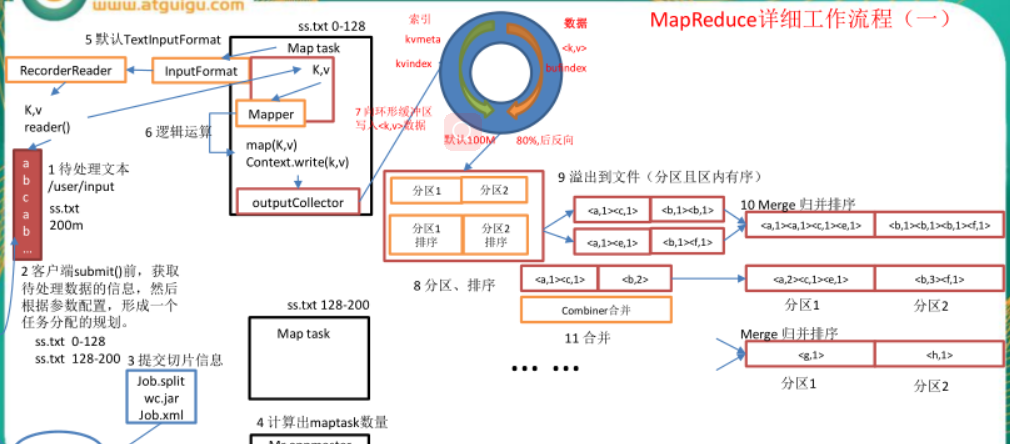
1.待處理文本
2.用戶端submit()前擷取待處理資料資訊,然後根據參數設定,形成一個任務配置設定的規劃,切片資訊
3.送出切片資訊
job.split
wc.jar
job.xml
4.yarn RM 計算出maptask的數量 Mr appmaster nodemastask數量
拿到的是切片資訊,多少個切片,就有多少個maptask
5.預設TextInputFormat
maptask 發出inputFormat —> RecordReader (流的拷貝)
傳回 K-V對
6. Mapper邏輯運算 map(K,V) context.write(k,v) ----> outputCollector
7. 向環形緩沖區寫入<K,V>資料

一端是中繼資料索引(key-value-reduceTypenum:大小,長度,格式),一端是資料,預設是100M,達到80%反向,溢寫資料
8.分區,實際是對索引的分區,分區内容的排序,對key進行排序,預設是字典排序,字典排序過程中是使用的快速排序
9.溢寫檔案(分區且區内有序) 環形再往回寫 循環
很多次溢寫,隻要達到80%,
10.合并merge 歸并排序
多次溢寫
1.所有map結束
maptask不能小于分區數
拷貝自己處理分區的資料
先放到記憶體中,進行歸并排序
優化重點:拷貝過來記憶體不夠,寫進磁盤,自己優化記憶體