從入門到第一個模型”差點就成了“從入門到放棄”。本文是機器學習在運維場景下的一次嘗試,用一個模型實作了業務規律挖掘和異常檢測。這隻是一次嘗試,能否上線運轉還有待考究。
歡迎大家前往騰訊雲技術社群,擷取更多騰訊海量技術實踐幹貨哦~
作者:李春曉
導語:
“從入門到第一個模型”差點就成了“從入門到放棄”。本文是機器學習在運維場景下的一次嘗試,用一個模型實作了業務規律挖掘和異常檢測。這隻是一次嘗試,能否上線運轉還有待考究。試了幾個業務的資料,看似有效,心裡卻仍然忐忑,擔心哪裡出錯或者有未考慮到的坑,将模型介紹如下,請大俠們多多指教,幫忙指出可能存在的問題,一起交流哈。
背景:
業務運維需要對業務基礎體驗名額負責,過去的分析都是基于大資料,統計各個次元及其組合下關鍵名額的表現。比如我們可以統計到不同網絡制式下打開一個app的速度(耗時),也可以擷取不同指令字的成功率。針對移動APP類業務,基于經驗,我們在分析一個名額時都會考慮這些因素:App版本、名額相關的特有次元(比如圖檔下載下傳要考慮size、圖檔類型; 視訊點播類要考慮視訊類型、播放器類型等)、使用者資訊(網絡制式、省份、營運商、城市)等。這些次元綜合作用影響關鍵名額,那麼哪些次元組合一定好,哪些一定不好?耗時類名額的表現往往呈現準正态分布趨勢,其長尾永遠存在并且無法消除,這種情況要不要關注? 針對指令字成功率,有些指令字成功率低是常态,要不要告警?過去我們會通過在監控中設定特例來避免告警。有沒有一種方法,能自動識别常态與非常态?在機器學習如火如荼的現在,也許可以試一試。
目标:
- 挖掘業務潛在規律(針對耗時這類連續值名額,找出引起長尾的因素)
- 監控業務名額時,找出常态并忽略常态,僅針對突發異常産生告警并給出異常的根因。
之後就是艱苦的屢敗屢戰,從入門到差點放棄,最終搞出第一個模型的奮戰史了。最大的困難是沒寫過代碼,不會python,機器學習理論和代碼都要同步學習;然後就是在基礎薄弱的情況下一開始還太貪心,想要找一個通用的模型,對不同業務、不同名額都可以通用,還可以同時解決兩個目标問題,缺少一個循序漸進入門的過程,難免處處碰壁,遇到問題解決問題,重新學習。好在最終結果還是出來了,不過還是要接受教訓:有了大目标後先定個小目标,理清思路後由點及面,事情會順利很多。
接下來直接介紹模型,過程中走的彎路就忽略掉(因為太多太弱了,有些理論是在遇到問題後再研究才搞明白)。
基本思路:
1.通過學習自動擷取業務規律,對業務表現進行預測(ET算法),預測命中的就是業務規律,沒命中的有可能是異常(請注意,是有可能,而非絕對);
2.将1的結果分别輸入決策樹(DT)進行可視化展示;用預測命中的部分生成業務潛在規律視圖;用未命中的來檢測異常,并展示根因。
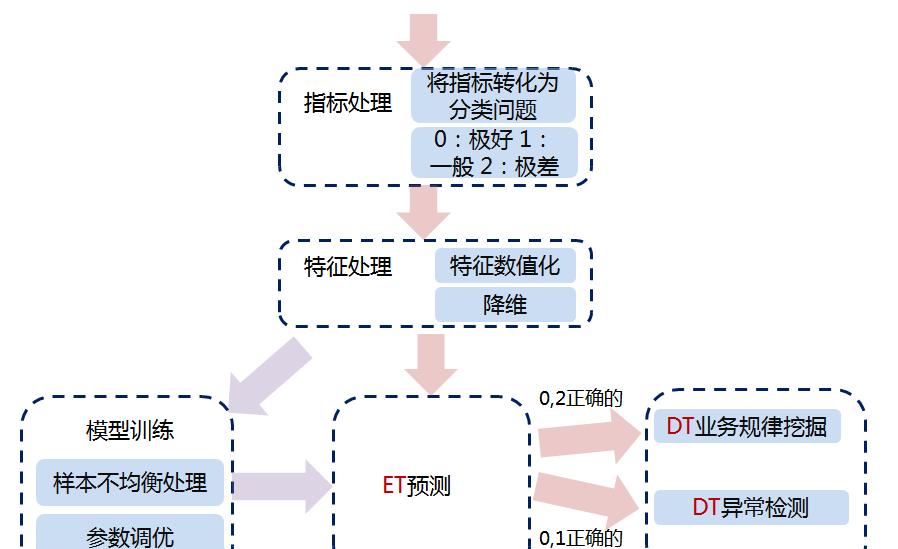
步驟簡介(以耗時這個名額為例):
1. 準備兩份不重合的資料,一份用于訓練,一份用于預測
例:視訊播放類業務的次元(如版本,機型,視訊來源,視訊編碼類型等各種已有特征),及耗時資料
2. 将目标問題轉化為分類問題,有可能是常見的二分類,也有可能是多分類,視情況而定
将耗時這種連續性名額轉為離散值,目标是産生三個分類:“極好的/0”,“一般的/1”,“極差的/2”,将耗時按10分位數拆分,取第1份(或者前2份)作為“極好的”樣本,中間幾份為“一般的”的樣本,最後1(或者2)份為“極差的“樣本 。 這裡的“極差的”其實就是正态分布的長尾部分。如下圖,第一列是耗時區間(未加人工定義門檻值,自動擷取),第二列是樣本量。

3. 特征處理
3.1 特征數值化
這裡表現為兩類問題,但處理方式都一樣:
(1)文本轉數值
(2)無序數值需要削掉數值的大小關系,比如Appid這類,本身是無序的,不應該讓算法認為65538>65537
方法:one-hot編碼, 如性别這個特征有三種取值,boy,girl和unknown,轉換為三個特征sex==boy,sex==girl,sex==unknown, 條件滿足将其置為1,否則置為0.
實作方式3種:自己實作;sklearn調包;pandas的get_dummies方法。
One-hot編碼後特征數量會劇烈膨脹,有個特征是手機機型,處理後會增加幾千維,同時也要根據情況考慮是否需要對特征做過于細化的處理。
3.2 特征降維
是否需要降維,視情況而定,我這裡做了降維,因為特征太多了,如果不降維,最終的樹會非常龐大,無法突出關鍵因素。
所謂降維,也就是需要提取出特征中對結果起到關鍵影響因素的特征,去掉不重要的資訊和多餘資訊,理論不詳述了,參考:http://sklearn.lzjqsdd.com/modules/feature_selection.html
本文用了ET的feature_importance這個特性做降維,将5000+維的資料降至300左右
4. 用ET算法(随機森林的變種,ExtraTreesClassifier)訓練一個分類模型(三分類)
4.1 評價模型的名額選取
對于分類算法,我們首先想到的準确性 precision這個名額,但它對于樣本不均衡的場景下是失效的。舉個例子,我們有個二分類(成功和失敗)場景,成功的占比為98%。這種樣本直接輸入訓練模型,必定過拟合,模型會直接忽略失敗的那類,将所有都預測為成功。此時成功率可達98%,但模型其實是無效的。那麼應該用什麼?
對于二分類,可用roc_auc_score,對于多分類,可用confusion_matrix和classification report
4.2 樣本不均衡問題處理
本文用的例子,顯然0和2的數量非常少,1的數量是大頭。為了不對1這種類型産生過拟合,可對0和2這兩類做過抽樣處理。
常見的有兩類算法:
(1)直接複制少數類樣本
(2)SMOTE過抽樣算法(細節略)
這裡兩種算法都用過,最終選了SMOTE,不過本文研究的資料上沒有看出明顯差别。
少數類的過抽樣解決了大類的過拟合問題,同時也帶來了小類的過拟合,不過這裡的模型正好需要讓小類過拟合,我們就是要把表現“極好”和“極壞”的部分找出來,表現平平的在異常檢測時加入關注。過拟合這個問題,不用過于恐懼,反而可以利用。舉個例子,“患病”和“不患病”這種分類場景,甯可将“患病”的檢出率高一些。如下圖這個分類報告,對于小類樣本(0和2),我們需要利用recall高的特性,即把它找出來就好;而對于大類樣本,我們需要precision高的特性,用于做異常檢測。
4.3 模型參數選取
Sklearn有現成的GridSearchCV方法可用,可以看看不同參數組合下模型的效果。對于樹類算法,常用的參數就是深度,特征個數;森林類算法加一個樹個數。
Max_depth這個參數需要尤其注意,深度大了,容易過拟合,一般經驗值在15以内。
4.4 模型訓練好後,用測試資料預測,從中提取各個類别預測正确的和不正确的。
例:
預測正确的部分:擷取預測為0,2,實際也為0,2的樣本标示;
預測錯誤的部分:擷取預測為0和1,實際為2的樣本标示(根據情況調節)
5. 輸入決策樹進行可視化展示,分别做業務規律挖掘和異常檢測
這裡DT算法僅用于展示,将不同類别的資料區分開,必要時仍然要設定參數,如min_samples_leaf, min_impurity_decrease,以突出關鍵資訊。
還可以通過DecisionTreeClassifier的内置tree_對象将想要找的路徑打出來
以下分别給出例子:
5.1 業務規律挖掘
視訊點播場景,取0和2這兩類預測正确的部分,輸入DT,如下圖,自動找出了業務潛在規律,并一一用大資料統計的方式驗證通過,結論吻合。這個樹的資料相對純淨,因為輸入給它的資料可以了解為必然符合某種規律。
5.2. 異常檢測
本文模型還在研究階段,未用線上真實異常資料,而是手工在測試資料某個次元(或者組合)上制造異常來驗證效果。
針對成功率,可以視容忍程度做二分類或者三分類。
二分類:取一個門檻值,如99%,低于99%為2,異常,否則為0正常。缺點是如果某個次元上的成功率長期在99%以下,如98%,當它突然下跌時會被當做常态忽略掉,不會告警。
三分類:99%以上為0, 96~99% 為1,低于96%為2,這種方式會更靈活。 三種分類也分别對應其重要性。重點關注,普通關注,忽略。
下圖是一個二分類的例子(手工将平台為IPH和播放端為client的置為異常):
最後:這裡隻是一次小嘗試,如果要平台化上線運轉,還要很多因素要考慮,首要就是模型更新問題(定時更新?避免選取到異常發生時段?),這個将放在下階段去嘗試。
相關閱讀
5分鐘教你玩轉 sklearn 機器學習(上)
機器學習概念總結筆記(一)
機器學習之離散特征自動化擴充與組合
此文已由作者授權騰訊雲技術社群釋出,轉載請注明文章出處
原文連結:https://cloud.tencent.com/community/article/477670
海量技術實踐經驗,盡在雲加社群!
https://cloud.tencent.com/developer