原文位址:https://my.oschina.net/pingpangkuangmo/blog/817973
本文針對jdk1.8的ConcurrentHashMap
1 1.8的HashMap設計
1.1 整體概覽
HashMap采用的是數組+連結清單+紅黑樹的形式。
數組是可以擴容的,連結清單也是轉化為紅黑樹的,這2種方式都可以承載更多的資料。
使用者可以設定的參數:初始總容量預設16,預設的加載因子0.75
初始的數組個數預設是16 容量X加載因子=門檻值
一旦目前容量超過該門檻值,則執行擴容操作。
什麼時候擴容?
- 1 目前容量超過門檻值
- 2 當連結清單中元素個數超過預設設定(8個),當數組的大小還未超過64的時候,此時進行數組的擴容,如果超過則将連結清單轉化成紅黑樹
什麼時候連結清單轉化為紅黑樹?(上面已經提到了)
- 當數組大小已經超過64并且連結清單中的元素個數超過預設設定(8個)時,将連結清單轉化為紅黑樹
目前形象的表示數組中的一個元素稱為一個桶
1.2 put過程
- 根據key計算出hash值
- hash值&(數組長度-1)得到所在數組的index
- 如果該index位置的Node元素不存在,則直接建立一個新的Node
- 如果該index位置的Node元素是TreeNode類型即紅黑樹類型了,則直接按照紅黑樹的插入方式進行插入
-
如果該index位置的Node元素是非TreeNode類型則,則按照連結清單的形式進行插入操作
連結清單插入操作完成後,判斷是否超過門檻值TREEIFY_THRESHOLD(預設是8),超過則要麼數組擴容要麼連結清單轉化成紅黑樹
- 判斷目前總容量是否超出門檻值,如果超出則執行擴容
源碼如下:
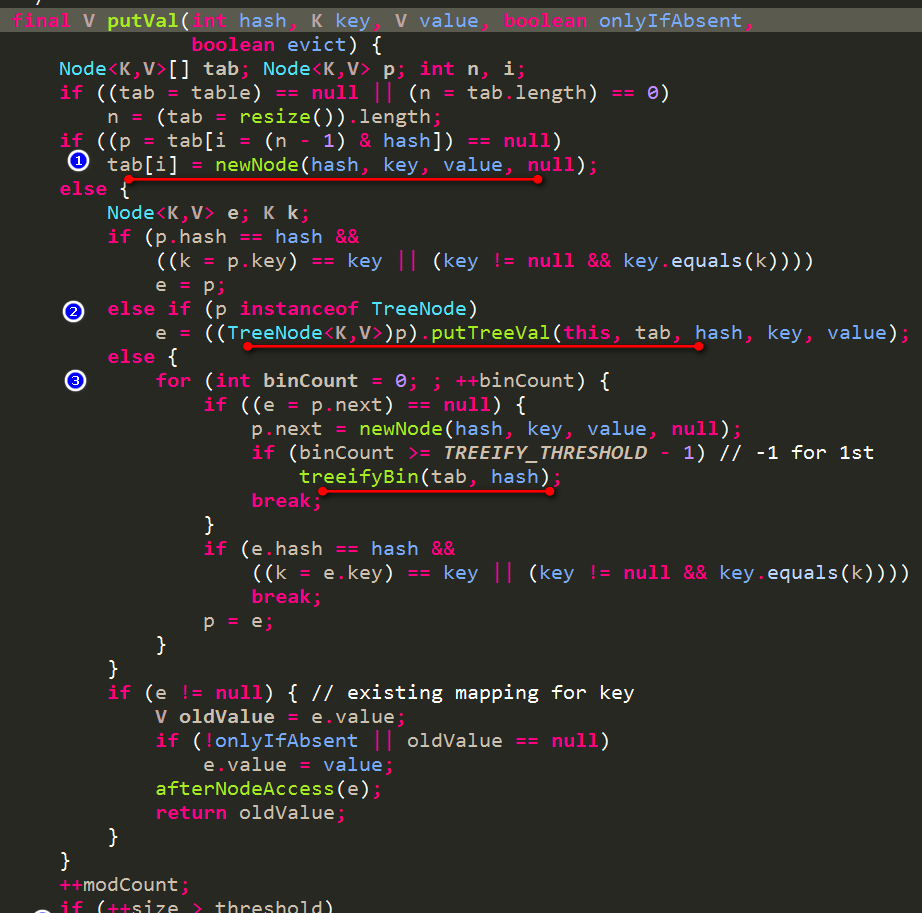
下面來說說這個擴容的過程
1.3 擴容過程
按照2倍擴容的方式,那麼就需要将之前的所有元素全部重新按照2倍桶的長度重新計算所在桶。這裡為啥是2倍?
因為2倍的話,更加容易計算他們所在的桶,并且各自不會互相幹擾。如原桶長度是4,現在桶長度是8,那麼
- 桶0中的元素會被分到桶0和桶4中
- 桶1中的元素會被分到桶1和桶5中
- 桶2中的元素會被分到桶2和桶6中
- 桶3中的元素會被分到桶3和桶7中
為啥是這樣呢?
桶0中的元素的hash值後2位必然是00,這些hash值可以根據後3位000或者100分成2類資料。他們分别&(8-1)即&111,則後3位為000的在桶0中,後3位為100的必然在桶4中。其他同理,也就是說桶4和桶0重新瓜分了原來桶0中的元素。
如果換成其他倍數,那麼瓜分就比較混亂了。
這樣在瓜分這些資料的時候,隻需要先把這些資料分類,如上述桶0中分成000和100 2類,然後直接構成新的連結清單,分類完畢後,直接将新的連結清單挂在對應的桶下即可,源碼如下:

上述 (e.hash & oldCap) == 0 即可将原桶中的資料分成2類
上述是對于連結清單情況下的重新移動,而針對紅黑樹情況下:
則需要考慮分類之後是否還需要依然保持紅黑樹,如果個數少則直接使用連結清單即可。
1.4 get過程
get過程比較簡單
-
- 如果要找的key就是上述數組index位置的元素,直接傳回該元素的值
- 如果該數組index位置元素是TreeNode類型,則按照紅黑樹的查詢方式來進行查找
- 如果該數組index位置元素非TreeNode類型,則按照連結清單的方式來進行周遊查詢
2 1.7的ConcurrentHashMap設計
ConcurrentHashMap是線程安全,通過分段鎖的方式提高了并發度。分段是一開始就确定的了,後期不能再進行擴容的。
其中的段Segment繼承了重入鎖ReentrantLock,有了鎖的功能,同時含有類似HashMap中的數組加連結清單結構(這裡沒有使用紅黑樹)
雖然Segment的個數是不能擴容的,但是單個Segment裡面的數組是可以擴容的。
2.1 整體概覽
ConcurrentHashMap有3個參數:
- initialCapacity:初始總容量,預設16
- loadFactor:加載因子,預設0.75
- concurrencyLevel:并發級别,預設16
然後我們需要知道的是:
-
segment的個數即ssize
取大于等于并發級别的最小的2的幂次。如concurrencyLevel=16,那麼sszie=16,如concurrencyLevel=10,那麼ssize=16
-
單個segment的初始容量cap
c=initialCapacity/ssize,并且可能需要+1。如15/7=2,那麼c要取3,如16/8=2,那麼c取2
c可能是一個任意值,那麼同上述一樣,cap取的值就是大于等于c的最下2的幂次。最小值要求是2
-
單個segment的門檻值threshold
cap*loadFactor
是以預設情況下,segment的個數sszie=16,每個segment的初始容量cap=2,單個segment的門檻值threshold=1
2.2 put過程
- 首先根據key計算出一個hash值,找到對應的Segment
- 調用Segment的lock方法,為後面的put操作加鎖
- 根據key計算出hash值,找到Segment中數組中對應index的連結清單,并将該資料放置到該連結清單中
- 判斷目前Segment包含元素的數量大于門檻值,則Segment進行擴容
整體代碼邏輯見如下源碼:
其中上述Segment的put過程源碼如下:
2.3 擴容過程
這個擴容是在Segment的鎖的保護下進行擴容的,不需要關注并發問題。
這裡的重點就是:
首先找到一個lastRun,lastRun之後的元素和lastRun是在同一個桶中,是以後面的不需要進行變動。
然後對開始到lastRun部分的元素,重新計算下設定到newTable中,每次都是将目前元素作為newTable的首元素,之前老的連結清單作為該首元素的next部分。
2.4 get過程
- 根據key計算出對應的segment
- 再根據key計算出對應segment中數組的index
- 最終周遊上述index位置的連結清單,查找出對應的key的value
3 1.8的ConcurrentHashMap設計
1.8的ConcurrentHashMap摒棄了1.7的segment設計,而是在1.8HashMap的基礎上實作了線程安全的版本,即也是采用數組+連結清單+紅黑樹的形式。
數組可以擴容,連結清單可以轉化為紅黑樹
3.1 整體概覽
有一個重要的參數sizeCtl,代表數組的大小(但是還有其他取值及其含義,後面再詳細說到)
使用者可以設定一個初始容量initialCapacity給ConcurrentHashMap
sizeCtl=大于(1.5倍initialCapacity+1)的最小的2的幂次。
即initialCapacity=20,則sizeCtl=32,如initialCapacity=24,則sizeCtl=64。
初始化的時候,會按照sizeCtl的大小建立出對應大小的數組
3.2 put過程
源碼如下所示:
- 如果數組還未初始化,那麼進行初始化,這裡會通過一個CAS操作将sizeCtl設定為-1,設定成功的,可以進行初始化操作
- 根據key的hash值找到對應的桶,如果桶還不存在,那麼通過一個CAS操作來設定桶的第一個元素,失敗的繼續執行下面的邏輯即向桶中插入或更新
- 如果找到的桶存在,但是桶中第一個元素的hash值是-1,說明此時該桶正在進行遷移操作,這一塊會在下面的擴容中詳細談及。
- 如果找到的桶存在,那麼要麼是連結清單結構要麼是紅黑樹結構,此時需要擷取該桶的鎖,在鎖定的情況下執行連結清單或者紅黑樹的插入或更新
- 如果桶中第一個元素的hash值大于0,說明是連結清單結構,則對連結清單插入或者更新
- 如果桶中的第一個元素類型是TreeBin,說明是紅黑樹結構,則按照紅黑樹的方式進行插入或者更新
- 在鎖的保護下插入或者更新完畢後,如果是連結清單結構,需要判斷連結清單中元素的數量是否超過8(預設),一旦超過就要考慮進行數組擴容或者是連結清單轉紅黑樹
下面就來重點看看這個擴容過程
3.3 擴容過程
一旦連結清單中的元素個數超過了8個,那麼可以執行數組擴容或者連結清單轉為紅黑樹,這裡依據的政策跟HashMap依據的政策是一緻的。
當數組長度還未達到64個時,優先數組的擴容,否則選擇連結清單轉為紅黑樹。
重點來看看這個擴容過程,即看下上述tryPresize方法,也可以看到上述是2倍擴容的方式
第一個執行的線程會首先設定sizeCtl屬性為一個負值,然後執行transfer(tab, null),其他晚進來的線程會檢查目前擴容是否已經完成,沒完成則幫助進行擴容,完成了則直接退出。
該ConcurrentHashMap的擴容操作可以允許多個線程并發執行,那麼就要處理好任務的配置設定工作。每個線程擷取一部分桶的遷移任務,如果目前線程的任務完成,檢視是否還有未遷移的桶,若有則繼續領取任務執行,若沒有則退出。在退出時需要檢查是否還有其他線程在參與遷移工作,如果有則自己什麼也不做直接退出,如果沒有了則執行最終的收尾工作。
-
問題1:目前線程如何感覺其他線程也在參與遷移工作?
靠sizeCtl的值,它初始值是一個負值=(rs << RESIZE_STAMP_SHIFT) + 2),每當一個線程參與進來執行遷移工作,則該值進行CAS自增,該線程的任務執行完畢要退出時對該值進行CAS自減操作,是以當sizeCtl的值等于上述初值則說明了此時未有其他線程還在執行遷移工作,可以去執行收尾工作了。見如下代碼
jdk1.8的HashMap和ConcurrentHashMap - 問題2:任務按照何規則進行分片? 上述stride即是每個分片的大小,目前有最低要求16,即每個分片至少需要16個桶。stride的計算依賴于CPU的核數,如果隻有1個核,那麼此時就不用分片,即stride=n。其他情況就是 (n >>> 3) / NCPU。
jdk1.8的HashMap和ConcurrentHashMap -
問題3:如何記錄目前已經分出去的任務?
ConcurrentHashMap含有一個屬性transferIndex(初值為最後一個桶),表示從transferIndex開始到後面所有的桶的遷移任務已經被配置設定出去了。是以每次線程領取擴容任務,則需要對該屬性進行CAS的減操作,即一般是transferIndex-stride。
-
問題4:每個線程如何處理分到的部分桶的遷移工作
第一個擷取到分片的線程會建立一個新的數組,容量是之前的2倍。
周遊自己所分到的桶:
-
桶中元素不存在,則通過CAS操作設定桶中第一個元素為ForwardingNode,其Hash值為MOVED(-1),同時該元素含有新的數組引用
此時若其他線程進行put操作,發現第一個元素的hash值為-1則代表正在進行擴容操作(并且表明該桶已經完成擴容操作了,可以直接在新的數組中重新進行hash和插入操作),該線程就可以去參與進去,或者沒有任務則不用參與,此時可以去直接操作新的數組了
- 桶中元素存在且hash值為-1,則說明該桶已經被處理了(本不會出現多個線程任務重疊的情況,這裡主要是該線程在執行完所有的任務後會再次進行檢查,再次核對)
- 桶中為連結清單或者紅黑樹結構,則需要擷取桶鎖,防止其他線程對該桶進行put操作,然後處理方式同HashMap的處理方式一樣,對桶中元素分為2類,分别代表目前桶中和要遷移到新桶中的元素。設定完畢後代表桶遷移工作已經完成,舊數組中該桶可以設定成ForwardingNode了
-
下面來看下詳細的代碼:
3.4 get過程
- 根據k計算出hash值,找到對應的數組index
- 如果該index位置無元素則直接傳回null
- 如果該index位置有元素
-
如果第一個元素的hash值小于0,則該節點可能為ForwardingNode或者紅黑樹節點TreeBin
如果是ForwardingNode(表示目前正在進行擴容),使用新的數組來進行查找
如果是紅黑樹節點TreeBin,使用紅黑樹的查找方式來進行查找
- 如果第一個元素的hash大于等于0,則為連結清單結構,依次周遊即可找到對應的元素
-
詳細代碼如下
至此,ConcurrentHashMap主要的操作都粗略的介紹完畢了,其他一些操作靠各位自行去看了。
下面針對一些問題來進行解答
4 問題分析
4.1 ConcurrentHashMap讀為什麼不需要鎖?
我們通常使用讀寫鎖來保護對一堆資料的讀寫操作。讀時加讀鎖,寫時加寫鎖。在什麼樣的情況下可以不需要讀鎖呢?
如果對資料的讀寫是一個原子操作,那麼此時是可以不需要讀鎖的。如ConcurrentHashMap對資料的讀寫,寫操作是不需要分2次寫的(沒有中間狀态),讀操作也是不需要2次讀取的。假如一個寫操作需要分多次寫,必然會有中間狀态,如果讀不加鎖,那麼可能就會讀到中間狀态,那就不對了。
假如ConcurrentHashMap提供put(key1,value1,key2,value2),寫入的時候必然會存在中間狀态即key1寫完成,但是key2還未寫,此時如果讀不加鎖,那麼就可能讀到key1是新資料而key2是老資料的中間狀态。
雖然ConcurrentHashMap的讀不需要鎖,但是需要保證能讀到最新資料,是以必須加volatile。即數組的引用需要加volatile,同時一個Node節點中的val和next屬性也必須要加volatile。
4.2 ConcurrentHashMap是否可以在無鎖的情況下進行遷移?
目前1.8的ConcurrentHashMap遷移是在鎖定舊桶的前提下進行遷移的,然而并沒有去鎖定新桶。那麼就可能提出如下問題:
-
在某個桶的遷移過程中,别的線程想要對該桶進行put操作怎麼辦?
一旦某個桶在遷移過程中了,必然要擷取該桶的鎖,是以其他線程的put操作要被阻塞,一旦遷移完畢,該桶中第一個元素就會被設定成ForwardingNode節點,是以其他線程put時需要重新判斷下桶中第一個元素是否被更改了,如果被改了重新擷取重新執行邏輯,如下代碼
jdk1.8的HashMap和ConcurrentHashMap -
某個桶已經遷移完成(其他桶還未完成),别的線程想要對該桶進行put操作怎麼辦?
該線程會首先檢查是否還有未配置設定的遷移任務,如果有則先去執行遷移任務,如果沒有即全部任務已經分發出去了,那麼此時該線程可以直接對新的桶進行插入操作(映射到的新桶必然已經完成了遷移,是以可以放心執行操作)
從上面看到我們在遷移的時候還是需要對舊桶鎖定的,能否在無鎖的情況下實作遷移?
可以參考參考這篇論文Split-Ordered Lists: Lock-Free Extensible Hash Tables
一旦擴容就涉及到遷移桶中元素的操作,将一個桶中的元素遷移到另一個桶中的操作不是一個原子操作,是以需要在鎖的保護下進行遷移。如果擴容操作是移動桶的指向,那麼就可以通過一個CAS操作來完成擴容操作。上述Split-Ordered Lists就是把所有元素按照一定的順序進行排列。該list被分成一段一段的,每一段都代表某個桶中的所有元素。每個桶中都有一個指向第一個元素的指針,如下圖結構所示:
每一段其實也是分成2類的,如同前面所說的HashMap在擴容是分成2類的情況是一樣的,此時Split-Ordered Lists在擴容時就隻需要将新桶的指針指向這2類的分界點即可。
這一塊之後再詳細說明吧。
4.3 ConcurrentHashMap曾經的弱一緻性
具體詳見這篇針對老版本的ConcurrentHashMap的說明文章為什麼ConcurrentHashMap是弱一緻的
文中已經解釋到:對數組的引用是volatile來修飾的,但是數組中的元素并不是。即讀取數組的引用總是能讀取到最新的值,但是讀取數組中某一個元素的時候并不一定能讀到最新的值。是以說是弱一緻性的。
我覺得這個隻需要稍微改動下就可以實作強一緻性:
- 對于新加的key,通過寫入到連結清單的末尾即可。因為一個元素的next屬性是volatile的,可以保證寫入後立馬看的到,如下1.8的方式
- 或者對數組中元素的更新采用volatile寫的方式,如下1.7的形式
但是現在1.7版本的ConcurrentHashMap對于數組中元素的寫也是加了volatile的,如下代碼
1.8的方式就是:直接将新加入的元素寫入next屬性(含有volatile修飾)中而不是修改桶中的第一個元素。
是以在1.7和1.8版本的ConcurrentHashMap中不再是弱一緻性,寫入的資料是可以立馬本讀到的。
5 結束語
本篇文章因為涉及的話題衆多,難免有疏漏之處,還請指出糾正。更多的問題可以加群讨論,詳見這篇加群說明文章加群指南
歡迎繼續來讨論,越辯越清晰。
歡迎關注微信公衆号:乒乓狂魔
上面是原文作者的公衆号
如有侵權,留言删除