摘要:Volcano主要是基于Kubernetes做的一個批處理系統,希望上層的HPC、中間層大資料的應用以及最下面一層AI能夠在統一Kubernetes上面運作的更高效。
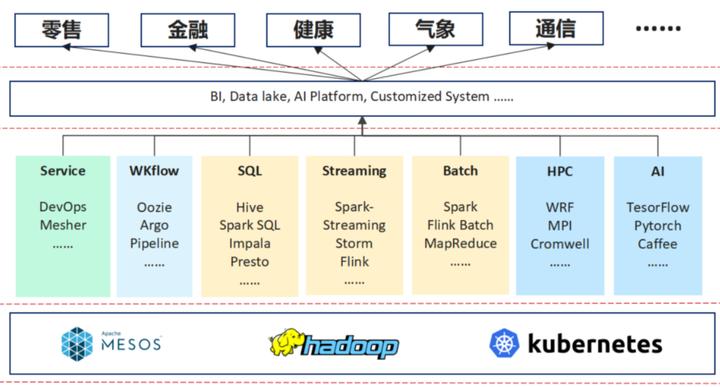
上圖是我們做的一個分析,我們将其分為三層,最下面為資源管理層,中間為領域的架構,包括AI的體系、HPC、Batch, WKflow的管理以及像現在的一些微服務及流量治理等。再往上是行業以及一些行業的應用。
随着一些行業的應用變得複雜,它對所需求的解決方案也越來越高。舉個例子在10多年以前,在金融行業提供解決方案時,它的架構是非常簡單的,可能需要一個資料庫,一個ERP的中間件,就可以解決銀行大部分的業務。
而現在,每天要收集大量的資料,它需要spark去做資料分析,甚至需要一些資料湖的産品去建立資料倉庫,然後去做分析,産生報表。同時它還會用 AI的一些系統,來簡化業務流程等。
是以,現在的一些行業應用與10年前比,變得很複雜,它可能會應用到下面這些領域架構裡面的一個或多個。其實對于行業應用,它的需求是在多個領域架構作為一個融合,領域架構的訴求是下面的資源管理層能夠提供統一的資源管理。

Kubernetes現在越來越多的承載了統一的資源管理的角色,它可以為 HPC這些行業領域架構提供服務,也可以作為大資料領域的資源管理層。Volcano主要是基于Kubernetes做的一個批處理系統,希望上層的HPC、中間層大資料的應用以及最下面一層AI能夠在統一Kubernetes上面運作的更高效。
挑戰 1: 面向高性能負載的排程政策
挑戰 2: 支援多種作業生命周期管理
挑戰 3: 支援多種異構硬體
挑戰 4: 面向高性能負載的性能優化
挑戰 5:支援資源管理及分時共享
藍色部分是 K8s本身的元件,綠色的部分是Volcano新加的一些元件。
1、通過 Admission 後,kubectl 将在 kube-apiserver中建立 Job (Volcano CRD) 對像
2、JobController 根據 Job 的配置建立 相應的 Pods e.g. replicas
3、Pod及PodGroup建立 後,vc-scheduler 會到 kube-apiserver 擷取Pod/PodGroup 以及 node 資訊
4、擷取資訊後,vc-scheduler 将根據其配置的排程政策為每一個 Pod 選取合适節點
5、在為Pod配置設定節點後,kubelet 将從kube-apiserver中取得Pod的配置,啟動相應的容器
vc-scheduler 中的排程政策都以插件的形式存在, e.g. DRF, Priority, Gang
vc-controllers 包含了 QueueController, JobController,PodGroupController 以及 gc-controller
vc-scheduler 不僅可以排程批量計算的作業,也可以排程微服務作業;并且可以通過 multi-scheduler 功能與 kube-scheduler 共存
左邊為Volcano Job Controller,不隻排程使用的Volcano,Job的生命周期管理、作業管理都在這裡面包含。我們提供了統一的作業管理,你隻要使用Volcano,也不需要建立各種各樣的操作,就可以直接運作作業。
右邊為CRD Job Controller,通過下面的PodGroup去做內建。
Scheduler支援動态配置和加載。左邊為apiserver,右邊為整個Scheduler,apiserver裡有Job、Pod、Pod Group;Scheduler分為三部分,第一層為Cache,中間層為整個排程的過程,右邊是以插件形式存在的排程算法。Cache會将apiserver裡建立的Pod、Pod Group這些資訊存儲并加工為Jobinfors。中間層的OpenSession會從Cache裡拉取Pod、Pod Group,同時将右邊的算法插件一起擷取,進而運作它的排程工作。
狀态之間根據不同的操作進行轉換,見下圖。
另外,我們在Pod和Pod的狀态方面增加了很多狀态,圖中藍色部分為K8s自帶的狀态;綠色部分是session級别的狀态,一個排程周期,我們會建立一個session,它隻在排程周期内發揮作用,一旦過了排程周期,這幾個狀态它是失效的;黃色部分的狀态是放在Cache内的。我們加這些狀态的目的是減少排程和API之間的一個互動,進而來優化排程性能。
Pod的這些狀态為排程器提供了更多優化的可能。例如,當進行Pod驅逐時,驅逐在Binding和Bound狀态的Pod要比較驅逐Running狀态的Pod的代價要小 (思考:還有其它狀态的Pod可以驅逐嗎?);并且狀态都是記錄在Volcano排程内部,減少了與kube-apiserver的通信。但目前Volcano排程器僅使用了狀态的部分功能,比如現在的preemption/reclaim僅會驅逐Running狀态下的Pod;這主要是由于分布式系統中很難做到完全的狀态同步,在驅逐Binding和Bound狀态的Pod會有很多的狀态競争。
在功能上面能帶來哪些好處?
支援多種類型作業混合部署
支援多隊列用于多租戶資源共享,資源規劃;并分時複用資源
支援多種進階排程政策,有效提升整叢集資源使用率
支援資源實時監控,用于高精度資源排程,例如 熱點,網絡帶寬;容器引擎,網絡性能優化, e.g. 免加載
Case 1: 1 job with 2ps + 4workers
Case 2: 2 jobs with 2ps + 4workers
Case 3: 5 jobs with 2ps + 4workers
在Volcano和 kubeflow+kube-scheduler做對比,Case 1在資源充足的時候效果是差不多的;Case 2是在沒有足夠的資源的情況下同時運作兩個作業,如果沒有 gang-scheduling,其中的一個作業會出現忙等 ;Case 3當作業數漲到5後,很大機率出現死鎖;一般隻能完成2個作業。
3個作業的執行時間總和; 每個作業帶2ps + 4workers
預設排程器執行時間波動較大
執行時間的提高量依據資料在作業中的比例而定
減少 Pod Affinity/Anti-Affinity,提高排程器的整體性能
Spark-sql-perf (TP-DCS, master)
104 queries concurrently
(8cpu, 64G, 1600SSD) * 4nodes
Kubernetes 1.13
Driver: 1cpu,4G; Executor: (1cpu,4G)*5
如果沒有固定的driver節點,最多同時運作 26 條查詢語句
由于Volcano提供了作業級的資源預留,總體性能提高了~30%
1)算力優化:
GPU硬體加速,TensorCore
GPU共享
昇騰改造
2)排程算法優化:
Job/Task模型,提供AI類Job統一批量排程
多任務排隊,支援多租戶/部門共享叢集
單Job内多任務叢集中最優化親和性排程、Gang Scheduling等
主流的PS-Worker、Ring AllReduce等分布式訓練模型
3)流程優化
容器鏡像
CICD流程
日志監控
Volcano可以支援更大規模的一個叢集排程,我們現在是1萬個節點百萬容器,排程的性能每秒達到2000個Pod。
1)編排:
Etcd 分庫分表,e.g. Event 放到單獨庫,wal/snapshot 單獨挂盤
通過一緻性哈希分散處理,實作 controller-manager 多活
Kube-apiserver 基于工作負載的彈性擴容
2)排程:
通過 EquivalenceCache,算法剪枝 等技術提升單排程器的吞吐性能
通過共享資源視圖實作排程器多活,提升排程速率
3)網絡:
通過trunkport提升單節點容器密度及單叢集ENI容量
通過 Warm Pool 預申請網口,提升網口發放速度
基于eBPF/XDP 支援大規模、高度變化的雲原生應用網絡,e.g. Service, network policy
4)引擎:
containerd 并發 啟動優化
支援shimv2,提升單節點容器密度
鏡像下載下傳加速 Lazy loading
Cromwell是一個流程排程軟體,它可以定義不同的作業,這個軟體在基因測序以及基因計算領域裡應用是比較廣泛的。
Cromwell 社群原生支援Volcano
企業版已經上線 華為雲 GCS
通過 cromwell 支援作業依賴
Volcano 提供面向作業、資料依賴的排程
叢集進行性能測試及排程的描述工具
不受資源限制,模拟大規模K8S叢集
完整的K8S API調用,不會真正建立pod
已經支援産品側大規模專項及排程專項的模拟工作
Worker cluster:承載kubemark虛拟節點,hollow pod
Master cluster:管理kubemark虛拟節點,hollow node
Hollow pod = hollow kubelet + hollow proxy
• 1.4k star,300+ fork,150+ 貢獻者
• 3 Maintainer,7 Reviewer
• 30 家企業、科研機構
點選關注,第一時間了解華為雲新鮮技術~