本文部分摘自《深入了解 Java 虛拟機第三版》
如果說收集算法是記憶體回收的方法論,那麼垃圾收集器就是記憶體回收的實踐者。Java 虛拟機規範中對垃圾收集器的實作做出規定,是以不同的廠商、不同版本的虛拟機所包含的垃圾收集器各有不同。所謂經典就是在 JDK7 Update 4 以後,JDK11 釋出以前的在 OpenJDK HotSpot 虛拟機所包含的全部可用的垃圾收集器。盡管這些經典垃圾收集器已算不上最先進的技術,但它們都經曆了千錘百煉,基本上都是可以放心使用的垃圾收集器。各款經典垃圾收集器之間的關系如圖所示,如果兩個收集器之間存在連線,就說明它們可以搭配使用:
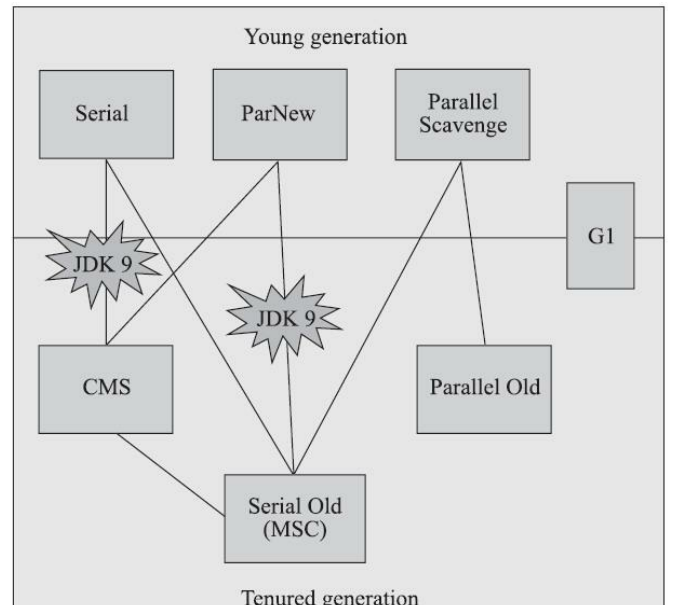
Serial 收集器是最基礎、曆史最悠久的收集器,在 JDK3 以前是 HotSpot 虛拟機新生代收集器的唯一選擇。這個收集器是一個單線程工作的收集器。這裡的單線程不僅僅是說明它隻使用一條收集線程去完成垃圾收集工作,更強調的是它在進行垃圾收集時,必須暫停其他所有工作線程,直至收集結束,也即“Stop The World”。這項工作是由虛拟機在背景自動發起和完成的,使用者完全不可知,也不可控,顯然這令人難以接受

但 Serial 收集器也有自己的優勢,那就是簡單與高效(與其他收集器的單線程相比)。對于記憶體有限的環境,它是所有收集器裡額外記憶體消耗最小的;對于單核處理器或處理器核心數較少的環境,Serial 收集器由于沒有線程互動的開銷,可以專心做垃圾收集,自然可以獲得最高的單線程收集效率。在使用者桌面應用場景以及近年來流行的部分微服務應用,配置設定給虛拟機管理的記憶體一般不會太大,垃圾收集的停頓時間完全可以控制在毫秒級别,這點停頓時間對于使用者來說完全可以接受。是以,Serial 收集器對于運作在用戶端模式下的虛拟機是一個不錯的選擇
ParNew 收集器實質上是 Serial 收集器的多線程并行版本,除了同時使用多條線程進行垃圾收集之外,其餘的行為包括 Serial 收集器可用的所有控制參數、收集算法、Stop The World、對象配置設定規則、回收政策等都與 Serial 收集器完全一緻,在實作上這兩種收集器也共用了許多代碼
ParNew 收集器除了支援多線程并行收集外,其餘與 Serial 收集器并無太多創新,但它卻是不少運作在服務端的 HotSpot 虛拟機,尤其是 JDK7 之前的遺留系統首選的新生代收集器,其中最重要的原因是:除了 Serial 收集器,目前隻有它能與 CMS 收集器配合工作。CMS 收集器是 HotSpot 虛拟機中第一款真正意義上支援并發的垃圾收集器,它首次實作了讓垃圾收集器線程與使用者線程(基本上)同時工作。不過由于 JDK9 以後 CMS 逐漸被 G1 所代替,ParNew 也漸漸退出了曆史舞台
ParNew 收集器由于存線上程互動開銷,當處于單核心處理器環境中時并不會有比 Serial 收集器更好的效果。不過,随着可以被使用的處理器核心數的增加,ParNew 對于垃圾收集時系統資源的高效利用還是很有好處的
Parallel Scavenge 收集器也是一款新生代收集器,它同樣是基于标記 - 複制算法實作的收集器,也是能夠并行收集的多線程收集器。不同于 CMS 等收集器的關注點是盡可能地縮短垃圾收集時使用者線程的停頓時間,Parallel Scavenge 收集器的目标是達到一個控制的吞吐量。所謂吞吐量就是處理器用于運作使用者代碼的時間與處理器總消耗時間的比值,即:吞吐量 = 運作使用者代碼時間 / (運作使用者代碼時間 + 運作垃圾收集時間)
停頓時間越短,越适合需要與使用者互動或需要保證服務響應品質的程式,提升使用者體驗;而高吞吐量則可以最高效率低利用處理器資源,盡快完成程式的運算任務。Parallel Scavenge 收集器提供了兩個參數用于精确控制吞吐量,分别是控制最大垃圾收集停頓時間的 -XX:MaxGCPauseMillis 參數以及直接設定吞吐量大小的 -XX:GCTimeRatio 參數
除上述兩個參數,Parallel Scavenge 收集器還有一個參數 -XX:UseAdaptiveSizePolicy,這是一個開關參數,當這個參數被激活後,就不需要人工指定新生代的大小(-Xmn)、Eden 與 Survivor 區的比例(-XX:SurvivorRatio)、晉升老年代對象大小(-XX:PretenureSizeThreshold)等細節參數了,虛拟機會根據目前系統的運作情況收集性能監控資訊,動态調整這些參數以提供最合适的停頓時間或最大1吞吐量,這種調節方式稱為垃圾收集的自适應調節政策
Serial Old 收集器是 Serial 收集器的老年代版本,同樣是一個單線程收集器,使用标記 - 整理算法。這個收集器的主要供用戶端模式下的 HotSpot 虛拟機使用。如果用在服務端模式,可能有兩種用途:一種是在 JDK5 及之前的版本中與 Parallel Scavenge 收集器搭配使用,另一種就是作為 CMS 收集器發生失敗時的後備預案。Serial Old 收集器的工作過程如圖所示:
Parallel Old 是 Parallel Scavenge 收集器的老年代版本,支援多線程并發收集,基于标記 - 整理算法實作。這個收集器直到 JDK6 時才開始提供,在此之前,新生代的 Parallel Scavenge 收集器一直處于相當尴尬的狀态,因為如果新生代選擇了 Parallel Scavenge 收集器,那麼老年代除了 Serial Old 收集器以外就别無選擇,效率不高。直到 Parallel Old 收集器的出現,吞吐量優先收集器終于有了比較名副其實的搭配組合。Parallel Old 收集器的工作過程如圖所示: