筆者最近開始學習InnoDB的内部機制,參照之前的幾篇文章整理出InnoDB多版本部分相關的一些實作原理。
<a href="http://mysql.taobao.org/monthly/2015/04/01/">InnoDB undo log 漫遊</a>
<a href="http://blog.csdn.net/longxibendi/article/details/42012629">性能優化·5.7 Innodb事務系統</a>
<a href="http://mysql.taobao.org/monthly/2017/12/01/">InnoDB 事務系統</a>
<a href="https://yq.aliyun.com/articles/41050">[MySQL 5.6] Innodb 新特性之 multi purge thread</a>
<a href="http://blog.csdn.net/zhaiwx1987/article/details/7211220">innodb purge操作</a>
對于undo日志,第1篇文章寫得非常清楚,圖文并茂。本文有關undo的大部分内容也是取自此文,這裡隻是以筆者的視角重新組織描述一下。
在此特别感謝前面同學多年的積累和熱心分享:)
筆者屬于學習階段,如描述有問題請多指正。
InnoDB支援MVCC多版本,其中RC(Read Committed)和RR(Repeatable Read)隔離級别是利用consistent read view(一緻讀視圖)方式支援的。
所謂consistent read view就是在某一時刻給事務系統trx_sys打snapshot(快照),把當時trx_sys狀态(包括活躍讀寫事務數組)記下來,之後的所有讀操作根據其事務ID(即trx_id)與snapshot中的trx_sys的狀态作比較,以此判斷read view對于事務的可見性。
Read view中儲存的trx_sys狀态主要包括
low_limit_id:high water mark,大于等于view->low_limit_id的事務對于view都是不可見的
up_limit_id:low water mark,小于view->up_limit_id的事務對于view一定是可見的
low_limit_no:trx_no小于view->low_limit_no的undo log對于view是可以purge的
rw_trx_ids:讀寫事務數組
RR隔離級别(除了Gap鎖之外)和RC隔離級别的差别是建立snapshot時機不同。
RR隔離級别是在事務開始時刻,确切地說是第一個讀操作建立read view的;RC隔離級别是在語句開始時刻建立read view的。
建立/關閉read view需要持有trx_sys->mutex,會降低系統性能,5.7版本對此進行優化,在事務送出時session會cache隻讀事務的read view。
下次建立read view,判斷如果是隻讀事務并且系統的讀寫事務狀态沒有發生變化,即trx_sys的max_trx_id沒有向前推進,而且沒有新的讀寫事務産生,就可以重用上次的read view。
Read view建立之後,讀資料時比較記錄最後更新的trx_id和view的high/low water mark和讀寫事務數組即可判斷可見性。
如前所述,如果記錄最新資料是目前事務trx的更新結果,對應目前read view一定是可見的。
除此之外可以通過high/low water mark快速判斷:
trx_id < view->up_limit_id的記錄對于目前read view是一定可見的;
trx_id >= view->low_limit_id的記錄對于目前read view是一定不可見的;
如果trx_id落在[up_limit_id, low_limit_id),需要在活躍讀寫事務數組查找trx_id是否存在,如果存在,記錄對于目前read view是不可見的。
由于InnoDB的二級索引隻儲存page最後更新的trx_id,當利用二級索引進行查詢的時候,如果page的trx_id小于view->up_limit_id,可以直接判斷page的所有記錄對于目前view是可見的,否則需要回clustered索引進行判斷。
如果記錄對于view不可見,需要通過記錄的DB_ROLL_PTR指針周遊history list構造目前view可見版本資料。
InnoDB也是采用復原段的方式建構old version記錄,這跟Oracle方式類似。
記錄的DB_ROLL_PTR指向最近一次更新所建立的復原段;每條undo log也會指向更早版本的undo log,進而形成一條更新鍊。通過這個更新鍊,不同僚務可以找到其對應版本的undo log,組成old version記錄,這條鍊就是記錄的history list。
MySQL 5.6對于沒有顯示指定READ ONLY事務,預設為是讀寫事務。在事務開啟時刻配置設定trx_id和復原段,并把目前事務加到trx_sys的讀寫事務數組中。
5.7版本對于所有事務預設為隻讀事務,遇到第一個寫操作時,隻讀事務切換成讀寫事務配置設定trx_id和復原段,并把目前事務加到trx_sys的讀寫事務數組中。
配置設定復原段的工作在函數trx_assign_rseg_low進行,配置設定政策是采用round-robin方式。
從5.6開始支援獨立的undo表空間,InnoDB支援128個undo復原段,請參照第1篇文章。
rseg0:預留在系統表空間ibdata中
rseg1~rseg32:這32個復原段存放于臨時表的系統表空間中
rseg33~rseg127:根據配置存放到獨立undo表空間中(如果沒有打開獨立Undo表空間,則存放于ibdata中)
trx_assign_rseg_low判斷,如果支援獨立的undo表空間,在undo表空間有可用復原段的情況下避免使用系統表空間的復原段。
rseg->skip_allocation為TRUE表示rseg所在的表空間要被truncate,應該避免使用此rseg配置設定復原段。此種情況,必須保證有至少2個活躍的undo表空間,并且至少2個活躍的undo slot。
配置設定成功時,遞增rseg->trx_ref_count,保證rseg的表空間不會被truncate。
臨時表操作不記redo log,最終調用get_next_noredo_rseg函數進行配置設定;其他情況調用get_next_redo_rseg。
復原段實際上是undo檔案組織方式,每個復原段維護了一個段頭頁(segment header),該page劃分了1024個slot(TRX_RSEG_N_SLOTS),每個slot對應到一個undo log對象。
理論上,InnoDB最多支援 96 (128 - 32 /* temp-tablespace */) * 1024個普通事務。
但如果是臨時表的事務,可能還需要多配置設定1個slot(臨時表的系統表空間)。
隻讀階段為臨時表配置設定的,在臨時表的系統表空間中配置設定
讀寫階段在undo表空間配置設定
Insert資料隻對目前事務或者送出之後可見,是以insert的undo log在事務commit後就可以釋放了。
Update/delete的undo記錄通常用來維護old version記錄,為查詢提供服務;隻有當trx_sys中沒有任何view需要通路那個old version的資料時才可以被釋放。
InnoDB對insert和update/delete配置設定不同的undo slot
insert的undo slot記在trx->rsegs.m_redo.insert_undo,調用trx_undo_assign_undo配置設定
update的undo slot記在trx->rsegs.m_redo.undate_undo,調用trx_undo_assign_undo配置設定
I. 檢查cached隊列是否有緩存的undo log(記憶體中資料結構是trx_undo_t)
如果存在,把這個undo log從cached隊列移除
reuse的邏輯:
a.insert undo:重新初始化undo page的header資訊(trx_undo_insert_header_reuse),并在redo log記一條MLOG_UNDO_HDR_REUSE日志
b.update undo:在undo page的header上配置設定新的undo header(trx_undo_header_create),并在redo log記一條MLOG_UNDO_HDR_CREATE日志
預留xid空間
重新初始化undo(trx_undo_mem_init_for_reuse)把undo->state設定為TRX_UNDO_ACTIVE,并把undo->state寫入到第一個undo page的TRX_UNDO_SEG_HDR+TRX_UNDO_STATE位置上
注1:TRX_UNDO_SEG_HDR表示segment header起始offset
注2:undo segment與事務trx是一一對應關系,undo segment header的狀态(TRX_UNDO_STATE)跟事務目前狀态也是一一對應的
如下圖(引自第1篇文章)
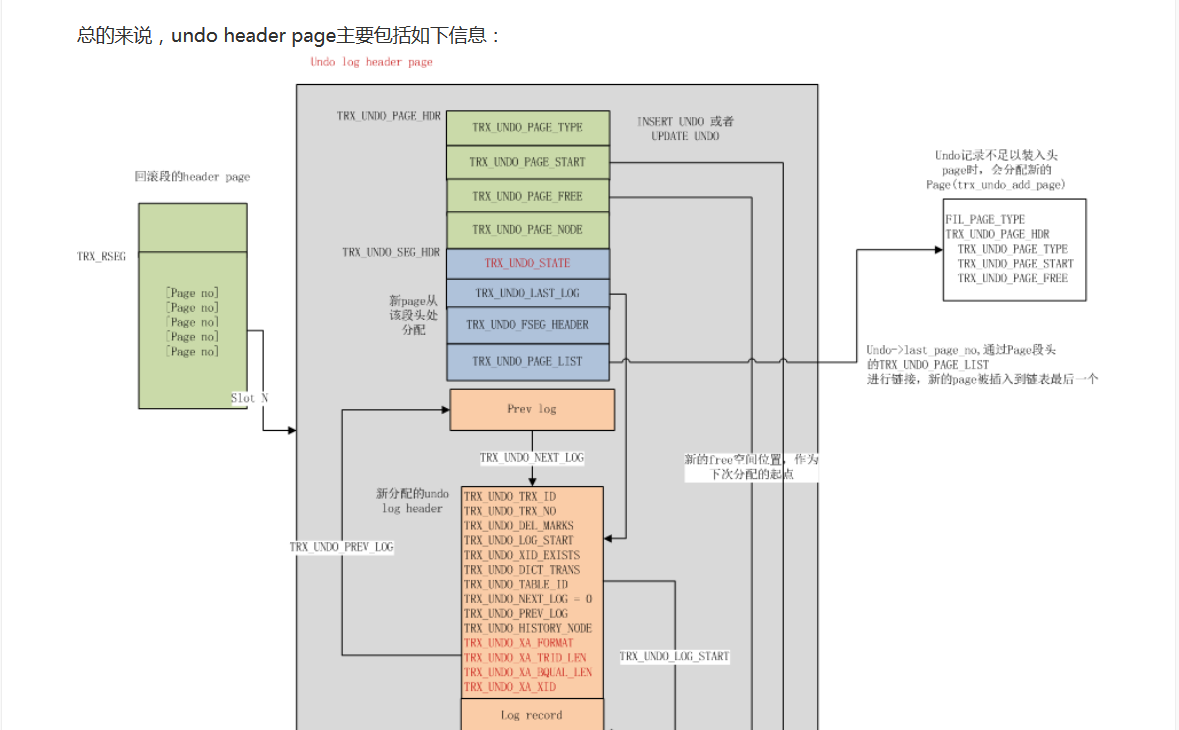
undo segment是個獨立的段,每個undo segment包含1個header page(第1個undo page)和若幹個記錄undo日志的undo page。
第1個undo page中存儲的是元資訊:
首先存儲的是undo page的元資訊,位于TRX_UNDO_PAGE_HDR到TRX_UNDO_SEG_HDR之間。
TRX_UNDO_PAGE_START:指向page中第一個undo log
TRX_UNDO_PAGE_FREE:指向page中下一個undo log要寫到的位置
TRX_UNDO_PAGE_NODE:undo segment所有page組成一個雙向連結清單,每個page的TRX_UNDO_PAGE_NODE字段作為連接配接件,第一個undo page中的TRX_UNDO_PAGE_LIST作為表頭
之後是undo segment的元資訊,位于TRX_UNDO_SEG_HDR到TRX_UNDO_SEG_HDR+TRX_UNDO_SEG_HDR_SIZE
TRX_UNDO_STATE:表示undo segment的狀态,一個undo segment可以包含多個undo log,但至多隻有1個active undo log,也就是最近的undo log
TRX_UNDO_LAST_LOG:指向最近的undo log的header資訊
TRX_UNDO_FSEG_HEADER:存儲的是undo segment對應的file segment資訊,在fseg_create_general中設定(4位元組space id,4位元組的page no,2位元組的page offset)
undo segment從buffer pool移除被persist到磁盤時,就寫到file segment指定的位置上
再之後是undo log header資訊,所有的undo log header都存儲在第一個undo page上。
II. 從cached隊列配置設定undo失敗時,需要真正配置設定一個undo segment(trx_undo_seg_create)
首先要從rseg配置設定一個slot(trx_rsegf_undo_find_free),每個rseg至多支援1024個slot。找到空slot傳回index。
如果目前rseg已滿,trx_undo_seg_create傳回DB_TOO_MANY_CONCURRENT_TRXS向上層報錯,表示并發事務太多無法建立undo segment。
然後在rseg對應的table space建立一個新的file segment,file segment資訊記在segment header的TRX_UNDO_FSEG_HEADER(fseg_create_general)。
trx_undo_seg_create在建立file segment之後,把新建立segment的page no寫到rseg對應slot上建立映射關系,并傳回新建立segment的page。
file segment與undo segment的映射關系,還有rseg[slot]與file segment對應page的映射關系都是在trx_undo_seg_create綁定的。cached undo不會更新這兩個映射關系。
III. trx_undo_seg_create傳回的page上建立新的undo header;上層負責初始化trx_undo_t資料結構
trx_undo_create為新建立的undo header建立記憶體資料結構trx_undo_t(trx_undo_mem_create),把undo->state設定為TRX_UNDO_ACTIVE。
IV. 配置設定好的trx_undo_t會加入到事務的insert_undo_list或者update_undo_list隊列上
trx_undo_assign_undo配置設定undo之後,就可往其中寫入undo記錄。寫入的page來自undo->last_page_no,初始情況下等于hdr_page_no。
update undo包含一個重要的部分:記錄的目前復原段指針要寫到undo log裡面,以便維護記錄的曆史資料鍊。
read view需要讀老版本資料時,會通過記錄中目前的復原段指針開始向前找到可見版本的資料。
完成Undo log寫入後,建構新的復原段指針并傳回(trx_undo_build_roll_ptr),這個指針也就是clustered索引記錄的DB_ROLL_PTR。
復原段指針包括rseg->id、日志所在的page no、以及page内偏移量,需要記錄到clustered索引記錄中。這裡rseg->id用來确定rseg->space,真正用于定位undo log位置的其實是<rseg->space, undo->page,undo->page_offset>三元組。
設定undo->state為TRX_UNDO_PREPARED,并把這個狀态寫到第一個undo page的(TRX_UNDO_SEG_HDR+TRX_UNDO_STATE)位置上。
除此之外,prepare階段還要更新xid資訊。
在事務commit階段,需要把undo->state設定為完成狀态,并把undo加到undo segment的history list。正在送出的undo header被指向history list的第一項,表示目前事務history list最近的undo。
undo->state完成狀态包括3種,在trx_undo_set_state_at_finish設定
undo隻占一個page,而且第一個undo page已使用的空間小于3/4 (TRX_UNDO_PAGE_REUSE_LIMIT):狀态設定為TRX_UNDO_CACHED
不滿足1的情況下,如果是insert_undo(TRX_UNDO_INSERT):狀态設定為TRX_UNDO_TO_FREE
不滿足1和2的情況下,狀态設定為TRX_UNDO_TO_PURGE,表示undo可能需要purge線程清理
cached undo會被到cached隊列上,這個隊列就是trx_undo_assign_undo提到的cached隊列
設定完undo->state之後,需要把這個狀态寫入到第一個undo page的(TRX_UNDO_SEG_HDR+TRX_UNDO_STATE)位置上
Insert的old version沒有實際意義,是以insert undo在事務commit時就可以釋放了。
trx_undo_set_state_at_finish裡面有cached政策,如果隻占1個undo page,并且undo page已使用的空間不足pagesize的3/4可以被reuse,其實大部分insert undo都屬于這種情況。
Update undo需要維護history list。這裡先提一下trx->no,它維護了事務trx commit順序,跟事務的trx_id一樣,也是使用max_trx_id遞增産生。
另外,purge_sys(purge的全局資料結構)維護個最小堆,每個rollback segment第1次事務送出時向最小堆插入資料,旨在找到trx_no最小的rollback segment進行purge。後面每次處理完1個rseg後,會把下一個undo記錄的trx_no壓入到這個最小堆,作為rseg的cursor。
事務commit時按照trx->no順序,把事務目前的undo log挂到undo segment history list的表頭,指向事務最近的undo log。
History list裡的undo都是已送出事務的,目前事務所修改的undo log都記錄在這裡,按照從新->老方式排列,最老的undo log在尾部。
undo加入到history list的方式是:以undo log的TRX_UNDO_HISTORY_NODE作為連接配接件,加入到第一個undo page的TRX_RSEG_HISTORY。
一般來說,每次調用trx_purge_add_update_undo_to_history都會把undo加入到history list,隻有在undo page無法被reuse時才更新history list大小(可以認為是個優化,最後一次更新history length)。
在此之後,trx_purge_add_update_undo_to_history會把undo log header的TRX_UNDO_TRX_NO更新為trx_no。
如果undo->del_marks是FALSE,這個函數也會更新TRX_UNDO_DEL_MARKS(undo segment建立或者reuse被初始化為TRUE),澄清這不是delete marker。
如果undo segment自建立以來(也可能是上次purge完成之後)中第1個事務commit,還需要更新purge有關的一些參數,指向下次purge從哪裡開始執行。
舊版本資料不再被任何view通路就可以被删除了。5.6以上版本支援獨立purge線程,使用者可以通過參數Innodb_purge_threads設定purge線程個數。
有兩類purge線程:
coordinator thread:srv_purge_coordinator_thread,全局隻有1個
worker thread:srv_worker_thread,系統有innodb_purge_threads - 1個
coordinator thread負責啟動worker thread參與到purge工作中。
增加purge線程的政策是:trx_sys->rseg_history_len比上次循環變大了或者rseg_history_len超過某一門檻值,需要引進更多的worker thread。
減少purge線程的政策是:如果之前使用多個purge 線程,trx_sys->rseg_history_len并沒有變大,可能需要減少worker thread。
在進行purge之前,首先要确定purge線程要做哪些工作,也就是說哪些undo log可以被purged。
purge也是通過read view來确定工作範圍,被稱為purge view。如果系統有活躍read view,就選取最老的read view作為purge view。
如果不存在就給trx_sys的狀态打個snapshot,作為purge view,可以被purge的undo log其trx_no一定是小于系統中所有已送出事務的trx->no。
這裡插一句,在事務commit時,會把産生的trx->no加入到trx_sys->serialisation_list連結清單,這個連結清單是按照trx->no升序次序排列,也就是維護了trx commit順序。
InnoDB初始化的時候會初始化purge_sys資料結構,其中一個工作就是建立purge graph。
這是總共3層結構的圖:
第1層是fork節點
第2次是thrd節點(表示purge thread)
第3層是node節點(表示purge task)
所有的thrd節點被鍊入到fork->thrs連結清單中;fork位址存儲在purge_sys->query,可以通過purge_sys直接通路。
執行purge的時候總是周遊purge_sys->query->thrs連結清單,給每個purge線程配置設定purge任務(trx_purge_attach_undo_recs)。
解析undo log的調用路徑如下:
purge_sys->next_stored為FALSE時,表示rseg_iter目前指向的rseg無效,需要把rseg_iter移到下一個有效的rseg(TrxUndoRsegsIterator::set_next)。
purge_sys->purge_queue維護了一個最小堆,每次pop最頂元素,可以得到trx_no最小的rollback segment(TrxUndoRsegsIterator::set_next)。
5.7支援臨時表的noredo的rollback segment,set_next遇到redo rollback segment和noredo rollback segment同時存在的情況會一股腦把這兩個rollback segment都pop出來加入到
purge_sys->rseg_iter->m_trx_undo_rsegs數組中,也在TrxUndoRsegsIterator::set_next實作。
如果沒有rollback segment需要purge話,purge_sys->rseg設定為NULL,purge線程會去睡眠(trx_purge_choose_next_log)。
一般情況下都是有rollback segment需要處理的,purge_sys->rseg更新成purge_sys->rseg_iter->m_trx_undo_rsegs的第1項(至多2項)。
purge_sys中的相應成員也要更新,指向目前rseg上次purge到的位置(TrxUndoRsegsIterator::set_next)。
update undo的del_marks域正常情況下都是TRUE,因為update/delete操作都需要對old value進行标記删除。
如果purge_sys->rseg->last_del_marks是FALSE的話,表示這是一個dummy的undo log,不需要做實體删除。這種情況下,把purge_sys->offset設定成0,做個标記表示這個undo log不需要被purged(trx_purge_read_undo_rec)。
正常情況下purge_sys->rseg->last_del_marks是TRUE,可以通過<purge_sys->rseg->space, purge_sys->hdr_page_no, purge_sys->hdr_offset>讀取undo log記錄(trx_purge_read_undo_rec)。
并把purge_sys以下四個域設定成undo log記錄相應的資訊(trx_purge_read_undo_rec)。
為了保證purge_sys以上4個域一定是指向下一個有效undo log,每次讀取undo log時都會捎帶着讀取下一個undo log,并把上面這四個域更新為下一個undo log的資訊,方面後續通路(trx_purge_get_next_rec)。
如果是dummy undo,trx_purge_get_next_rec會去讀prev_undo(trx_purge_rseg_get_next_history_log),用prev_log資訊更新rseg中下一個purge資訊。
在此之後,還會把rseg->last_trx_no壓入最小堆,待後面繼續處理這個rseg。
然後調用trx_purge_choose_next_log選擇下一個處理的rseg,并讀取第一個undo log(trx_purge_get_next_rec)。
就這樣挨個讀取undo log,trx_purge_attach_undo_recs中有一個大循環,每次調用trx_purge_fetch_next_rec讀到一個undo log後,把它存放到purge節點(purge graph的第三級節點)
node->undo_recs數組裡面,循環下一次執行切換到下一個thr(purge 線程)。
循環的結束條件是:
沒有新的undo log
處理過的undo log達到batch size(一般是300)
達到循環結束條件後,trx_purge_attach_undo_recs傳回。如果n_purge_threads > 1 (需要worker線程參與purge),coordinator線程會以round-robin方式啟動n_purge_threads - 1個worker線程。
不管有沒有worker線程參與purge,coordinator線程都會調用que_run_threads(在trx_purge上下文)去處理purge任務。
purge任務如何處理呢?通俗的說purge就是删除被标記delete marker的記錄項。
大緻過程如下:
一般删除的原則是先删除二級索引再删除clustered索引(row_purge_del_mark)。
另一種情況是聚集索引in-place更新了,但二級索引上的記錄順序可能發生變化,而二級索引的更新總是标記删除 + 插入,是以需要根據復原段記錄去檢查二級索引記錄序是否發生變化,并執行清理操作(row_purge_upd_exist_or_extern)。
前面提到過在parse undo log時,可能遇到dummy undo log。傳回到row_purge執行時需要判讀是否是dummy undo,如果是就什麼也不做。
trx_purge在處理完一個batch(通常是300)之後,調用trx_purge_truncate_historypurge_sys對每一個rseg嘗試釋放undo log(trx_purge_truncate_rseg_history)。
大緻過程是:把每個purge過的undo log從history list移除,如果undo segment中所有的undo log都被釋放,可以嘗試釋放undo segment,這裡隐式釋放file segment到達釋放存儲空間的目的。
由于篇幅有限,這部分就不深入介紹了。
![資料遷移方法資料遷移原則資料遷移之雙寫方案資料遷移之級聯同步方案[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)