup/failover")
} 主題的分區狀态機通過registerListeners()函數,在Zookeeper系統中的/brokers/topics節點上注冊了TopicChangeListener和DeleteTopicListener兩個監聽器。建立一個主題時,主題資訊、主題分區和副本會被寫到Zookeeper系統的/brokers/topics節點中,這就會觸發分區和副本狀态機注冊監聽器。
5.總結
Kafka系統整體來說,調試還算友善。下載下傳Kafka源代碼,導入到IDE中,就可以啟動整個Kafka系統了,可以通過DEBUG的方式來親自了解控制器的執行流程。
6.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行讨論或發送郵件給我,我會盡我所能為您解答,與君共勉!
另外,部落客出書了《Hadoop大資料挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點選購買連結購買部落客的書進行學習,在此感謝大家的支援。
聯系方式:
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社群1):424769183
QQ群(Kafka并不難學): 825943084
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),友善管理者稽核,謝謝!
熱愛生活,享受程式設計,與君共勉!
公衆号:
Kafka控制器選舉流程剖析