導讀:有一天我們接到這樣一條客訴“你們的收銀軟體最近特别慢,嚴重影響我們的收銀效率,再不解決我們就不用了”,我相信大家應該都遇到過這種問題,即使現在沒遇到,将來一定會遇到的,那遇到了怎麼辦呢?就這個話題我們今天一起來聊一聊。
關鍵詞:分布式,鍊路追蹤
靠人終究靠不住
不知道大家是怎麼處理開頭提到的那種問題的呢?最簡單粗暴的辦法就是把相關人員集中到一個會議室裡面對資料,怎麼對呢?
用戶端開發人員:我查了日志,用戶端的請求過程一共用了5s,請求是從幾點幾分幾秒發起的,你們查下服務端的日志;
交易系統開發人員:我這邊是幾點幾分幾秒收到的請求,交易系統一共花了4s多一些,其中調用支付網關花了将近4s,網關那邊看下日志吧;
網關開發人員:我這邊是幾點幾分幾秒收到的請求,網關一共花了3s多一點,大部分時間都花在了調用第三方上;
估計大多數人最開始都是這麼處理此類問題的,簡單粗暴。但如果三天兩頭給你來這麼一下子你還受得了嗎?每天給你幾百個上千個訂單号讓你對資料,你還能抽時間寫代碼嗎?估計連帶薪上廁所的時間都沒了吧。最後這個問題可能傳到了上司那裡,上司一般喜歡要全局報表資料,你怎麼給他出這個報表?是不是束手無策,突然有點想換工作了,哈哈。我們還真是接到過這種需求,一堆人在那裡awk然後就沒有然後了。
“當一件事情成為一件常态,那意味着我們可能需要一件工具來解放自己了,靠人終究是靠不住的”,就在這種背景之下我們決定引入一個調用鍊追蹤的工具來解放我們,也就是今天的主角jaeger。關于jaeger的說明網上很多,推薦去官網系統的了解一下 https://www.jaegertracing.io,我這裡隻是把搭建過程和使用上的一些心得分享出來和大家一起交流。
jaeger架構
直接引入一張官網的圖
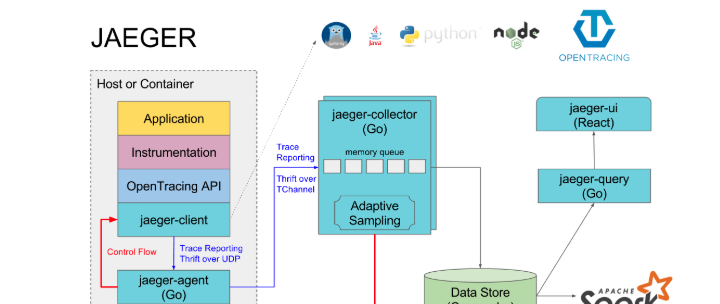
jaeger元件介紹:
jaeger-client:jaeger 的用戶端,實作了opentracing協定;
jaeger-agent:jaeger client的一個代理程式,client将收集到的調用鍊資料發給agent,然後由agent發給collector;
jaeger-collector:負責接收jaeger client或者jaeger agent上報上來的調用鍊資料,然後做一些校驗,比如時間範圍是否合法等,最終會經過内部的處理存儲到後端存儲;
jaeger-query:專門負責調用鍊查詢的一個服務,有自己獨立的UI;
jaeger-ingester:中文名稱“攝食者”,可用從kafka讀取資料然後寫到jaeger的後端存儲,比如Cassandra和Elasticsearch;
spark-job:基于spark的運算任務,可以計算服務的依賴關系,調用次數等;
其中jaeger-collector和jaeger-query是必須的,其餘的都是可選的,我們沒有采用agent上報的方式,而是讓用戶端直接通過endpoint上報到collector。
搭建jaeger
因為我們的應用服務都是采用容器部署的,是以我們的jaeger服務也沿用以往的風格。
docker啟動jaeger-collector
docker run -d --rm -p 14268:14268 -p 14269:14269 -e SPAN_STORAGE_TYPE=elasticsearch -e ES_SERVER_URLS=http://10.200.46.229:9200 jaegertracing/jaeger-collector:1.11
docker啟動jaeger-query
docker run -d --rm -p 16686:16686 -p 16687:16687 -e SPAN_STORAGE_TYPE=elasticsearch -e ES_SERVER_URLS=http://10.200.46.229:9200 jaegertracing/jaeger-query:1.11
應用程式接入
接下來就是如何讓調用鍊條上的各端接入了,這裡隻需要把握一個原則就好,“盡量讓接入方無感覺,沒有侵入性”,這裡簡單說下我們的接入方式:
用戶端接入:用戶端采用okhttp 攔截器的方式接入,使用請求頭傳遞trace上下文,這裡還可以和okhttp 的EventListener配合起來擷取一些網絡層面的名額,比如dns解析時間,連接配接發起時間等等;
web程式接入:web端采用springmvc攔截器方式接入,從http請求頭裡面來提取trace上下文,然後基于上下文建構一個springmvc的span,記得在請求結束的時候finish奧,否則調用鍊資料可能會長這樣:

RPC架構如何內建:一般RPC架構都會提供一些擴充點讓使用者來做一些架構內建的事情,拿dubbo來說可以采用Filter和隐示傳參的方式來實作請求上下文的傳遞;
外部調用如何內建:有一些調用是基于sdk或者httpclient調用的,這類調用我們如何植入調用鍊的邏輯呢?這裡不得不佩服AspectJ的強大了,為了避免你少走彎路我還會推薦你去了解一下“spectj-maven-plugin”這個maven插件,什麼?不是基于spring的那一堆注解就可以了嗎,為什麼還要引入maven來幹這事。估計你還需要去了解一下運作期植入和編譯器植入的相關概念以及适用場景。
具體你要把Span包裝成什麼樣就靠你自由發揮了,但是不要太離譜,建議參考下這個https://opentracing.io/docs/overview/spans/。
上線
上線前問自己幾個問題,我的攔截器寫的是否健壯,抛異常了不會影響正常調用吧?是否需要評估一下資料量?别一上線把後端存儲打死了。
使用jaeger-quey來檢索調用鍊
先選擇一個service然後針對這個service做一些複雜的檢索,比如針對某個标簽,操作的耗時等;
2.如果有滿足條件的資料右邊會展示出結果
上面圖中分别展示了兩條支付的調用鍊路,一條成功了,一條失敗了,你可能會問:jaeger是怎麼判斷成功失敗的呢?簡單來說就是通過特殊的标簽,直接甩給你一篇opentracing的文檔看完就懂了 https://github.com/opentracing/specification/blob/master/semantic_conventions.md。
3.檢視調用鍊詳情
4.檢視依賴關系,以及調用次數
也許你服務也搭好了,調用鍊資料也看到了,但就是看不到這個調用關系圖,别急你去這溜達一圈就知道了https://www.jaegertracing.io/docs/1.11/faq/。
好吧,今天就到這,大周六的晚上抽一點時間來梳理一下最近的工作,還希望對各位有一點點的幫助。
來我的公衆号與我交流