單機資料庫存在的問題?
從容量、性能、可用性和運維成本上難以滿足海量資料的場景。
性能方面,資料量超過一定門檻值,B+樹索引慎獨增加導緻磁盤通路的IO次數增加,進而導緻查詢性能的下降。
容量方面,單機能存儲的資料量有限
可用性方面,大量的查詢落到單一的資料庫節點或者簡單的主從架構上,資料庫很難承擔。
運維方面,資料量達到一定門檻值,主從同步延遲高、增加字段索引、備份這些都會很慢,影響業務系統。
主從結構解決了高可用、讀擴充。但是單機容量不變,單機寫性能無法解決。
為了解決這些問題,我們需要采用分庫分表,将資料庫拆分開。降低單個節點的寫壓力,提升整個系統的資料容量上限。
擴充立體方
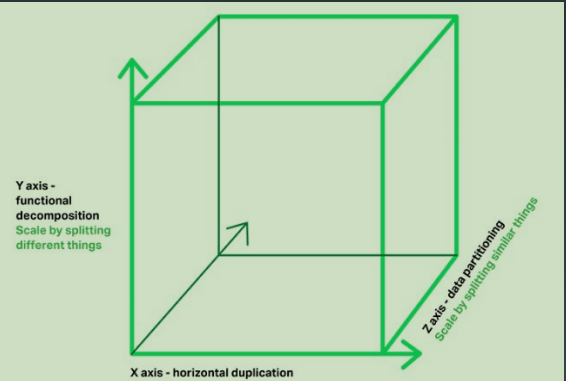
X軸:通過clone整個系統複制,叢集
Y軸:通過解耦不同功能複制,業務拆分
Z軸:通過拆分不同資料擴充,資料分片
垂直拆分,按照業務緯度分庫分表。
垂直拆庫
将一個資料庫,拆分為多個提供不同業務資料處理能力的資料庫。如:将一個電商的單獨庫拆為使用者庫、訂單庫、商品庫。
垂直拆表
如果單表資料量過大,還需要對單表進行拆分。如:一個200列的訂單主表,拆分為十幾個子表:訂單表、訂單詳情表、訂單收件資訊表等。
垂直拆分的優缺點:
優點:
單庫(單表)變小,便于管理
對性能和容量有提升
拆分後,系統和資料複雜度降低
可以作為微服務改造的基礎
缺點:
庫變多,管理變複雜
對業務系統有較強的侵入性
改造過程複雜,容易出故障
拆分到一定程度就無法繼續拆分
水準拆分就是直接對資料進行分片,有分庫和分表兩個具體方式。不改變資料本身的結構,隻是降低單個節點資料量。這樣對業務系統本身的代碼來說不需要做特别大的改動,甚至可以基于一些中間件做到透明。
比如把一個10億條記錄的訂單的單庫單表。按使用者id除以32取模,将單庫拆分為32個庫;再按訂單id除以32取模,每個庫再拆為32個表。這樣就是32*32=1024個表,單個表資料量就隻有不到百萬條了。
水準分庫分表
一般來說我們我們的資料都是有建立時間的,可以按時間拆分,按照年、季度、月、天都可以。
或者根據使用者拆分、甚至可以根據一些自定義的複雜的邏輯來拆分。
為什麼有時候不建議分表,隻建議分庫?
因為分表不能解決容量問題,如果瓶頸在IO(磁盤IO、網絡IO)上,分表也解決不了,因為分表還是在同一個機器,而分庫可以在兩個機器上。
分庫還是分表,如何選擇?
一般情況下,如果資料本身讀寫壓力較大,磁盤IO已經成為瓶頸,那麼分庫比分表要好。而使用不同的庫,可以并行提升整個叢集的并行資料處理能力。
相反的情況下,可以盡量考慮分表,降低單表的資料量。
水準分庫分表的優缺點:
解決容量問題
比垂直拆分對系統影響小
部分提升性能和穩定性
叢集規模大,管理複雜
複雜SQL支援問題
資料遷移問題
一緻性問題
資料的分類管理是指通過對資料進行分類提升資料管理能力。
随着對業務系統、對資料的分析了解發現,很多資料對品質的要求是不一樣的。
如訂單資料,肯定一緻性要求最高,不能丢失。而一些日志資料,中間資料,則沒有那麼高的一緻性。丢了就丢了。
另外,同一張表裡的訂單資料也可以采用不同政策,無效訂單比較多,我們可以定期轉移或清除。(一些交易系統裡80%以上的是下單後取消的無意義訂單,是以可以清理它)
如果沒有無效訂單,也可以考慮:
最近一周下單但是未支付的訂單,被查詢和支付的可能性較大。而再以前一點的,可以直接取消掉。
最近3個月下單的資料,被線上重複查詢和系統統計的可能性最大。
3個月以前-3年以内的資料,查詢的可能性小,可以不提供線上查詢
3年以上的資料,可以直接不提供任何方式的查詢。
這樣的話,我們就可以根據分類采用一定的手段去優化系統:
定義一周内下單但未支付的資料為熱資料,同時放到資料庫和記憶體
定義3個月内的資料為溫資料,放到資料庫,提供正常的查詢操作
定義3個月到3年的資料為冷資料,從資料庫删除,歸檔到一些便宜的磁盤,用壓縮的方式(比如MySQL的tokuDB引擎)存儲,使用者需要查詢的話提工單來查詢
定義3年以上的資料為冰資料,備份到錄音帶之類的媒體上,不提供任何查詢操作。
資料庫中間件的技術演進

ShardingSphere是一套開源的分布式資料庫中間件解決方案組成的生态圈,它由JDBC、Proxy和Sidecar(規劃中)這3款互相獨立,又能混合部署配合使用的産品組成。它們均提供資料分片、分布式事務和資料庫治理功能,可适用于如Java同構、異構、雲原生等各種多樣化的應用場景。
ShardingSphere-JDBC
架構ShardingSphere-JDBC,可以直接在業務代碼使用,支援常見的資料庫和JDBC。隻适用于Java語言。
使用執行個體:
讀寫分離:https://github.com/mmcLine/sharding/
分庫分表:https://gitee.com/mmcLine/shardingjdbc-database-example
業務系統停機
資料庫遷移,校驗一緻性
業務系統更新,接入新資料庫
如果新資料庫結構一樣,可以dump後全量導入。如果是異構的話,需要用程式處理。
依賴于資料本身的時間戳
先同步資料到最近的某個時間戳(如前一天)
然後再釋出更新時停機維護
再同步最後一段時間的變化資料
最後更新業務系統,接入新資料庫。
通過主庫或從庫的binlog來解析和重新構造資料,實作複制。
一般需要中間件工具的支援。
可以實作多線程,斷點續傳,全量或增量的資料同步。
繼而可以做到:
實作自定義複雜異構資料結構
實作自動擴容和縮容,比如分庫分表到單庫單表、單庫單表到分庫分表、分4個庫到分8個庫等等。
下面介紹一個遷移工具:
ShardingSphere-scaling
下載下傳包:https://archive.apache.org/dist/shardingsphere/4.1.0/
書山有路勤為徑,學海無涯苦作舟