這是3月份某客戶的情況,原因是server硬體故障後進行更換之後,業務翻譯偶爾出現送出緩慢的情況。我們先來看下awr的情況。
我們能夠看到,該系統的load profile資訊事實上并不高,每秒才21個transaction。先來看看top5events:
從top 5event,我們能夠發現,log file sync的avg wait很之高,高達124ms。大家應該知道,對于絕大多數情況
下,log file sync的平均等待時間是小于5ms的,這個值有點高的離譜。
我們知道,産生log file sync等待的原因有非常多。關于log file sync,tanel Poder大神寫過一篇非常牛的pdf,大家能夠參考下。
這裡我主要引用大神的圖,來簡單描寫叙述産生log file sync的原因可能有哪些,首先我們來看下從前端程序送出到最後得到回報時,以及中間處理的整個流程情況:
從上圖中,我們能夠清楚的看到整個流程。這裡能夠進行簡單的描寫叙述:
1、當user發起一個commit後;
2、前端程序(即Server 程序)會post一個資訊給lgwr程序,告訴它,你應該去寫redo buffer了。
3、當LGWR程序得到訓示後,開始調用作業系統函數進行實體寫,在進行實體寫的這段時間内,會出現
log file parallel write等待。這裡也許有人會有疑問,為什麼12c之前僅僅有一個lgwr程序,這裡卻是parallel
write呢?這裡須要說明一下,lgwr程序在将redo buffer中的資料寫出到log file檔案裡時,也是以batch方式
程序的(實際上,dbwN程序也是batch的模式),有相關的隐含參數控制。
4、當LGWR完畢wrtie操作之後,LGWR程序會傳回一個資訊給前端程序(Server程序),告訴它,我已經寫完了,
你能夠完畢送出了。
5. user 完畢commit操作。
這裡補充一下,這是因為Oracle 日志寫優先的原則,如果在commit之前redo buffer的相關entry資訊不馬上寫到redo
log file中,那麼假設資料庫出現crash,那麼這是會丢資料的。
從上面的流程圖,我們事實上也能夠看到,log file sync和log file parallel write能夠說是互相關聯的。換句話講,假設log file parallel write的時間非常長,那麼必定導緻log file sync等待時間拉長。
我們如果log file parallel write 等待非常高,那麼着可能一般是實體磁盤IO的問題,例如以下:
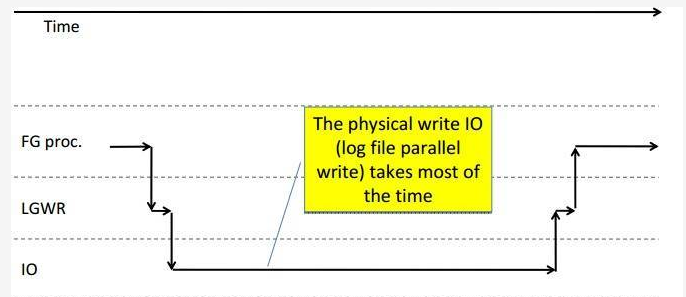
我們從上圖能夠發行,假設LGWR程序在完畢IO操作的過程中時間過長,那麼将導緻log file parallel write等待升高。
實際上,在整個當使用者發出commit到完畢commit的過程中,涉及到非常多環節,并非隻唯獨實體IO會影響log file sync/log file parallel write。還有CPU也會影響Log file sync和log file parallel write。我們再來看個圖:

我們能夠看到,上述流程中的4個環節都涉及到CPU的排程,假設在整個事務commit的過程中,系統CPU出現極度緊張,那麼這可能會導緻LGWR程序無法獲得CPU,會進行排隊等待,顯然,這勢必将導緻log file sync或log file parallel write等待
的升高。
備注:Oracle中還能夠通過隐含參數_high_priority_processes 來控制程序擷取CPU的優先級。在一個cpu相對缺乏的系統中,能夠通過設定該參數來進行緩解。
最後我們再回到這個案例中來,客戶這裡的環境,我們是能夠排除CPU問題。那麼最大的嫌疑可能就是存儲本身的問題,導緻IO非常慢,然而,實際上這也是能夠排除的,大家事實上應該注意到前面的Top 5 event了,log file parallel write的平均等待
時間并不高,假設是存儲IO問題,那麼這個event的平均等待時間應該是比較高才對。
我們能夠看到log file sync和log file parallel write的waits都是差點兒相同的。可是log file parallel write的avg wait time隻唯獨4ms,這是一個正常的值。也就是說能夠我們排除存儲IO問題。
那麼問題是什麼呢 ?我們利用Oracle MOS提供的腳本來查詢下log file sync和log file parallel write等待的分布情況:(實時檢視)
<code> </code><code>INST_ID EVENT WAIT_TIME_MILLI WAIT_COUNT</code>
<code>---------- ---------------------------------------- --------------- ----------</code>
<code> </code><code>1 log file sync 1 259306</code>
<code> </code><code>1 log file sync 2 2948999</code>
<code> </code><code>1 log file sync 4 1865918</code>
<code> </code><code>1 log file sync 8 173699</code>
<code> </code><code>1 log file sync 16 43194</code>
<code> </code><code>1 log file sync 32 6095</code>
<code> </code><code>1 log file sync 64 1717</code>
<code> </code><code>1 log file sync 128 2458</code>
<code> </code> <code>1 log file sync 256 5180</code>
<code> </code> <code>1 log file sync 512 9140</code>
<code> </code> <code>1 log file sync 1024 558347</code>
<code> </code> <code>1 log file parallel write 1 5262</code>
<code> </code> <code>1 log file parallel write 2 4502377</code>
<code> </code> <code>1 log file parallel write 4 1319211</code>
<code> </code> <code>1 log file parallel write 8 46055</code>
<code> </code> <code>1 log file parallel write 16 23694</code>
<code> </code> <code>1 log file parallel write 32 3149</code>
<code> </code> <code>1 log file parallel write 64 283</code>
<code> </code> <code>1 log file parallel write 128 267</code>
<code> </code> <code>1 log file parallel write 256 157</code>
<code> </code> <code>1 log file parallel write 512 73</code>
<code> </code> <code>1 log file parallel write 1024 42</code>
<code> </code> <code>1 log file parallel write 2048 39</code>
<code> </code> <code>1 log file parallel write 4096 103</code>
<code> </code> <code>1 log file parallel write 8192 21</code>
<code> </code> <code>1 log file parallel write 16384 22</code>
<code> </code> <code>1 log file parallel write 32768 190</code>
<code> </code> <code>1 log file parallel write 65536 1</code>
大家能夠簡單的計算一下,事實上log file sync和log file parallel write 等待事件,差點兒99%左右的平均等待時間都是
小于等于4ms的,這是屬于正常的情況;然而有少數的情況其等待時間是非常長的,比如log file sync最高的單次等待
時間高達1秒,因為偶爾的等待非常高,是以将整個log file sync的平均等待時間拉高了。
到最後,問題就比較清楚了,我覺得這是因為主機和存儲之間的鍊路可能出現異常或不穩定導緻。暫時的解決方法
将redo logfile 挪到本地磁盤,攻克了該問題。
後記:經客戶後面确認,确實是存儲光纖線接口松了。
source : http://www.cnblogs.com/hrhguanli/p/3891951.html
文章可以轉載,必須以連結形式标明出處。
本文轉自 張沖andy 部落格園部落格,原文連結: http://www.cnblogs.com/andy6/p/7501606.html ,如需轉載請自行聯系原作者