保護模式篇之TLB與CPU緩存,講解它們的作用和不同之處。
此系列是本人一個字一個字碼出來的,包括示例和實驗截圖。由于系統核心的複雜性,故可能有錯誤或者不全面的地方,如有錯誤,歡迎批評指正,本教程将會長期更新。 如有好的建議,歡迎回報。碼字不易,如果本篇文章有幫助你的,如有閑錢,可以打賞支援我的創作。如想轉載,請把我的轉載資訊附在文章後面,并聲明我的個人資訊和本人部落格位址即可,但必須事先通知我。
你如果是從中間插過來看的,請仔細閱讀 羽夏看Win系統核心——簡述 ,友善學習本教程。
看此教程之前,問幾個問題,基礎知識儲備好了嗎?上一節教程學會了嗎?上一節課的練習做了嗎?沒有的話就不要繼續了。
🔒 華麗的分割線 🔒
本次答案均為參考,可以與我的答案不一緻,但必須成功通過。
2️⃣ 自己實驗有和沒有<code>DEP</code>保護的程式,看看效果。
🔒 點選檢視答案 🔒
這題目有一個坑,接下來聽我娓娓道來。
首先說一句:你設定作業系統的<code>DEP</code>保護所有程式有效了嗎?(具體啟用檢視上一節教程,選中<code>為除下列標明程式之外的所有程式和服務啟用DEP</code>,直接點确定),不然不起效果,白皮書原話:
If IA32_EFER.NXE = 1, execute-disable (if 1, instruction fetches are not allowed from the 2-MByte region controlled by this entry; see Section 4.6); otherwise, reserved (must be 0).
也就是說<code>IA32_EFER</code>的<code>NXE</code>位為0,就算最高位是1也是無盡于是。我們更改這個選項就是使它為1,這個就是是坑。好了,根據我的代碼先運作一下:
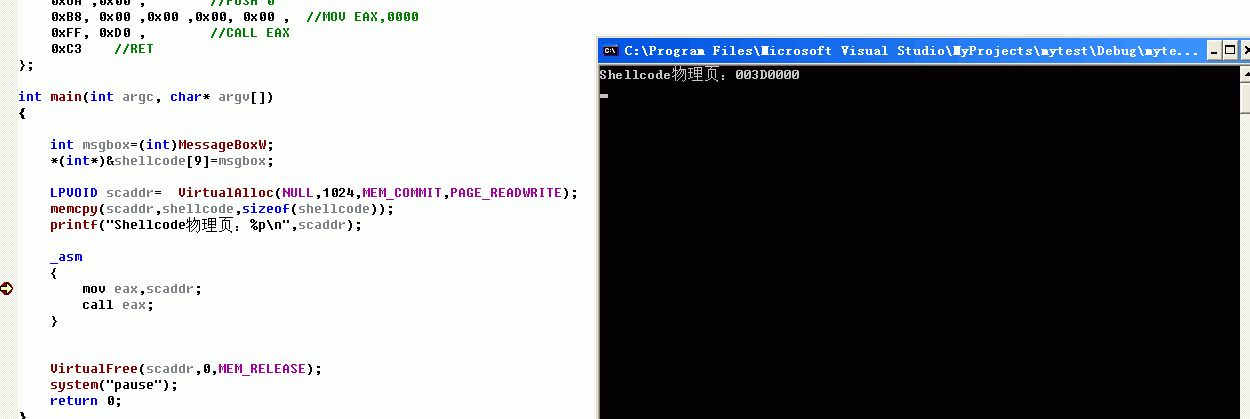
發現報錯了,這個和<code>10-10-12</code>分頁的不同之處。然後把<code>PAGE_READWRITE</code>改為<code>PAGE_EXECUTE_READWRITE</code>,然後再運作:

這次運作成功,既然它們的頁的首位址都是一樣的,我們來看看它們的<code>PDE</code>或者<code>PTE</code>哪裡不同,先是<code>PAGE_READWRITE</code>的:
然後是<code>PAGE_EXECUTE_READWRITE</code>:
可以看出<code>PTE</code>的最高位置為1,導緻這個頁被認為是資料,不是代碼,故導緻記憶體通路錯誤,如果我們在通路之前改了它,那麼就能通路它嗎?結果是可以的,我就不贅述了。
🔒 點選檢視代碼 🔒
<code>CPU</code>通過頁的方式對實體記憶體進行了,需要通過某種運算方式才能通路真正的記憶體。但是,如果頻繁通路某一個線性位址,每次都得通過推算到真正的實體位址然後進行讀寫操作,是不是挺浪費效率的?<code>Intel</code>就考慮到性能的問題,提供了<code>TLB</code>這一個機制,提供緩存提高讀寫效率。
<code>TLB</code>的全稱為<code>Translation Lookaside Buffer</code>,它的結構如下:
LA(線性位址)
PA(實體位址)
ATTR(屬性)
LRU(統計)
0x81010111
……
1
對于<code>TLB</code>,給出如下說明:
1. ATTR(屬性):如果是<code>2-9-9-12</code>分頁,屬性是<code>PDPE</code>、<code>PDE</code>、<code>PTE</code>三個屬性共同決定的。如果是<code>10-10-12</code>分頁就是<code>PDE</code>和<code>PTE</code>共同決定。
2. 不同的<code>CPU</code>這個表的大小不一樣。
3. 隻要<code>Cr3</code>變了,<code>TLB</code>立馬重新整理,一核一套<code>TLB</code>。
學到現在我們知道,作業系統的高2G映射基本不變,如果<code>Cr3</code>改了,<code>TLB</code>重新整理重建高2G以上很浪費。是以<code>PDE</code>和<code>PTE</code>中有個<code>G</code>标志位,如果<code>G</code>位為1重新整理<code>TLB</code>時将不會重新整理<code>PDE/PTE</code>的<code>G</code>位為1的頁,當<code>TLB</code>滿了,根據統計資訊将不常用的位址廢棄,最近最常用的保留。
<code>TLB</code>有不同的種類,用于不同的緩存目的,它在<code>X86</code>體系裡的實際應用最早是從<code>Intel</code>的<code>486CPU</code>開始的,在<code>X86</code>體系的<code>CPU</code>裡邊,一般都設有如下4組<code>TLB</code>:
第一組:緩存一般頁表(4K位元組頁面)的指令頁表緩存:<code>Instruction-TLB</code>
第二組:緩存一般頁表(4K位元組頁面)的資料頁表緩存:<code>Data-TLB</code>
第三組:緩存大尺寸頁表(2M/4M位元組頁面)的指令頁表緩存:<code>Instruction-TLB</code>
第四組:緩存大尺寸頁表(2M/4M位元組頁面)的資料頁表緩存:<code>Data-TLB</code>
CPU緩存是位于<code>CPU</code>與實體記憶體之間的臨時存儲器,它的容量比記憶體小的多但是交換速度卻比記憶體要快得多。它可以做的很大,但不是<code>TLB</code>,它們有很大的不同。<code>TLB</code>存的是線性位址與實體位址的對應關系,CPU緩存存的是實體位址與内容對應關系。
更多的細節請參考白皮書的<code>Chapter 11 Memory Cache Control</code>,本篇教程主要是針對核心安全層面,就不再贅述了。
<code>PWT</code>全稱為<code>Page Write Through</code>,<code>PWT = 1</code>時,寫<code>Cache</code>的時候也要将資料寫入記憶體中。
<code>PCD</code>全稱為<code>Page Cache Disable</code>,<code>PCD = 1</code>時,禁止某個頁寫入緩存,直接寫記憶體。比如,做頁表用的頁,已經存儲在<code>TLB</code>中了,可能不需要再緩存了。
本節的答案将會在下一節進行講解,務必把本節練習做完後看下一個講解内容。不要偷懶,實驗是學習本教程的捷徑。
俗話說得好,光說不練假把式,如下是本節相關的練習。如果練習沒做好,就不要看下一節教程了,越到後面,不做練習的話容易夾生了,開始還明白,後來就真的一點都不明白了。本節練習很少,請保質保量的完成。
1️⃣ 在<code>10-10-12</code>分頁模式下體會<code>TLB</code>的存在。要求:通過代碼挂實體頁,不能通過<code>Windbg</code>挂。原實體頁挂完寫入值讀取,然後把位址換實體頁繼續讀取,看看值是否發生變化。然後用<code>INVLPG</code>指令之後再看看值是否變化。
保護模式篇——中斷與異常和控制寄存器
本作品采用 知識共享署名-非商業性使用-相同方式共享 4.0 國際許可協定 進行許可
本文來自部落格園,作者:寂靜的羽夏 ,一個熱愛計算機技術的菜鳥
轉載請注明原文連結:https://www.cnblogs.com/wingsummer/p/15364649.html