任何程式員,都應該有良好的的編碼習慣,便于以後的代碼可讀性和維護
常見了編碼規範有
匈牙利命名法
駝峰式大小寫
匈牙利命名法:
是電腦程式設計中的一種變量命名規則,此命名法又可細分為:系統匈牙利命名法和匈牙利應用命名法。
匈牙利命名法具備語言獨立的特性,并且首次在BCPL語言中被大量使用。由于BCPL隻有機器字這一種資料類型,是以這種語言本身無法幫助程式員來記住變量的類型。匈牙利命名法通過明确每個變量的資料類型來解決這個問題。
在匈牙利命名法中,一個變量名由一個或多個小寫字母開始,這些字母有助于記憶變量的類型和用途,緊跟着的就是程式員選擇的任何名稱。這個後半部分的首字母可以大寫,以差別前面的類型訓示字母(參見駝峰式大小寫)。
例如: i_de f_fd db_d ch_c 第一個給定的資訊可以很明确的直到是什麼類型的.
便于代碼的可讀性
駝峰式大小寫:
駝峰式大小寫(Camel-Case,Camel Case,camel case),電腦程式編寫時的一套命名規則(慣例)。
當變量名和函數名稱是由二個或多個單字連結在一起,而構成的唯一識别字時,利用“駝峰式大小寫”來表示,可以增加變量和函數的可讀性。
例如: AddSum() SubValue BinarraySerach() 由此可以看出每個函數的作用
例如第一個 加一個數的總數 第二個減去值 第三個二進制數組查找.
拿到一個編輯器的時候
第一步:
講他的Tab鍵設定為空格鍵替換,這樣可以保證在任何平台下的代碼都是一樣看.
第二步:
編寫代碼的時候每句代碼如果依賴上一層代碼的關系,需要在首行加上縮進.
第三步:
講編輯器設定線,可以保證代碼不要超過,這樣有助于代碼的可讀性
第四步:
編寫源代碼的時候上邊要加注釋 注釋要求是:
要求(可以是項目要求,功能要求,做什麼的說出來)
時間(你修改後的時間)
姓名(你什麼時候修改的,加上時間,加上自己的姓名)
Scanf(“%d,%d”,&a,&b);
對于scanf函數來說,在掃描輸入的時候,你加什麼,輸入的分隔符号就要是什麼
一般scanf預設都是空格或者回車是分隔符的.
Scanf函數中可以放正規表達式
常見的正規表達式有:
Scanf(“%[0-9]d”,&a);代表隻能輸入0-9,不對的不會輸出
Scanf(“%a-z]d”,&a);代表隻能輸入a-z,不對的不會輸出
Scanf(“%[^5]d”,&a);代表不能輸入五,輸入五不會掃描進去
scanf和 sscanf的差別
Scanf是從标準輸入裝置中掃描輸入的
Sscanf是從标準輸入中掃描輸入到字元串當中的,他也可以用正規表達式.一般很常用.
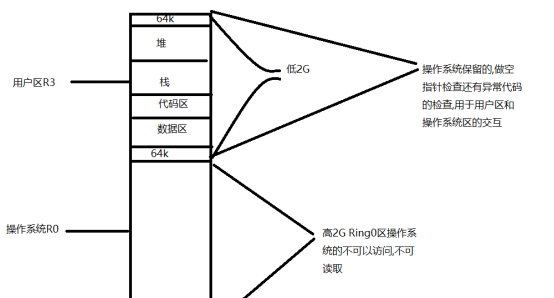
任何一個程式通路理論上是4G的記憶體
但是作業系統占高2g的記憶體此時這個記憶體是不可以讀取和修改的,因為這塊成為Ring3 也可以成為R0
除非你有作業系統的權限.
而低2g還不是程式可以直接通路的
還可以劃分為 低64 和高64
這些是使用者區用于和作業系統互動的緩沖區
現在剩下的記憶體還可以再分為
棧段
堆段
代碼區
資料段
也就是咱們程式員常說的記憶體四區
而現在你的程式運作起來記憶體也不是都給你的,而是你需要多少我給你多少.
這樣就保證了程式可以一下開2-30個了.
下面看看記憶體模型
C語言和同類型相比有很多的資料類型
其中__int64 的long類型是非标準類型,如果從商業化角度來看,微軟就可以牢牢的把握住
這些人的平台,都是依賴自己的.因為非标準類型的代碼,不可以移植的.
溢出和進位的差別
溢出:是針對有符号資料的描述,意思就是當資料到最大值的時候,如果在+1那麼資料就會溢出有可能标稱負數,恢複代價大.有可能不能恢複.
進位:
進位是針對無符号資料的描述,當資料超過這個資料的時候,那麼就會産生進位.目前值還是有效的.可以通過一定的手段獲得進位資料.
字元穿的存儲和互動:
總共提出來2中概念
一種是:
C語言風格的,在字元後面以0結尾,代表是一個字元串.
另一種是Pascal風格
前幾位(不确定,一般是2位)給定大小,後面存儲大小一樣的字元,形成一個字元串
他們的優缺點
C語言:
優點:靈活性比較高,特别是網絡通信的時候,隻要不是以0結尾,那麼自己可以傳輸任意的字元.
缺點:缺點就是比較明顯了,如果要找第N個字元,那麼要一個一個的查找,
Pascal:
優點:
長度固定,通路N個的效率高,可以以跳闆的形式通路
缺點:
缺乏靈活性,如果用于網絡,那麼傳輸完之後隻能在傳輸新的,不能接着傳輸了.
而微軟的是2中特性相結合
前表類型,後邊以0結尾,(比較狡猾)這樣做的好處是,相容性更高,自家的産品賣得更好.
‘a’ 和””a’’的差別
字元a是可以通路Ascii編碼的
而字元串a則是引用的字元串的首位址
辨別符的規範是:C語言中,定義辨別符隻能是數字字母下劃線
其中數字不能開頭
例如:
2ac 這樣定義是不對的,這樣的話分不清2是幹什麼的.
規則式向0取整
3/2 = 1 數學中是1.5
而數學中有向上取整和向下取整的意思
就是1.5 如果向下取整,意思就是取不大于自己的最大整數 也就是2
向上取整就是取不小于自己的最大整數 也就是1
是以在C語言中右移符号使用時必須要判斷商是否是負數
如果是負數那麼因為規則式向0取整,那麼就會出現錯誤.
1.5向0取整,就是舍棄小數0.5
我們都知道%号的作用
8%3=2
-8%3=-2
8%-3=2
-8%-3=-2
算出來的結果和左操作數符号有關,左操作數是什麼符号那麼餘數就是什麼符号.
但是原理咱們不知道,
其實原理就是
A/b=q...r
A = q*b+r;
R = a-q*b;
代入值後發現
8/3=2..2
8 = 2*3+2
餘數2 = 8-2*3
是以結果就是2