接《Amazon Aurora:雲時代的資料庫 ( 中)》
在這一節中,我們分享自2015年7月Aurora GA之後在生産環境營運的經驗。首先介紹标準的工業基準測試的結果,接着是一些來自客戶的性能測試結果。
我們使用标準的基準測試工具SysBench和TPC-C類似測試工具來進行測試,對比了Aurora和MySQL在不同場景下的性能表現。我們在帶有20K IOPS EBS的EC2執行個體上進行測試,除非特殊說明,這些執行個體的規格為32 vCPU,244G記憶體,Intel Xeon E5-2670 v2(Ivy bridge)處理器。執行個體上的buffer cache設為170G。
6.1.1 随執行個體規格擴充
在這個測試中,我們發現Aurora的吞吐量可以随着執行個體規格線性增長,在最高執行個體規格上吞吐量是MySQL5.6或者MySQL5.7的5倍。而Aurora目前是基于MySQL5.6的代碼庫的。我們在EC2 r3系列執行個體(large,xlarge,2xlarge,4xlarge,8xlarge)上運作1GB資料量大小(250張表)的隻讀或者隻寫的基準測試。R3系列的每個執行個體的vCPU和記憶體數量是下一個比它大的規格的一半。
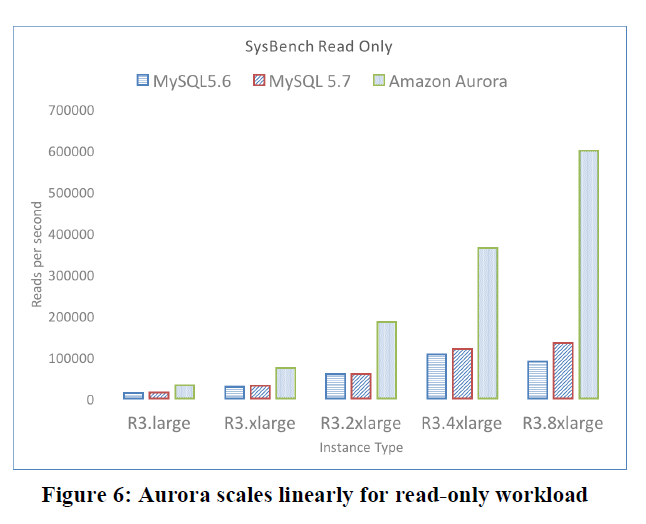

測試結果度量的是每秒鐘讀寫的語句數量,如圖6和圖7所示。Aurora的性能随着執行個體規格的提升而翻倍,在最大的r3.8xlarge的執行個體規格上可以獲得121K writes/sec和600K reads/sec,是MySQL5.7的20K writes/sec和 125K reads/sec的五倍。
6.1.2 不同資料集大小下的吞吐量
在這個測試中,我們發現Aurora的吞吐量遠大于MySQL,即使使用更大的資料集且包括cache之外的資料。表2展示使用SysBench的純寫入測試,使用100GB大小資料集Aurora可以比MySQL快67倍。即使是使用1TB包含Cache外資料的測試集,Aurora也比MySQL快34倍。
6.1.3 随使用者連接配接數擴充
在這個測試中,我們發現Aurora的吞吐量可以随着用戶端的連接配接數量而擴充。表3展示了運作SysBench OLTP基準測試的writes/sec結果,測試中連接配接數從50到500再到5000。Aurora可以從40K writes/sec擴充到110K writes/sec,MySQL的吞吐量在500個連接配接左右時達到峰值,然後随着連接配接數擴充到5000而急速下降。
6.1.4 随副本數擴充
在這個測試中,我們發現Aurora讀副本的延時比MySQL低很多,即使Aurora處在更高的負載情況下。表4展示了,随着負載從1K writes/sec到10K writes/sec,Aurora讀副本的延時從2.62ms增長到5.38ms。相反,MySQL讀副本的延時從1s增長到300s。在10K負載情況下,Aurora的副本延時比MySQL低幾個數量級。副本延時通過一個被送出的事務在副本上可見所需要的時間來度量的。
6.1.5 随Row Contention擴充
在這個測試中,我們發現相對于MySQL,Aurora在像TPC-C基準測試中有hot row contention的負載下也能表現的很好。我們在Aurora、MySQL5.6、MySQL5.7上運作Percona TPC-C類似工具,運作執行個體規格為r3.8xlarge挂載IOPS為30K的EBS。表5展示了Aurora可以保持相對MySQL5.7 的2.3倍到16.3倍的吞吐量,負載從10GB數量、500個連接配接,到100GB資料、5000個連接配接。
在這一小節中,我們分享一些客戶在生産環境從MySQL遷移到Aurora的測試結果。
6.2.1 應用程式在Aurora的響應時間
一個網際網路遊戲公司将生産環境的服務從MySQL遷移到r3.4xlarge執行個體的Aurora上。在遷移之前,網絡事務的平均響應時間為15ms。與之對應的,遷移之後的平均響應時間為5.5ms,差不多有了3倍的提升,如圖8所示。
6.2.2 Aurora中執行語句的延時
一個教育公司主要業務是幫助學校管理學生的筆記本電腦,将他們的服務從MySQL遷移到了Aurora。Select和單條記錄insert語句在遷移前的中位點和95分位點如圖9和圖10所示。
在遷移之前,95分位延時在40ms到80ms之間,比中位點1ms差得遠了。本文之前介紹了,應用程式會遇到這種少數性能極差的情況。在遷移之後,95分位的延時顯著降低,接近中位點延時。
6.2.3 多個副本下的複制延時
如Pinterest的Weiner所指出的,MySQL副本經常遠落後于他們的寫副本,會引起非常奇怪的bug。對于上面提到的那個教育公司,副本延時有時可能飙升到12分鐘而影響到應用程式的正确性,是以這些副本隻能作為一個備機。與之相對的,在遷移到Aurora之後,4個副本集的複制延時從未超過20ms,如圖11所示。複制延時的顯著改善讓這家公司轉移了一大部分應用程式的負載到隻讀副本上,既節約了成本又提高了可用性。
我們遇到過運作各種各樣的應用的客戶,從小的網際網路公司到大型的組織機構。他們很多的使用場景都是标準的,這裡我們重點放在在雲服務中比較常見的場景和期望,而這些導緻我們走向了新的方向。
很多我們的客戶都經營SaaS服務,自己使用或者為他們自己的客戶提供SaaS模型的服務。我們發現這些客戶依賴的應用程式很難被改變。因而,他們通常将自己的很多客戶集中在某一個執行個體上,使用庫或者表來作為租賃的基本機關。這種模式可以節約成本:由于他們自己的客戶不太可能同時使用,這樣可以避免為每個客戶申請一個單獨的執行個體。舉個例子,我們有些客戶稱他們自己有超過50K的客戶。
這個模型與Salesforce.com著名的多租戶應用場景有很大的不同,他們将資料打包到一個統一的表中,按行來租賃。因而,我們發現很多客戶有很多張表。生産環境中資料庫表超過150K是非常常見的。這給一些管理中繼資料的元件,如字典cache,帶來很大壓力。更重要的是,這些客戶需要(a)保持高吞吐量和連接配接數,(b)存儲容量按使用擴充和收費,因為很難提前預知需要多大的存儲,(c)減少抖動,這樣一個租戶的峰值對其他租戶的影響很小。Aurora支援所有的這些特性,而且很适合SaaS應用。
網際網路的負載通常需要應對突發事件引起的網絡流的尖峰。我們有個重要客戶在一個很火的全國電視節目時,遇到過一次遠超過平時負載吞吐量高峰的流量,不過沒有對資料庫構成壓力。為了支援這樣的突發流量,資料庫需要同時能處理很多并發的請求。Aurora在這種場景下也能處理的很好,因為它的底層存儲系統擴充性極好。我們有很多客戶每秒鐘的連接配接數超過8000次。
現代Web應用程式架構如Ruby on Rails深入內建了ORM工具。因而,應用程式可以很友善的改變資料庫的schema,然而卻讓DBA們很難把握schema會如何演進。在Rails應用程式中,這些稱之為DB遷移,我們聽到一線的DBA稱他們一周可能會有幾十次DB遷移,或者會提前準備好政策來讓未來的變更會比較容易。這些問題在MySQL中被放大,因為MySQL提供自由的schema變更語義,使用整表拷貝的方式來實作大多數變更。既然頻繁的DDL是一個現實問題,我們在Aurora中實作了高效的線上DDL,(a)為每一個資料頁關聯一個schema版本,通過schema的變更曆史來解碼單個資料頁,(b)用modify-on-write的方式按需将單個資料頁更新到最新的schema。
客戶對雲上的資料庫的一些迫切的期待與我們如何營運系統和如何給伺服器更新可能是互相沖突的。由于我們的客戶主要用Aurora來作為一個OLTP服務支撐線上應用程式,任何的幹擾都可能導緻嚴重的後果。因而,很多客戶對我們更新資料庫軟體的容忍度是非常低的,即使在六周内隻計劃30s的服務暫停時間也不行。我們近期釋出了一個Zero Downtime Patch ZDP特性,使得我們可以在保證已有的資料庫連接配接不受幹擾的情況下,更新伺服器。
如圖12所示,ZDF的原理是,首先找到一個沒有活動連接配接的執行個體,将執行個體的應用程式狀态導出到持久化存儲中,給引擎更新,然後導入應用程式狀态。在這個過程中,使用者的session不受影響,對引擎的更新是無感覺的。
在本節中,我們介紹其他人的貢獻以及它們如何Aurora中采用的方案關聯的。
存儲計算分離。盡管傳統的資料庫系統都會被構造成一個龐然大物,近期有一些資料庫方面的工作将核心解耦為不同的元件。舉個例子,Deuteronomy10就是這樣的系統,它分離了提供并發控制的事務元件,和提供恢複功能建構在LLAMA34的資料元件,其中LLAMA是一個無鎖、日志結構的緩存和存儲管理器。Sinfonia39和Hyder40這些系統将事務的方法抽象成一個可擴充的服務,資料庫系統的實作可以使用這些抽象。Yesquel36實作了一個多版本的分布式平衡樹,将并發控制和查詢處理器分開。Aurora比Deuteronomy、Sinfonia、Hyder和Yesquel在更低的層次将存儲解耦出來。在Aurora中,查詢處理器、事務、并發控制、buffer cache和通路方式是與日志、存儲、故障恢複解耦的,後者被實作為可擴充的服務。
分布式系統。在分區的條件下,正确性和可用性的折中,以及one-copy序列化是不可能的是CAP理論裡有名的結論。更近一些的,Brewer的CAP理論在16中證明得到結論:一個高度可用的資料庫系統在網絡隔離的情況下不可能提供強一緻性。這些結論以及我們對雲級别規模的複雜且互相關聯故障的經驗,促使我們定下即使在一個AZ不可用的條件下仍然保持一緻性的設計目标。
Bailies等人12研究了高可用事務HATs,HAT既不會受網絡分區導緻的不可用的影響,又不會導緻高的網絡延時。他們的工作說明了Serializability,Snapshot Isolation, Repeatable Isolation不是HTA相容的。Aurora提供所有這些隔離級别,基于一個簡化的前提:在任意一個時間點,隻有一個寫副本在生成日志,這些日志的LSN在同一個有序空間裡配置設定。
Google的Spanner24提供外部一緻25的讀和寫,全局一緻的指定時間點的讀。這些特性可以讓Spanner提供全局的一緻的備份,全局的一緻的分布式查詢處理,全局的原子的schema更新,即使是在有事務正在執行的情況下。就像Bailis所描述的,Spanner是為Google讀負載高的場景定制的,在讀和寫的時候依賴于兩階段送出和兩階段鎖。
并發控制。 弱一緻性17以及隔離模型18在分布式資料庫中是衆所周知的,也導緻了樂觀複制技術19和最終一緻性系統的出現。集中式系統的一些方案包括,經典的悲觀鎖方式,如Hekaton29中的MVCC的樂觀鎖方式,如VoltDB30中的分片模式,Hyper31中的時間戳序列模式,還有Deuteronomy。Aurora的存儲服務為資料庫引擎提供了一個本地盤的抽象,讓引擎來決定隔離級别和并發模式。
日志結構的存儲。日志結構的存儲在1992年首先出現在LFS33中。最近的Deuteronomy以及LLAMA34中的相關工作,還有Bw-Tree35在存儲引擎棧中以多種形式使用了日志結構的技術,像Aurora一樣,它們通過隻寫資料頁的變更來減少寫放大。Deuteronomy和Aurora實作的都是純粹的REDO日志方式,并跟蹤事務确認回複的最大的LSN。
故障恢複。傳統的資料庫都依賴于類似ARIES5的恢複協定來實作故障恢複,近期很多系統為性能的考慮選擇了其他的路徑。舉個例子,Hekaton和VoltDB使用某種更新日志來重建它們的記憶體狀态。類似Sinfonia39的系統,使用process pairs和狀态機複制技術來避免故障恢複。Graefe41介紹了使用每頁的日志記錄鍊來加快按需的page-by-page的REDO以加快恢複速度。跟Aurora一樣,Deuteronomy不需要REDO恢複,這是因為Deuteronomy隻會将已經送出的更新寫入存儲。因而,不像Aurora,Deuteronomy裡的事務數量是受限制的。
我們在雲環境下将Aurora設計為一個高吞吐量的OLTP資料庫,不犧牲可用性和可持久性。主要的思想是避免傳統資料庫龐大複雜的結構,将存儲和計算解耦。具體來說,我們将資料庫核心最下面一小部分移到一個獨立可擴充分布式的負責日志記錄和存儲資料的存儲服務中。由于這時所有的IO都通過網絡,我們最根本的限制變成了網絡。因而,我們将重點放在緩解網絡開銷、增加吞吐量的技術上。我們依賴的技術有:多數派模型—可以處理在大規模雲服務環境下複雜關聯的故障,避免最差性能點的懲罰,通過日志處理來減少整體的IO負擔,異步的一緻性來避免溝通複雜且代價昂貴的多階段同步協定,離線故障恢複,在分布式存儲中建立檢查點。我們的方案能得出一個簡化的複雜度降低的系統,可以很友善的擴充,并為以後的演進奠定基礎。
在此,我們對Aurora開發團隊的所有成員的努力表示感謝,包括現有的成員,以及我們優秀的同僚們(James Corey,Sam Mckelvie,Yan Leshinsky, Lon Lundgren, Preadeep Madhavarapu, Stefano Stefani)。我們要特别感謝我們的客戶,他們在生産環境使用我們的服務,并且給我們分享他們的經驗和期望。同時,我們也要感謝評審們的寶貴意見。