導語:情感情緒檢測是自然語言了解的關鍵要素。最近,我們将原來的項目遷移到了新的內建系統上,該系統基于麻省理工學院媒體實驗室推出的NLP模型搭建而成。
情感情緒檢測是自然語言了解的關鍵要素。最近,我們将原來的項目遷移到了新的內建系統上,該系統基于麻省理工學院媒體實驗室推出的NLP模型搭建而成。
代碼已經開源了!(詳見GitHub:https://github.com/huggingface/torchMoji )
該模型最初的設計使用了TensorFlow、Theano和Keras,接着我們将其移植到了pyTorch上。與Keras相比,pyTorch能讓我們更自由地開發和測試各種定制化的神經網絡子產品,并使用易于閱讀的numpy風格來編寫代碼。在這篇文章中,我将詳細說明在移植過程中出現的幾個有趣的問題:
如何使用自定義激活功能定制pyTorch LSTM
PackedSequence對象的工作原理及其建構
如何将關注層從Keras轉換成pyTorch
如何在pyTorch中加載資料:DataSet和Smart Batching
如何在pyTorch中實作Keras的權重初始化
首先,我們來看看torchMoji/DeepMoji的模型。它是一個相當标準而強大的人工語言處理神經網絡,具有兩個雙LSTM層,其後是關注層和分類器:
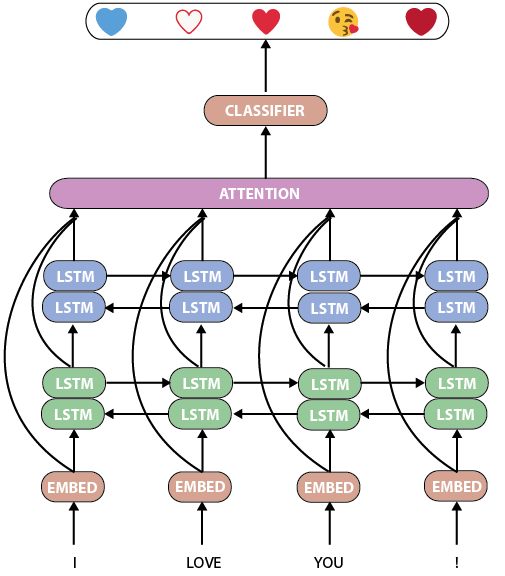
torchMoji/DeepMoji模型
DeepMoji有一個很不錯的特點:Bjarke Felbo及其協作者能夠在一個擁有16億條記錄的海量資料集上訓練該模型。是以,預先訓練的模型在此訓練集中具有非常豐富的情感和情緒表征,我們可以很友善地使用這個訓練過的模型。
該模型是使用針對LSTM的回歸核心的Theano/Keras預設激活函數hard sigmoid訓練的,而pyTorch是基于NVIDIA的cuDNN庫模組化的,這樣,可獲得原生支援LSTM的GPU加速與标準的sigmoid回歸激活函數:

Keras預設的LSTM和pyTorch預設的LSTM
是以,我寫了一個具有hard sigmoid回歸激活函數的自定義LSTM層:
這個LSTM單元必須內建在一個完整的子產品中,這樣才可以使用pyTorch所有的功能。這個內建相關的代碼很長,建議直接引用到Github中的相關源代碼。
模型的關注層是一個有趣的子產品,我們可以分别在Keras和pyTorch的代碼中進行比較:
如你所見,主要的算法大緻相同,但PyTorch代碼中的大部分都是注釋,而Keras則需要編寫幾個附加函數并進行調用。
在編寫和調試自定義子產品和層時,pyTorch是一個更快的選擇;而對于快速訓練和測試由标準層建構的模型時,Keras顯然更加合适。
Keras有一個不錯的掩碼功能可以用來處理可變長度序列。那麼在pyTorch中又該如何處理這個呢?可以使用PackedSequences! pyTorch文檔中有關PackedSequence的介紹并不是很詳細,是以這裡會較長的描述它的細節。
一個擁有5個序列18個令牌的典型NLP批次
假設我們有一批可變長度的序列(在NLP應用中通常就是這樣的)。為了在GPU上并行計算這樣一個批次,我們希望:
盡可能多地并行處理這個序列,因為LSTM隐藏狀态依賴于每個序列的前一個時間步長,以及
以正确的時間步長(每個序列的結尾)停止每個序列的計算。
這可以通過使用pyTorch中的PackedSequence類來實作。我們首先通過減少長度來對序列進行排序,并将它們放到在張量中。然後對張量和序列長度清單調用pack_padded_sequence函數
PackedSequence對象包括:
一個data對象:一個torch.Variable(令牌的總數,每個令牌的次元),在這個簡單的例子中有五個令牌序列(用整數表示):(18,1)
一個batch_sizes對象:每個時間步長的令牌數清單,在這個例子中為:6,5,2,4,1
用pack_padded_sequence函數來構造這個對象非常的簡單:
如何構造一個PackedSequence對象(batch_first = True)
PackedSequence對象有一個很不錯的特性,就是我們無需對序列解包(這一步操作非常慢)即可直接在PackedSequence資料變量上執行許多操作。特别是我們可以對令牌執行任何操作(即對令牌的順序/上下文不敏感)。當然,我們也可以使用接受PackedSequence作為輸入的任何一個pyTorch子產品(pyTorch 0.2)。
例如,在我們的NLP模型中,我們可以在對PackedSequence對象不解包的情況下連接配接兩個LSTM子產品的輸出,并在此對象上應用LSTM。我們還可以在不解包的情況下執行關注層的一些操作。
在Keras中,資料加載和批處理通常隐藏在fit_generator函數中。重申一遍,如果你想要快速地測試模型,Keras很好用,但這也意味着我們不能完全控制模型中的重要部分。
在pyTorch中,我們将使用三個類來完成這個任務:
一個DataSet類,用于儲存、預處理和索引資料集
一個BatchSampler類,用于控制樣本如何批量收集
一個DataLoader類,負責将這些批次提供給模型
我們的DataSet類非常簡單:
我們BatchSampler則更有趣。
我們有幾個小的NLP資料集,用于微調情感情緒檢測模型。這些資料集有着不同的長度和某些不平衡的種類,是以我們想設計這麼一個批量采樣器:
在預先定義的樣本數中收集批次,這樣我們的訓練過程就可以不依賴于批次的長度
能夠從不平衡的資料集中以平衡的方式進行采樣。
在PyTorch中,BatchSampler是一個可以疊代生成批次的類,BatchSampler的每個批處理都包含一個清單,其中包含要在DataSet中選擇的樣本的索引。
是以,我們可以定義一個用資料集類标簽向量來初始化的BatchSampler對象,以建構滿足我們需求的批次清單:
将Keras/Tensorflow/Theano代碼移植到pyTorch的過程中,最後需要注意的事情是對權重的初始化。
Keras在開發速度方面的另一個強大特點是層的預設初始化。
相反,pyTorch并沒有初始化權重,而是由開發者自己來決定。為了在微調權重時獲得一緻的結果,我們将像如下代碼那樣複制預設的Keras權重初始化:
當我們針對一個模型比較Keras和pyTorch這兩個架構時,我們可以感覺到它們有着不同的哲學和目标。
根據我的經驗來看:
Keras非常适合于快速測試在給定任務上組合标準神經網絡塊的各種方法;
pyTorch非常适合于快速開發和測試自定義的神經網絡子產品,因為它有着很大的自由度和易于閱讀的numpy風格的代碼。