<code>WHERE</code>用于檢索資料中符合條件的值,條件由一個或多個表達式組成,傳回結果為布爾值。
聯表查詢中WHERE與ON的差別:
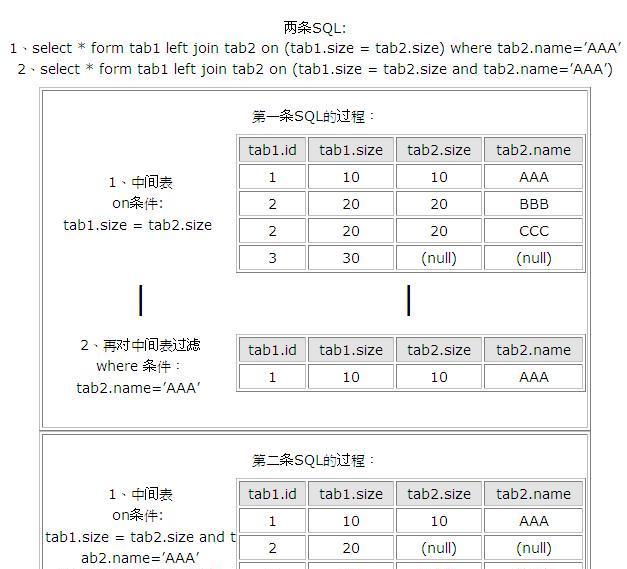
資料庫在通過連接配接兩張或多張表來傳回記錄時,都會生成一張中間的臨時表,然後再将這張臨時表傳回給使用者。
<code>ON</code>在生成臨時表時使用,傳回表會受到<code>JOIN</code>類型的影響。在<code>LEFT JOIN</code>和<code>RIGHT JOIN</code>中,無論<code>ON</code>上的條件是否為真都會傳回左表或右表中的内容,而在<code>INNER JOIN</code>中,<code>WHERE</code>與<code>ON</code>傳回表相同
<code>WHERE</code>在臨時表生成後,再對臨時表進行過濾。這時傳回表與<code>JOIN</code>的類型無關,條件不為真的就全部過濾
WHERE,ON,HAVING的差別:
執行次序:ON>WHERE>HAVING,如果這先後順序不影響中間結果的話,最終結果相同
<code>ON</code>先把不符合條件的記錄過濾後再進行統計,<code>HAVING</code>在分組之後再過濾資料,是以<code>HAVING</code>是執行最慢的,<code>ON</code>效率最高
<code>WHERE</code>無法與聚合函數一起使用,是以引入<code>HAVING</code>
on、where、having這三個都可以加條件的子句中,on是最先執行,where次之,having最後。有時候如果這先後順序不影響中間結果的話,那最終結果是相同的。但因為on是先把不符合條件的記錄過濾後才進行統計,它就可以減少中間運算要處理的資料,按理說應該速度是最快的。
根據上面的分析,可以知道where也應該比having快點的,因為它過濾資料後才進行sum,是以having是最慢的。但也不是說having沒用,因為有時在步驟3還沒出來都不知道那個記錄才符合要求時,就要用having了。
在兩個表聯接時才用on的,是以在一個表的時候,就剩下where跟having比較了。在這單表查詢統計的情況下,如果要過濾的條件沒有涉及到要計算字段,那它們的結果是一樣的,隻是where可以使用rushmore技術,而having就不能,在速度上後者要慢。
如果要涉及到計算的字段,就表示在沒計算之前,這個字段的值是不确定的,根據上篇寫的工作流程,where的作用時間是在計算之前就完成的,而having就是在計算後才起作用的,是以在這種情況下,兩者的結果會不同。
在多表聯接查詢時,on比where更早起作用。系統首先根據各個表之間的聯接條件,把多個表合成一個臨時表後,再由where進行過濾,然後再計算,計算完後再由having進行過濾。由此可見,要想過濾條件起到正确的作用,首先要明白這個條件應該在什幺時候起作用,然後再決定放在那裡。
![資料遷移方法資料遷移原則資料遷移之雙寫方案資料遷移之級聯同步方案[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)