摘要:本篇文章将會從Spark on Kubernetes 發展曆程以及工作原理,以及介紹一下Spark with Volcano,Volcano如何能夠幫助 Spark運作地更高效。
我們來看Spark on Kubernetes的背景。其實Spark在從2.3這個版本開始之後,就已經支援了Kubernetes native,可以讓Spark的使用者可以把作業運作在Kubernetes上,用Kubernetes去管理資源層。在2.4版本裡增加了client mode和Python語言的支援。而在今年的釋出的Spark 3.0裡面,對Spark on Kubernetes這一方面也增加了很多重要的特性,增加動态資源配置設定、遠端shuffle service以及 Kerberos 支援等。
Spark on Kubernetes的優勢:
1)彈性擴縮容
2)資源使用率
3)統一技術棧
4)細粒度的資源配置設定
5)日志和監控
Spark對于Kubernetes的支援,最早的一種工作方式是通過 Spark官方的spark submit方式去支援,Clinet通過Spark submit送出作業,然後spark driver會調用apiserver的一些api去申請建立 executor,executor都起來之後,就可以執行真正的計算任務,之後會做日志備份。
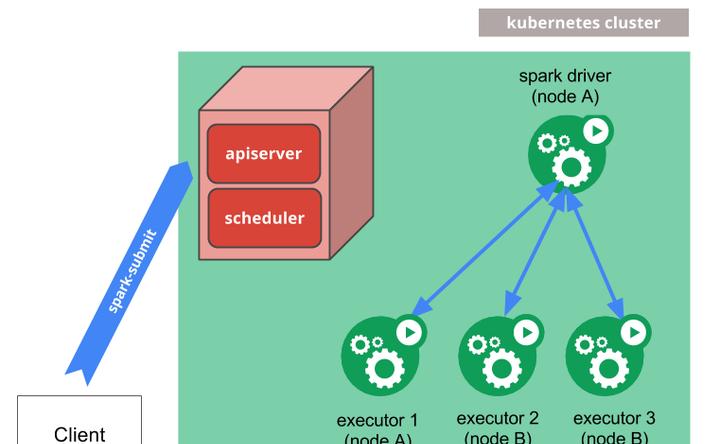
這種方式有一個優勢是,傳統的 Spark使用者切換到這種方式之後使用者體驗改變大。但也存在缺少作業周期管理的缺陷。
第二種Spark on Kubernetes的使用方式就是operator。operator是更Kubernetes的方式,你看他的整個作業送出,先是yaml檔案通過kubectl送出作業,在這裡面它有自己的crd,即SparkApplication,Object。建立了SparkApplication之後, Controller可以watch到這些資源的建立,後邊流程其實是複用的第一種工作模式,但是通過這種模式,做的更完善的一些。

相對于第一種方式來講,這裡的Controller可以維護對象生命周期,可以watch spark driver的狀态,并更新application的狀态,是一個更完善的解決方案。
這兩種不同的使用方式使用是各有優勢,不少的公司兩種方式都有使用。這一塊在官網也有介紹。
Volcano對于上面提到兩種工作方式都進行了內建和支援。這個連結是我們維護的 Spark開源代碼倉庫:https://github.com/huawei-cloudnative/spark/tree/spark-2.4-volcano-0.1
在這裡面Volcano做的事情其實也很簡單,你看整個送出的過程,首先是通過spark submit送出作業,送出作業時會建立一個podgroup,podgroup包含了使用者配置的一些排程相關的資訊。它的yaml檔案大家可以看到,頁面右邊這個部分,增加了driver和executor兩個角色。
隊列其實我們在第一堂和第二堂課裡面也講到了。因為Kubernetes裡面沒有隊列的支援,是以它在多個使用者或多個部門在共享一個機器的時候資源沒辦法做共享。但不管在HPC還是大資料領域裡,通過隊列進行資源共享都是基本的需求。
在通過隊列做資源共享時,我們提供了多種機制。圖最上面的這種,這裡面我們建立兩個隊列,通過這兩個隊列去共享整個叢集的資源,一個隊列給他分40%的咨詢資源,另一個給他分60%的資源,這樣的話就可以把這兩個不同的隊列映射到不同的部門或者是不同的項目各自使用一個隊列。這在一隊列裡,資源不用的時候,可以給另外一個隊列裡面的作業去使用。下面講的是兩個不同的namespace之間的資源平衡。Kubernetes裡當兩個不同的應用系統的使用者都去送出作業時,送出作業越多的使用者,他獲得的叢集的資源會越多,是以在這裡面基于namespace,我們進行公平的排程,保證namespace之間可以按照權重分享叢集的資源。
之前介紹這個場景的時候,有些同學反映沒有太聽懂,是以我加了幾頁PPT擴充一下。
舉個例子,我們在做性能測試的時候,送出16個并發的作業,對于每個作業來講,它的規格是1 driver+4 executor,整個叢集總共有4台機器16個核,這樣的一個情況。
同時送出16個spark job的時候,driver pod的建立和executor pod的建立之間有一個時間差。因為有這個時間差,當16個spark的job跑起來之後把整個機群全部占滿了,就會導緻同時送出并發量特别大作業的時候,整個叢集卡死。
為了解決這種情況,我們做了這樣的事情。
讓一個節點專門去跑driver pod。其他三個節點專門去跑executor pod,防止driver pod占用更多的資源,就可以解決被卡死的問題。
但也有不好的地方,這個例子裡節點是1:3的關系。在真實的場景下,使用者的作業的規格都是動态的, 而這種配置設定是通過靜态的方式去劃分,沒辦法跟真實的業務場景裡動态的比例保持一緻,總是會存在一些資源碎片,會有資源的浪費。
是以,我們增加了Pod delay creation的功能,增加這個功能之後不需要對node去做靜态的劃分,整個還是4個節點,在16個作業提上來的時候,對于每個作業增加了podgroup的概念。Volcano的排程器會根據提上來作業的podgroup進行資源規劃。
這樣就不會讓過多的作業會送出上來。不但可以把4個節點裡面所有的資源全部用完,而且沒有任何的浪費,在高并發的場景下控制pod建立的節奏。它的使用也非常簡單,可以按照你的需求配資源量,解決高并發的場景下運作卡死或者營運效率不高的情況。
我們知道原來的Spark已經很完善了,有很多特别好用的功能,Volcano保證了遷移到Kubernetes上之後沒有大的功能缺失:
1)ESS以daemonset的方式部署在每個節點
2)Shuffle本地寫Shuffle資料,本地、遠端讀shuffle資料
3)支援動态資源配置設定
點選關注,第一時間了解華為雲新鮮技術~