提取異常日志是個大難題
面對海量的日志(TB乃至PB級别),如何從日志中挖掘出異常資訊對于大部分的開發者而言是一個大難題。例如,判斷機器的延時是否正常,部分request是否正常。通常,我們對于異常的資料,要及時的報警,以盡快的處理。
通常我們是怎麼搞得呢? 在以前,依賴于開發者的經驗,來根據某些特定的特征,判斷是否達到了門檻值,例如根據延時是否達到了某個特定的值,或者http 響應碼5xx的比例達到了某個門檻值。這個門檻值,依賴于資深的開發者的豐富的經驗。
AI dev/ops
AI算法的迅猛發展,給異常日志挖掘提供了新的方向。大名鼎鼎的AI領域專家吳恩達(Andrew NG),在他所教授的Machine Learning課程中提供了一種Abnormal Detection算法。算法通過訓練資料集,獲得一個正态分布。然後檢測目标資料是否落在了正态分布的邊緣位置,如果落在了邊緣位置,則認為是一個異常資料。
算法步驟:
- 确定要訓練的feature,可以是單個名額,比如latency,也可以是複合名額,例如CPU/NetFlow
- 在訓練資料集上,求得均值μ和方差σ^2
- 對新資料求方程P(x)=
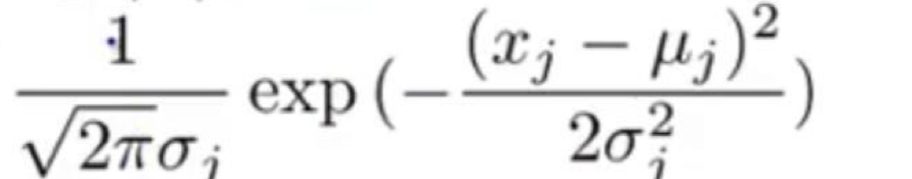
SQL老司機,居然是這樣智能挖掘異常日志
接下來,我們介紹如何在SQL中使用該算法來檢測異常。
日志服務提供的異常檢測算法
以延時為例,我們來看哪些延時是異常的。 延時的分布一般是這樣的:
不滿足正太的需求,要把上述圖形轉化成正太分布,對latency 求對數:log(latency)

- 值μ和方差σ^2:
* | select numeric_histogram(10,latency), stddev_pop(ln(latency)) as stddev,var_pop(ln(latency)) as variance ,avg(ln(latency)) as avg_ln, avg(latency) as avglatency stddev即标準差
variance即方差
avg_ln即ln(latency)的均值
avglatency即latency的均值
- 提取異常資料
| select latency where pow(e(), - pow((ln(latency) - 8.223) ,2)/2/0.3975) /sqrt(2*pi()) / 0.53 < 0.01 order by latency desc 把方差标準差和均值帶入公式,使用where篩選出來小于0.01的結果,即異常值。可以看到,獲得的結果,明顯大于軍latency的均值。