多目标跟蹤:CVPR2019論文閱讀
Robust Multi-Modality Multi-Object Tracking
論文連結:https://arxiv.org/abs/1909.03850
代碼連結:https://github.com/ZwwWayne/mmMOT
摘要
在自主駕駛系統中,多傳感器感覺是保證系統可靠性和準确性的關鍵,而多目标跟蹤(MOT)則是通過跟蹤動态目标的序列運動來提高系統的可靠性和準确性。目前大多數的多傳感器多目标跟蹤方法要麼依賴于單一的輸入源(如中心錄影機)而缺乏可靠性,要麼在後處理過程中融合多個傳感器的結果而不充分利用固有資訊而不夠精确。在本研究中,本文設計了一個通用的傳感器不可知多模态MOT架構(mmMOT),其中每個模态(即傳感器)能夠獨立地執行其角色以保持可靠性,并通過一個新的多模态融合子產品進一步提高其精度。本文的mmMOT可以以端到端的方式進行訓練,能夠聯合優化每個模态的基本特征提取器和交叉模态的鄰接估計器。本文的mmMOT還首次嘗試在MOT的資料關聯過程中對點雲的深度表示進行編碼。本文進行了廣泛的實驗,以評估提出的架構對具有挑戰性的基蒂基準的有效性,并報告最新的表現。
1. Introduction
本文在融合子產品上進行了廣泛的實驗,并在KITTI跟蹤資料集上評估了本文的架構[13]。在沒有鈴聲和口哨聲的情況下,本文在線上設定下,純粹依靠圖像和點雲,在KITTI跟蹤基準[13]上取得了最新的結果,本文在單一模态(傳感器故障條件下)下,通過相同模型得到的結果也具有競争力(僅差0.28%)。
總之,本文的貢獻如下:
1) 本文提出了一個多模态MOT架構,其中包含一個穩健的融合子產品,利用多模态資訊來提高可靠性和準确性。
2) 本文提出了一種新的端到端訓練方法,使連接配接能夠優化跨模态推理。
3) 本文首次嘗試應用pointcloud的深層特征進行跟蹤,并獲得具有競争力的結果。
2. Related Work
多目标跟蹤架構
最近對MOT的研究主要遵循檢測跟蹤範式[6,11,38,50],其中感興趣的對象首先由對象檢測器獲得,然後通過資料關聯連接配接到軌迹。資料關聯問題可以從不同的角度來解決,例如最小代價流[11,20,37]、馬爾可夫決策過程(MDP)[48]、部分濾波[6]、匈牙利指派[38]和圖割[44,49]。然而,這些方法大多不是以端到端的方式訓練的,是以許多參數是啟發式的(例如,成本權重),并且容易受到局部最優的影響。在最小成本流動架構内實作端到端學習,Schulteretal。[37]通過平滑線性規劃應用雙層優化,深度結構模型(DSM)[11]利用鉸鍊損耗。然而,它們的架構并不是為跨模态而設計的。本文通過鄰接矩陣學習來解決這個問題。除了不同的資料關聯範式外,相關特征也被廣泛地用來确定檢測之間的關系。目前以圖像為中心的方法[11,35,38,50]主要使用圖像的深特征塊。手工制作的特征偶爾用作輔助輸入,包括但不限于邊界框[15]、幾何資訊[27]、形狀資訊[38]和時間資訊[45]。三維資訊也有好處,是以可以通過三維檢測預測[11]或使用神經網絡[36]或幾何先驗[38]從RGB圖像估計來利用。Osep等人[25]融合了來自RGB圖像、立體聲、視覺裡程表和可選場景流量的資訊,但它不能以端到端的方式進行調節。所有上述方法必須與相機配合,缺乏可靠性。相比之下,本文的mmMOT獨立地從每個傳感器中提取特征(包括深度圖像特征和點雲的深度表示),并且每個傳感器都扮演着同樣重要的角色,它們可以被分離。提出的注意引導融合機制進一步提高了融合精度。
點雲的深度表示
傳統的點雲跟蹤方法是測量距離[31],提供2.5D網格表示[2,10]或派生一些手工制作的特征[42]。它們都沒有充分利用點雲的固有資訊來解決資料關聯問題。最近的研究[3,7,24]已經證明了在自動駕駛中使用3D點雲作為感覺特征的價值。為了學習點雲的良好深度表示,PointNet[29]和PointNet++[30]使用對稱函數處理原始的非結構化點雲。本文在架構中采用了這種有效的方法。其他研究,如point SIFT[17]提出了一種方向編碼單元來學習點雲的SIFT樣特征,而3dsmouthNet[14]則學習了體素化的平滑密度值表示。還有一些方法[46,47]将點雲投影到球體上,是以2D CNN可以應用于分割任務。
目标檢測
目标檢測器也是逐點跟蹤的重要組成部分。自R-CNN的快速發展以來,用于2D目标檢測的深度學習方法有了很大的改進[23,32,43]。三維目标檢測近年來受到越來越多的關注。為了同時利用圖像和點雲,一些方法[8,18]從不同的角度聚集點雲和圖像特征,而F-PointNet[28]從圖像中擷取截頭體建議,然後應用PointNet[29]對點雲進行三維目标定位。有一些最先進的方法[19,39,51]隻使用點雲。一級檢測器[19,51]通常将CNN應用于體素化表示,兩級檢測器如PointRCNN[39]首先通過分割生成建議,在第二級重新定義。本文的mmMOT很容易适應二維和三維物體探測器。
3. Multi-Modality Multi-Object Tracking
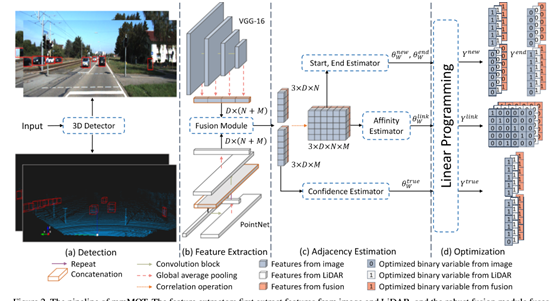
提出了一種多模态MOT(mmMOT)架構,該架構通過獨立的多傳感器特征提取來保持可靠性,通過模态融合來提高精度。它通常遵循從最小成本流角度廣泛采用的檢測跟蹤範式。具體來說,本文的架構包含四個子產品,包括目标檢測器、特征提取、鄰接估計和最小代價流優化器,分别如圖2(a),(b),(c),(d)所示。
首先,使用任意目标檢測器定位感興趣的目标。為了友善起見,本文使用PointPillar[19]。
第二,特征提取器為每次檢測獨立地從每個傳感器中提取特征,然後應用融合子產品對單模态特征進行融合并将其傳遞給鄰接估計器。鄰接估計是模态不可知的。它推斷出最小成本流量圖計算所需的分數。文中給出了鄰接估計的結構和相應的端到端學習方法。最小成本流優化器是一個線性規劃求解器,它根據預測得分确定最優解。
為了利用不同級别的特性,本文修改了池化層[4],以便将不同級别的特性傳遞到頂部,如圖2所示的VGG網絡所示。健壯的融合子產品可以使用任意的融合子產品,本文研究了三個融合子產品,如圖3所示。以兩個傳感器的設定為例,融合子產品A天真地将多個模式的特征串聯起來;子產品B将這些特征相加;子產品C引入注意機制。
由于相關操作在批處理次元中處理多模态,并且在兩幀之間的每個檢測對上執行,是以相關特征映射的大小為3×D×N×M。本文使用二維逐點卷積,如圖4所示。

4. Experiments
本文設定了一個二維跟蹤器作為基線,該跟蹤器隻使用二維圖像塊作為線索,在資料關聯時使用乘法作為相關算子,沒有排序機制。本文首先比較了圖像點雲和雷射雷達點雲的有效性,并評估了兩種使用點雲的方法:在椎體中使用點雲或在邊界框中使用點雲。從表1中的基線行可以看出,在截頭台中使用點雲會産生與在邊界框中使用點雲相同的競争結果。
如表1所示,盡管所有融合方法都超過了單傳感器基線,但隻有具有注意機制的魯棒融合子產品C顯著優于內建結果。結果表明,對于多傳感器輸入,找到一個魯棒的融合子產品是非常重要的。由于每個具有魯棒融合子產品的方法也提供了單個傳感器的預測,是以本文在表1中比較了每個魯棒融合子產品的單個傳感器結果。可以觀察到,雖然所提出的魯棒子產品能夠有效地融合多模态,但與基線(其中進行了單模态的專門訓練)相比,它可以在單模态上保持競争性能。這種融合的可靠性在文獻中是新的。
本文進一步比較了正常融合子產品的結果,後者隻輸出融合模态到鄰接估計器,是以跟蹤器在多模态設定下不能進行單模态跟蹤。表1最後一行的結果表明,所提出的魯棒子產品在處理單一模态的額外能力方面,始終優于基線子產品A、B和C。結果表明,在保證可靠性的前提下,mmMOT得到了更多的有利的監測信号,進而進一步提高了精度。
進一步改進了融合模型的結果。根據表2中的結論,本文使用絕對減法進行相關操作,使用加法激活softmax進行排名機制。本文比較了表3中每個修改的效果。絕對相減相關使融合模型的MOTA提高了1,而帶加法的softmax激活進一步提高了MOTA,使ID開關的數目減少到13,這是一個顯著的改進。
本文使用MOT提供的超過像素的RRC網[32]的2D檢測來獲得最新的和有競争力的結果[38]。本文使用PointNet[30]來處理截錐中的點雲,使用VGG-16[40]來處理圖像塊。更多細節見補充材料。表4将本文的方法與其他已釋出的最新線上方法進行了比較。本文首先使用所有的方式測試mmMOT,即mmMOT正常。然後通過将單一模态傳遞到同一模型,即mmMOT丢失圖像/點雲,模拟傳感器失效情況。在這兩種情況下,本文的mmMOT超過了MOTA上所有其他已釋出的最新線上方法。
本文使用MOT提供的超過像素的RRC網[32]的2D檢測來獲得最新的和有競争力的結果[38]。本文使用PointNet[30]來處理截錐中的點雲,使用VGG-16[40]來處理圖像塊。本文觀察到幾種可能導緻本文的mmmot失敗的情況。統計結果在補充材料中提供,示例如圖5所示,其中每行包括視訊中的四個連續幀。首先,對于遠處的物體,2D檢測器引起的早期錯誤将導緻假陰性檢測,如第一排ID9的汽車所示。
5. Conclusion
提出了一種多模态多目标跟蹤架構mmMOT。本文首次嘗試通過深度端到端網絡來避免單一傳感器的不穩定性,進而保持多模态的有效性。這樣一種功能在社群中被忽視了。本文的架構通過鄰接矩陣學習以端到端的方式獲得,是以可以在一段時間内獲得更大的誤差。此外,該架構首次将雷射雷達點雲的深度表示引入到資料關聯問題中,增強了多流架構對傳感器故障的魯棒性。
人工智能晶片與自動駕駛