作業系統的主要功能是為管理硬體資源和為應用程式開發人員提供良好的環境,但是計算機系統的各種硬體資源是有限的,是以為了保證每一個程序都能安全的執行。處理器設有兩種模式:“使用者模式”與“核心模式”。一些容易發生安全問題的操作都被限制在隻有核心模式下才可以執行,例如I/O操作,修改基址寄存器内容等。而連接配接使用者模式和核心模式的接口稱之為系統調用。
應用程式代碼運作在使用者模式下,當應用程式需要實作核心模式下的指令時,先向作業系統發送調用請求。作業系統收到請求後,執行系統調用接口,使處理器進入核心模式。當處理器處理完系統調用操作後,作業系統會讓處理器傳回使用者模式,繼續執行使用者代碼。
程序的虛拟位址空間可分為兩部分,核心空間和使用者空間。核心空間中存放的是核心代碼和資料,而程序的使用者空間中存放的是使用者程式的代碼和資料。不管是核心空間還是使用者空間,它們都處于虛拟空間中,都是對實體位址的映射。
應用程式中實作對檔案的操作過程就是典型的系統調用過程。
一個作業系統可以支援多種底層不同的檔案系統(比如NTFS, FAT, ext3, ext4),為了給核心和使用者程序提供統一的檔案系統視圖,Linux在使用者程序和底層檔案系統之間加入了一個抽象層,即虛拟檔案系統(Virtual File System, VFS),程序所有的檔案操作都通過VFS,由VFS來适配各種底層不同的檔案系統,完成實際的檔案操作。
通俗的說,VFS就是定義了一個通用檔案系統的接口層和适配層,一方面為使用者程序提供了一組統一的通路檔案,目錄和其他對象的統一方法,另一方面又要和不同的底層檔案系統進行适配。如圖所示:
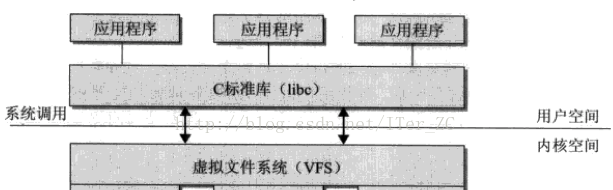
虛拟檔案系統主要子產品
1、超級塊(super_block),用于儲存一個檔案系統的所有中繼資料,相當于這個檔案系統的資訊庫,為其他的子產品提供資訊。是以一個超級塊可代表一個檔案系統。檔案系統的任意中繼資料修改都要修改超級塊。超級塊對象是常駐記憶體并被緩存的。
2、目錄項子產品,管理路徑的目錄項。比如一個路徑 /home/foo/hello.txt,那麼目錄項有home, foo, hello.txt。目錄項的塊,存儲的是這個目錄下的所有的檔案的inode号和檔案名等資訊。其内部是樹形結構,作業系統檢索一個檔案,都是從根目錄開始,按層次解析路徑中的所有目錄,直到定位到檔案。
3、inode子產品,管理一個具體的檔案,是檔案的唯一辨別,一個檔案對應一個inode。通過inode可以友善的找到檔案在磁盤扇區的位置。同時inode子產品可連結到address_space子產品,友善查找自身檔案資料是否已經緩存。
4、打開檔案清單子產品,包含所有核心已經打開的檔案。已經打開的檔案對象由open系統調用在核心中建立,也叫檔案句柄。打開檔案清單子產品中包含一個清單,每個清單表項是一個結構體struct file,結構體中的資訊用來表示打開的一個檔案的各種狀态參數。
5、file_operations子產品。這個子產品中維護一個資料結構,是一系列函數指針的集合,其中包含所有可以使用的系統調用函數,例如open、read、write、mmap等。每個打開檔案(打開檔案清單子產品的一個表項)都可以連接配接到file_operations子產品,進而對任何已打開的檔案,通過系統調用函數,實作各種操作。
6、address_space子產品,它表示一個檔案在頁緩存中已經緩存了的實體頁。它是頁緩存和外部裝置中檔案系統的橋梁。如果将檔案系統可以了解成資料源,那麼address_space可以說關聯了記憶體系統和檔案系統。我們會在文章後面繼續讨論。
子產品間的互相作用和邏輯關系如下圖所示:

由圖可以看出:
1、每個子產品都維護了一個X_op指針指向它所對應的操作對象X_operations。
2、超級塊維護了一個s_files指針指向了“已打開檔案清單子產品”,即核心所有的打開檔案的連結清單,這個連結清單資訊是所有程序共享的。
3、目錄操作子產品和inode子產品都維護了一個X_sb指針指向超級塊,進而可以獲得整個檔案系統的中繼資料資訊。
4、 目錄項對象和inode對象各自維護了指向對方的指針,可以找到對方的資料。
5、已打開檔案清單上每一個file結構體執行個體維護了一個f_dentry指針,指向了它對應的目錄項,進而可以根據目錄項找到它對應的inode資訊。
6、已打開檔案清單上每一個file結構體執行個體維護了一個f_op指針,指向可以對這個檔案進行操作的所有函數集合file_operations。
7、inode中不僅有和其他子產品關聯的指針,重要的是它可以指向address_space子產品,進而獲得自身檔案在記憶體中的緩存資訊。
8、address_space内部維護了一個樹結構來指向所有的實體頁結構page,同時維護了一個host指針指向inode來獲得檔案的中繼資料。
程序和虛拟檔案系統互動
1、核心使用task_struct來表示單個程序的描述符,其中包含維護一個程序的所有資訊。task_struct結構體中維護了一個 files的指針(和“已打開檔案清單”上的表項是不同的指針)來指向結構體files_struct,files_struct中包含檔案描述符表和打開的檔案對象資訊。
2、file_struct中的檔案描述符表實際是一個file類型的指針清單(和“已打開檔案清單”上的表項是相同的指針),可以支援動态擴充,每一個指針指向虛拟檔案系統中檔案清單子產品的某一個已打開的檔案。
3、file結構一方面可從f_dentry連結到目錄項子產品以及inode子產品,擷取所有和檔案相關的資訊,另一方面連結file_operations子子產品,其中包含所有可以使用的系統調用函數,進而最終完成對檔案的操作。這樣,從程序到程序的檔案描述符表,再關聯到已打開檔案清單上對應的檔案結構,進而調用其可執行的系統調用函數,實作對檔案的各種操作。
程序 vs 檔案清單 vs Inode
1、多個程序可以同時指向一個打開檔案對象(檔案清單表項),例如父程序和子程序間共享檔案對象;
2、一個程序可以多次打開一個檔案,生成不同的檔案描述符,每個檔案描述符指向不同的檔案清單表項。但是由于是同一個檔案,inode唯一,是以這些檔案清單表項都指向同一個inode。通過這樣的方法實作檔案共享(共享同一個磁盤檔案);
概念
如高速緩存(cache)産生的原理類似,在I/O過程中,讀取磁盤的速度相對記憶體讀取速度要慢的多。是以為了能夠加快處理資料的速度,需要将讀取過的資料緩存在記憶體裡。而這些緩存在記憶體裡的資料就是高速緩沖區(buffer cache),下面簡稱為“buffer”。
具體來說,buffer(緩沖區)是一個用于存儲速度不同步的裝置或優先級不同的裝置之間傳輸資料的區域。一方面,通過緩沖區,可以使程序之間的互相等待變少,進而使從速度慢的裝置讀入資料時,速度快的裝置的操作程序不發生間斷。另一方面,可以保護硬碟或減少網絡傳輸的次數。
Buffer和Cache
buffer和cache是兩個不同的概念:cache是高速緩存,用于CPU和記憶體之間的緩沖;buffer是I/O緩存,用于記憶體和硬碟的緩沖;簡單的說,cache是加速“讀”,而buffer是緩沖“寫”,前者解決讀的問題,儲存從磁盤上讀出的資料,後者是解決寫的問題,儲存即将要寫入到磁盤上的資料。
Buffer Cache和 Page Cache
buffer cache和page cache都是為了處理裝置和記憶體互動時高速通路的問題。buffer cache可稱為塊緩沖器,page cache可稱為頁緩沖器。在linux不支援虛拟記憶體機制之前,還沒有頁的概念,是以緩沖區以塊為機關對裝置進行。在linux采用虛拟記憶體的機制來管理記憶體後,頁是虛拟記憶體管理的最小機關,開始采用頁緩沖的機制來緩沖記憶體。Linux2.6之後核心将這兩個緩存整合,頁和塊可以互相映射,同時,頁緩存page cache面向的是虛拟記憶體,塊I/O緩存Buffer cache是面向塊裝置。需要強調的是,頁緩存和塊緩存對程序來說就是一個存儲系統,程序不需要關注底層的裝置的讀寫。
buffer cache和page cache兩者最大的差別是緩存的粒度。buffer cache面向的是檔案系統的塊。而核心的記憶體管理元件采用了比檔案系統的塊更進階别的抽象:頁page,其處理的性能更高。是以和記憶體管理互動的緩存元件,都使用頁緩存。
頁緩存是面向檔案,面向記憶體的。通俗來說,它位于記憶體和檔案之間緩沖區,檔案IO操作實際上隻和page cache互動,不直接和記憶體互動。page cache可以用在所有以檔案為單元的場景下,比如網絡檔案系統等等。page cache通過一系列的資料結構,比如inode, address_space, struct page,實作将一個檔案映射到頁的級别:
1、struct page結構标志一個實體記憶體頁,通過page + offset就可以将此頁幀定位到一個檔案中的具體位置。同時struct page還有以下重要參數:
(1)标志位flags來記錄該頁是否是髒頁,是否正在被寫回等等;
(2)mapping指向了位址空間address_space,表示這個頁是一個頁緩存中頁,和一個檔案的位址空間對應;
(3)index記錄這個頁在檔案中的頁偏移量;
2、檔案系統的inode實際維護了這個檔案所有的塊block的塊号,通過對檔案偏移量offset取模可以很快定位到這個偏移量所在的檔案系統的塊号,磁盤的扇區号。同樣,通過對檔案偏移量offset進行取模可以計算出偏移量所在的頁的偏移量。
3、page cache緩存元件抽象了位址空間address_space這個概念來作為檔案系統和頁緩存的中間橋梁。位址空間address_space通過指針可以友善的擷取檔案inode和struct page的資訊,是以可以很友善地定位到一個檔案的offset在各個元件中的位置,即通過:檔案位元組偏移量 --> 頁偏移量 --> 檔案系統塊号 block --> 磁盤扇區号
4、頁緩存實際上就是采用了一個基數樹結構将一個檔案的内容組織起來存放在實體記憶體struct page中。一個檔案inode對應一個位址空間address_space。而一個address_space對應一個頁緩存基數樹。它們之間的關系如下:
下面我們總結已經讨論過的address_space所有功能。address_space是Linux核心中的一個關鍵抽象,它被作為檔案系統和頁緩存的中間擴充卡,用來訓示一個檔案在頁緩存中已經緩存了的實體頁。是以,它是頁緩存和外部裝置中檔案系統的橋梁。如果将檔案系統可以了解成資料源,那麼address_space可以說關聯了記憶體系統和檔案系統。
由圖中可以看到,位址空間address_space連結到頁緩存基數樹和inode,是以address_space通過指針可以友善的擷取檔案inode和page的資訊。那麼頁緩存是如何通過address_space實作緩沖區功能的?我們再來看完整的檔案讀寫流程。
讀檔案
1、程序調用庫函數向核心發起讀檔案請求;
2、核心通過檢查程序的檔案描述符定位到虛拟檔案系統的已打開檔案清單表項;
3、調用該檔案可用的系統調用函數read()
3、read()函數通過檔案表項連結到目錄項子產品,根據傳入的檔案路徑,在目錄項子產品中檢索,找到該檔案的inode;
4、在inode中,通過檔案内容偏移量計算出要讀取的頁;
5、通過inode找到檔案對應的address_space;
6、在address_space中通路該檔案的頁緩存樹,查找對應的頁緩存結點:
(1)如果頁緩存命中,那麼直接傳回檔案内容;
(2)如果頁緩存缺失,那麼産生一個頁缺失異常,建立一個頁緩存頁,同時通過inode找到檔案該頁的磁盤位址,讀取相應的頁填充該緩存頁;重新進行第6步查找頁緩存;
7、檔案内容讀取成功。
寫檔案
前5步和讀檔案一緻,在address_space中查詢對應頁的頁緩存是否存在:
6、如果頁緩存命中,直接把檔案内容修改更新在頁緩存的頁中。寫檔案就結束了。這時候檔案修改位于頁緩存,并沒有寫回到磁盤檔案中去。
7、如果頁緩存缺失,那麼産生一個頁缺失異常,建立一個頁緩存頁,同時通過inode找到檔案該頁的磁盤位址,讀取相應的頁填充該緩存頁。此時緩存頁命中,進行第6步。
8、一個頁緩存中的頁如果被修改,那麼會被标記成髒頁。髒頁需要寫回到磁盤中的檔案塊。有兩種方式可以把髒頁寫回磁盤:
(1)手動調用sync()或者fsync()系統調用把髒頁寫回
(2)pdflush程序會定時把髒頁寫回到磁盤
同時注意,髒頁不能被置換出記憶體,如果髒頁正在被寫回,那麼會被設定寫回标記,這時候該頁就被上鎖,其他寫請求被阻塞直到鎖釋放。