摘要:基于資料湖架構,應用效率得以極大提升。經過幾年發展,目前叢集規模已經達到1000多節點,資料量幾十PB,日均處理作業數大概是10萬,賦能于180多個總行應用和境内外41家分行及子公司。
本文分享自華為雲社群《FusionInsight怎麼幫「宇宙行」建一個好的「雲資料平台」?》,作者:徐禮鋒 。
大資料從2010年開始到現在各種新技術層出不窮,最近圍繞雲基礎設施又有非常多的創新發展。
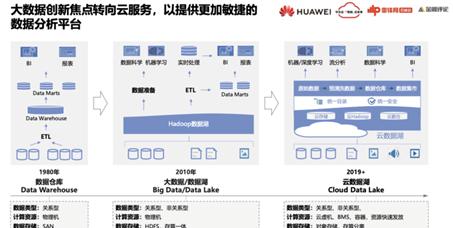
很多企業早期的資料分析系統主要建構在資料倉庫之上,有的甚至連資料倉庫都沒有,使用TP類關系型資料庫直接對接BI系統實作。這類系統一般以實體機形态的一體機部署,分布式能力比較弱,随着資料規模巨大增長,尤其是移動網際網路發展,傳統資料庫難以支撐這種大體量的資料分析需求。
在這個背景下,Hadoop技術應運而生并飛速發展,有效地解決了大資料量的分析和處理需求。Hadoop最開始的應用多用于日志類非關系型的資料處理,主要基于MapReduce程式設計模型,随着SQL on Hadoop的發展,關系型資料的處理能力也越來越強。
早期的Hadoop主要基于實體機部署,一直到現在仍然是最成熟的部署模式。雖然Hadoop計算與存儲之間是解耦的,但是絕大部分實踐都還是會把計算與存儲進行一體化部署,Hadoop排程系統會把計算調到資料所在位置上進行就近計算,就近計算大大提高了系統的處理能力,後期Spark、flink等都繼承了這種架構優勢。
自從亞馬遜推出雲IT基礎設施以來,越來越多的企業都将自己的IT業務遷移到雲上,是以,在雲上開展大資料業務順理成章。基本上所有的雲廠家也都提供雲上大資料解決方案。
那麼,在雲上部署大資料與原來基于實體機的on premise部署方式又有哪些不同呢?
首先,盡量利用雲的計算資源,包括雲虛機、容器以滿足資源的快速發放,包括裸金屬服務BMS以提供近似實體機的高性能處理計算資源。
其次,各雲廠商都推出存算分離的大資料架構,亞馬遜是最早實作對象存儲替代HDFS,因為對象存儲相對HDFS三副本成本相對較低。計算與存儲分離之後帶來了很多好處,但是也面臨着諸多挑戰。這個方向一直在不斷地完善,目前,雲上大資料存算分離已經發展的比較成熟。

Lakehouse是最近非常熱的一個大資料概念。2020年1月份databricks發表的一篇部落格中首次提到Lakehouse這個概念。之後,在今年的1月份再次發表一篇論文,系統闡述如何建構Lakehouse。
很多資料分析系統都建構在資料倉庫、資料湖的基礎上,有些将兩者結合形成如圖的兩層架構,大型企業後面這種形式更多。這種資料湖、資料倉庫的兩層架構到底存在哪些問題呢?
可以看到,資料湖和數倉的很多資料是雷同的,這樣就會導緻以下三個問題:
第一,資料要存儲兩份,相應的存儲成本翻倍。
第二,資料湖和數倉的資料存兩份,就需要維護資料的一緻性,這個過程主要通過ETL來保證,維護代價比較高,而且往往很難保持一緻,可靠性不是很高。
第三,資料的時效性。資料湖将大批量的資料內建起來并不容易。由于資料湖大多基于Hive來管理,而其底層HDFS存儲并不支援修改,是以資料僅支援追加的模式來內建。而業務生産系統的資料變化不是隻有追加的資料,還有很多更新的操作,如果要對資料湖的資料進行更新,就需要按分區先合并後重寫。這樣就增加了資料合并處理的難度,更多的時候隻能通過一天合并一次的T+1的模式,T+1的模式也就意味着大部分資料對後端應用的可見性差了一天,目前看到的資料實際上是昨天的,意味着數倉裡面的資料始終并不新鮮。
LakeHouse就是期望解決資料湖與數倉的融合分析的問題。LakeHouse提出通過提供ACID的開放格式存儲引擎來解決資料的時效性問題,開放格式另一個好處在于資料湖裡的資料可以面向多種分析引擎,如Hive、Spark、Flink等都可以對資料進行通路分析,而且AI引擎也可以通路Lakehouse資料做進階分析。
對于諸如Hudi、Iceberg、DeltaLake增量資料管理架構,由于其提供了ACID的能力,資料可以進行更新操作以及并發讀寫,是以對存儲資料存儲要求也更高,比如需要支援時間旅行、零拷貝等能力,才能保證資料随時可以回溯。
Lakehouse除了支撐傳統的BI以及報表類的應用,還要支援進階的AI類的分析,資料分析師、資料科學家可以直接在Lakehouse進行資料科學計算和機器學習。
另外,Lakehouse的最佳實踐是基于存算分離架構來建構。存算分離最大的問題在于網絡,各雲廠家以及大資料廠家,都探索了很多的手段來解決雲存儲本身通路的性能問題,如提供本地緩存功能來提高資料處理的效率。
Lakehouse架構可以實作離線與實時的融合統一,資料通過ACID入湖。
如圖所示是經典的大資料的Lampda架構,藍色的處理流是批處理,紅色的則是流處理,在應用層形成實時合并視圖。這個架構存在的問題就是批處理和流處理是割裂的,資料管理之間的協同比較麻煩,而且不同的開發工具對開發要求的能力不同,對系統維護工程師和資料開發人員都是較大的挑戰。
針對這種的情況,Lakehouse架構可以将批處理和流處理合并成一個Lakehouse view,通過CDC把業務生産系統資料實時抽取到資料湖,實時加工後送到後端OLAP的系統中對外開放,這個過程可以做到端到端的分鐘級時延。
Lakehouse本身的概念比較新,大家都還在做着各種各樣的實踐以進行完善。
工行早期主要以Oracle 、Teradata建構其資料系統。數倉為Teradata,資料集市是Oracle Exadata。
2013年開始,我們在工行上線了銀行業第一個大資料平台,當時的大資料平台以單一的應用為主,例如一些日志分析、TD的新業務解除安裝和明細查詢。
2015年之後,對資料系統進行整合合并,包括通過GaussDB替代Teradata數倉,形成了融合數倉,在工行被稱之為一湖兩庫,以FusionInsight建構資料湖底座以支援全量的資料加工,同時實時分析、互動式分析等業務也在其中得以開展。
2020年初,開始建構雲資料平台,将整個資料湖遷移到雲上以實作大資料的雲化和服務化,同時建構存算分離的架構。另外還引入AI技術。
工行的技術演進方向是從單一走向多元、從集中式走向分布式、從孤立系統走向融合、從傳統IT走向雲原生的過程。
第一代大資料平台更多的是根據應用需求按需建設,這個時期對Hadoop究竟能解決什麼問題并沒有很深的認知。
首先想到的是解決業務創新,以及在數倉裡做不出來的業務,比如把大批量的資料合并作業解除安裝到Hadoop系統裡。
這個時期缺少系統規劃,導緻單叢集規模小,叢集數量不斷增多,維護成本較高,資源使用率低。另外,很多資料是需要在多個業務間共享的,需要在叢集間進行拷貝遷移,大量備援的資料增加了資源的消耗。同時,資料需要根據不同的場景存儲在不同的技術元件中,利用不同的技術元件進行處理,也導緻ETL鍊路較長、開發效率低,維護的代價高。是以,需要對整個大資料平台的架構進行優化。
第二階段将多個大資料叢集進行了合并,形成資料湖,其特點在于資料處理層統一規劃,集中入湖、集中管理。使得整體的管理、維護、開發效率得到極大提升。
将原始資料入湖之後,還會對資料進行一些加工處理以形成彙總資料和主題資料,并在資料湖裡進行集中治理,資料加工處理後送到數倉或者資料集市,以及後端的其他系統裡。
基于這種架構,資料湖的應用效率得以極大提升。經過幾年發展,目前叢集規模已經達到1000多節點,資料量幾十PB,日均處理作業數大概是10萬,賦能于180多個總行應用和境内外41家分行及子公司。
但是,将所有資料存進一個集中的資料湖也帶來了很多管理方面的難題。
資料湖支撐的業務和使用者對SLA高低的要求不盡相同,如何給不同部門、不同業務線、以及不同使用者的作業進行統一管理比較關鍵,核心是多租戶能力,Hadoop社群YARN排程功能早期并不是很強,上千個節點的管理能力較弱,雖然現在的新版本得以改進。
早期的叢集到幾百個節點後,排程管理系統就難以支撐。是以我們開發了 Superior的排程器加以完善。工行的1000節點叢集在銀行業算是比較大的數量級。我們在華為内部建構了從500到幾千直到10000節點的一個叢集,這個過程已經對大叢集的管理能力提前進行鋪墊,在工行的應用就相對比較順利。
如圖所示,我們把整個的資源管理按照部門多級資源池進行管理,通過superior排程器,按照不同的政策進行排程以支撐不同的SLA。整體效果而言,資源使用率得以成倍提升。
還有一些其它元件,尤其是像HBase的region server是基于JAVA的JVM來管理記憶體,能利用的記憶體很有限,實體機資源基本用不滿,資源不能充分利用。
為了解決這個問題,我們實作在一個實體機上可以部署多執行個體,盡量将一個實體機的資源充分利用,ES也是按照這種方式來處理。
叢集變大之後,其可用性和可靠性也存在着很大的問題。大叢集一旦出現問題導緻全面癱瘓,對業務影響非常大。是以,銀行業必須全面具備兩地三中心的可靠性。
首先是跨AZ部署的能力,AZ實際是屬于雲上的一個概念,傳統的 ICT機房裡更多的是跨DC資料中心的概念,跨AZ部署意味着一個叢集可以跨兩個AZ或者三個AZ進行部署。
Hadoop本身具備多副本機制,以多副本機制為基礎,可以将多個副本放置在不同的機房裡。但是以上條件并非開源能力可以支撐,需要補充一些副本放置和排程的政策,在排程時要感覺資料究竟放置在哪個AZ,任務排程到相應的AZ保證資料就近處理,盡量避免AZ之間由于資料傳輸帶來的網絡IO。
另外,容災能力還可以通過異地主備來實作,跨AZ能力要求機房之間的網絡時延達到毫秒級,時延太高可能無法保證很多業務的開展。異地的容災備份,即一個主叢集和一個備叢集。平時,備叢集并不承擔業務,僅主叢集承載業務,一旦主叢集發生故障,備叢集随之進行接管,但是相應的代價也會較大,比如有1000個節點的主叢集,就要建構1000個節點的備叢集,是以多數情況下,主備容災更多的是僅建構關鍵資料關鍵業務的備份,并非将其全部做成主備容載。
大資料叢集需要不斷擴容,随着時間的推移,硬體會更新換代,更新換代之後必然出現兩種情況,其中之一就是新采購機器的CPU和記憶體能力,以及磁盤的容量,都比原來增大或者升高了,需要考慮如何在不同的跨代硬體上實作資料均衡。
換盤的操作也會導緻磁盤的不均衡,如何解決資料均衡是一個很重要的課題。
我們專門開發了按照可用空間放置資料的能力,保證了資料是按照磁盤以及節點的可用空間進行放置。同時,對跨代節點按規格進行資源池劃分,對于早期比較老舊且性能相對差一些的裝置,可以組成一個邏輯資源池用于跑Hive作業,而記憶體多的新裝置組成另一個資源池則用來跑spark,資源池通過資源标簽進行區分隔離,分别排程。
叢集變大之後,任何變更導緻業務中斷的影響都非常大。是以,更新操作、更新檔操作都需要考慮如何保證業務不會中斷。
比如對1000個節點內建進行一次版本更新。如果整體停機更新,整個過程至少需要花費12個小時。
滾動更新的政策可實作叢集節點一個一個滾動分時更新,逐漸将所有節點全部更新成最新的版本。但是開源的社群跨大版本并不保證接口的相容性,會導緻新老版本無法更新。是以我們研發了很多的能力以保證所有版本之間都能滾動更新。從最早的Hadoop版本一直到Hadoop3,所有的元件我們都能保證滾動更新。這也是大叢集的必備能力。
資料湖的建構解決了工行的資料管理的難題,但同時也面臨着很多新的挑戰和問題。
一般而言,很多大企業的硬體都是集中采購,并沒有考慮到大資料不同場景對資源訴求的不一,而且計算與存儲的配比并未達到很好的均衡,存在較大的浪費。
其次,不同批次的硬體之間也存在差異,有些可能還會使用不同的作業系統版本,導緻了一個叢集内有不同的硬體、不同的作業系統版本。雖然可以用技術手段解決硬體異構、OS異構的問題,但是持續維護的代價相當高。
再次,大資料手工部署效率低。往往開展一個新業務的時候,從硬體的采購到網絡配置、再到作業系統安裝,整個系統傳遞周期至少需要一個月。
最後,資源彈性不足,如果上新業務時面臨資源不足,就需要擴容。申請采購機器和資源導緻上線的周期較長,我們有時給客戶部署一個新業務,往往大多時間是在等到資源到位。另外,不同資源池之間的資源無法共享,也存在着一定的浪費。
是以工行要引入雲的架構。
FusionInsight很早就上了華為雲,即華為雲上的MRS服務。
當下工行和其他很多銀行都在部署雲平台,将大資料部署到雲平台上。但大規模的大資料叢集部署到雲上還存在着一些挑戰,基于雲原生的存算分離架構來部署大資料業務有很多優勢。
首先,将硬體資源池化,資源池化之後對上層就是比較标準的計算資源,計算和存儲可以靈活的擴充,使用率相對較高。
其次,基于雲平台的大資料環境搭建,全部自動化,從硬體資源準備到軟體安裝,僅用一小時完成。
再次,在申請叢集擴容資源彈性時,無需準備,可以很快的在大資源池進行統一調配。一般而言,雲上隻要預留了資源,空間資源可以很快加入到大資料的資源池裡,新業務上線也會變得非常靈活。
再說存算分離,存儲主要是以對象存儲為主,用低成本的對象存儲替代原來HDFS的三副本的能力,對象存儲一般提供相容HDFS的接口,在此基礎上,對象存儲可以給大資料、 AI等提供一個統一的存儲,降低存儲成本,運維的效率得以提高。
但是,對象存儲的性能不是很好,需要圍繞大資料的業務特點解決以下問題。
第一個,就是中繼資料,因為大資料是個重載計算,在計算的過程中讀IO很高。讀取資料的過程中。對象存儲的中繼資料性能是個很大的瓶頸,是以需要提升中繼資料的讀寫能力。
第二個,網絡帶寬,存儲與計算之間的網絡IO對網絡帶寬的需求比較高。
第三個,網絡時延,大資料計算是就近計算,資料在哪裡相應的計算就會在哪裡,存儲資料是優先讀本地盤,之後是讀網絡。時延存在一定的敏感性。
我們主要是從緩存、部分計算下推上做一些優化,整體上而言,存算分離架構的性能跟一體化相比,除了個别用例有差距,整體性能都更高,尤其是寫場景,因為寫對象存儲是寫EC,而不用寫三副本,寫1.2個副本就可以了。
最後,整體的 TCO大概得到30%~60%的下降。整體的性能與周邊其他産品對比還是具有很大的優勢。
大資料部署到雲上,對于大叢集而言,虛機并沒有太大優勢,因為資料池子夠大,虛機還會帶來性能的損耗,而且其性能與實體機有一定差距。而且,基于SLA隔離要求,大資料資源池在私有雲部署,很多時候還是需要獨占,其資源無法和别的業務共享。
而裸金屬服務實際上可以很好的解決這些問題,它的性能接近實體機,而且可以分鐘級完成裸金屬伺服器的發放,包括整個網絡配置,OS安裝。
網絡部分有專門的擎天網絡加速卡,對裸機網絡進行管理,而且網絡性能比原來的實體網卡的性能更高,在裸金屬伺服器上開展大規模大資料業務是雲上的最佳部署方案。
工行和我們也在探索湖倉一體的解決方案。
華為雲湖倉一體在存算分離的基礎上,将資料管理層獨立出來,其中包含了幾個部分,第一個是資料內建,資料從各種各樣的外部系統入湖。第二個是中繼資料內建,由于Hadoop資料湖上的中繼資料通過Hive管理,我們提供一個相容Hive Metastore的獨立中繼資料服務。第三個是資料的授權以及脫敏這些安全政策,我們要将其在Lake Formation這一層進行統一閉環。
資料的底座建構好之後,資料分析服務如大資料的服務、數倉的服務、圖計算、AI計算都是在同樣的一個資料視圖上進行計算處理。數倉DWS的服務本質是本地存儲,數倉也可以通過它的一個引擎通路Lakehouse中的資料。這樣數倉自己在本地有一個加速的資料層,同時也可以通路Lakehouse。
在此基礎上我們通過一個架構來實作這三種湖,持續演進。
藍色資料流是離線資料流,實作離線資料湖能力,資料通過批量內建,存儲到Hudi,再通過Spark進行加工。
紅色資料流是實時流,資料通過CDC實時捕獲,通過Flink實時寫入Hudi;通過Redis做變量緩存,以實作實時資料加工處理,之後送到諸如Clickhouse 、Redis、Hbase等專題集市裡對外提供服務。
同時,我們還開發了HetuEngine資料虛拟化引擎,将資料湖裡面的資料以及其他專題集市裡的資料進行多資料源關聯分析,形成邏輯資料湖。
雖然HetuEngine可以連接配接不同的資料源,但并不意味着所有應用隻能通過HetuEngine來通路資料,應用還是可以通過各資料源原生接口進行通路。僅需要不同專題資料之間進行聯合分析時,才需要通過HetuEngine統一通路。
如下是具體的實施計劃:
第一個,引入Hudi,建構一個資料湖的資料管理,每年大概可以節省幾百萬。
第二個,引入HetuEngine,實作資料湖内的資料免搬遷的查詢分析。避免一些不必要的ETL過程。
第三個,引入ClickHouse,ClickHouse在OLAP領域有着非常好的處理性能和很多優勢,是以考慮将其在工行落地。
資料湖以Hive作為存儲,采用一天一次批量內建、批量合并的方案,即T+1的資料處理模式。這種模式存在幾個比較大的業務痛點:
第一,資料延時比較高,後端服務看到的資料并不是最新的。
第二,跑批作業在夜裡進行,而白天資源使用率較低,但叢集資源是按照高峰期需求來建構,造成很大的資源浪費。
第三, Hive不支援更新,資料合并需要開發較多代碼實作,如把新資料臨時表與原Hive表進行左右關聯後覆寫原來整表或者部分分區表,開發成本比較高,業務邏輯複雜。
引入Hudi就可以在很大程度上解決這些問題。資料通過CDC入湖,通過Spark或者Flink寫入Hudi,支援實時更新,端到端可以做到分鐘級的時延。資料以非常小的微批形式合并到資料湖,分散跑批使得資源白天和晚上都能得到充分利用,資料湖叢集TCO預計可以下降20%。此外,資料內建腳本開發可以利用Hudi的Update能力,原來Hive要寫幾百行的代碼,隻需一行腳本即可完成,開發效率提升很大。
工行資料湖使用Hive來承載靈活查詢業務,如SAS使用Hive SQL來通路資料湖,通路效率比較低,響應時間長,并發能力也不足。
另外資料湖與數倉的兩層架構導緻了大量的重複資料,有較多關聯分析需求,關聯處理必然涉及到湖倉之間大量ETL。比如為了支撐BI工具的分析訴求,需要資料湖和數倉資料關聯處理加工,并将加工之後的資料導入OLAP引擎。整體資料鍊路比較長,分析效率和開發效率都很低。
通過HetuEngine資料虛拟化實作湖倉協同分析,一方面替代Hive SQL通路 Hive的資料,隻需1/5的資源即可支撐大概原來5倍并發,同時通路時延降到秒級。另一方面可同時通路Hive和DWS提供秒級的關聯查詢,可以減少80%的系統間的資料搬遷,大量的減少 ETL的過程。
傳統的OLAP方案一般用MySQL、Oracle或者其他的OLAP引擎,這些引擎因其處理能力有限,資料一般按照專題或者主題進行組織後與BI工具對接,導緻BI使用者和提供資料的資料工程師脫節。比如BI使用者有一個新的需求,所需的資料沒有在專題集市中,需要将需求給到資料工程師,以便開發相應的ETL任務,這個過程往往需要部門間協調,時間周期比較長。
現在可以将所有明細資料以大寬表的形式加載Clickhouse,BI使用者可以基于Clickhouse大寬表進行自助分析,對資料工程師供數要求就會少很多,甚至大部分情況下的新需求都不需要重新供數,開發效率和BI報表上線率都會得到極大提升。
這套方法論在我們内部實踐效果非常好,原來我們基于傳統OLAP引擎模組化,受限于開發效率,幾年才上線了幾十個報表。但是切到Clickhouse後,幾個月之内就上了大概上百個報表,報表開發效率極大提升。
注:本篇部落格根據雷鋒網舉辦的《銀行業AI生态雲峰會》演講内容改編。
點選關注,第一時間了解華為雲新鮮技術~