最近趁着不忙,在構思一個搭建一個開源的完整項目,至于原因以及整個項目架構後邊文章我再說明。既然要起一個完整的項目,那麼資料倉儲通路就必不可少,這篇文章我主要介紹這個新項目(OSS.Core)中我對倉儲層的簡單思考和實作過程(目前項目還處在搭建階段),主要集中在以下幾個方面:
1. 資料倉儲層的需求 2. ORM架構選擇 3. OSS.Core倉儲層設計實作 4. 調用示例
下邊的實作部分中可能需要你對.NET的 泛型,委托,擴充,表達式等有一個基礎了解。正是因為這些語言特性,友善我們對操作共性的抽取統一。
一. 資料倉儲層需求
既然是一個完整的項目,資料通路是其最基本的部分,同時,資料通路也是整個項目最容易出現瓶頸的地方。在我的劃分中,其承擔的角色是負責整個資料的輸入輸出,不僅僅是針對單資料庫(有時甚至多庫),有時還需要完成一級緩存的實作,給邏輯層提供最基礎的資料支撐。
業務永遠是在變化的,那麼項目也要具備快速演進的能力,是以我希望資料層能夠保持相對的簡單,在結構上盡量減少複雜的耦合查詢,在性能上盡量減少不必要的消耗,例如反射的大量使用。同時針對每個業務對象完成資料庫層面基本的CRUD統一封裝實作。如果有需要的時候還能在最少的改動下加入緩存的更新。(對于如何實作不同子產品不同緩存存儲政策,像Redis,Memcached會在後邊文章介紹)
同時,對于一個稍微有點規模的項目來說,解決資料庫通路的最快速做法就是實作讀寫分離,是以,我希望這個架構能夠在一開始在底層就實作了讀寫分離的支援,以避免後期再重頭對業務代碼的大量修改。
二. ORM 架構選擇
當然,如果為了簡單和性能,直接ADO.NET連接配接理論上來說是比較高效的做法,不過這樣會造成大量的重複操作邏輯代碼,同時也會造成代碼的散亂,增加維護複雜度。作為技術人員,不僅需要解決業務問題提高效率,同時也要提高自己的效率,是以我會選擇一個ORM架構來完成部分基礎工作。
目前在.NET體系下,開源的ORM架構很多,如:Entityframework,NHibernate,iBATIS.NET,Dapper等等,各有特色,基于前面我說的,保證效率的同時,兼顧簡單還能最大程度減少性能的損耗,并且提供.net standard标準庫下的支援。這裡對比之後我選擇Dapper這個半自動化的ORM作為倉儲層的基礎架構,選擇原因如下:
1. 其結構簡單,整個封裝主要集中Dapper.cs檔案中,體積很小
2. 封裝功能簡單強大,對原生SQL的支援上很靈活
這點幾乎完勝其他架構,無需任何多餘的設定,同時基本上你可調用所有原生ADO.NET的功能,sql語句完全自己掌控,卻又無需關心command的參數指派,以及結果實體轉換等。
3. 性能上的高效
很多ORM的實體映射通過反射來完成,這點上Dapper再次展現其魅力,在Commond參數指派,以及實體轉換等關鍵子產品,使用了Reflection.Emit功能,間接實作了MSIL編譯層面的指派實作,之是以說間接,是因為其本身代碼還需要編譯器生成IL代碼。在運作時根據類型屬性動态建立指派委托方法。
三. OSS.Core倉儲層設計實作
通過Dapper可以實作在資料庫通路部分一層簡單的封裝,不過我依然需要手動編寫不少的sql語句,同時還要進行參數化的處理,包括資料的讀寫分離等。那麼這些功能的實作我将在OSS.Core.RepDapper中完成,為了友善了解,先貼出一個簡單的封裝後的方法調用傳輸流程:
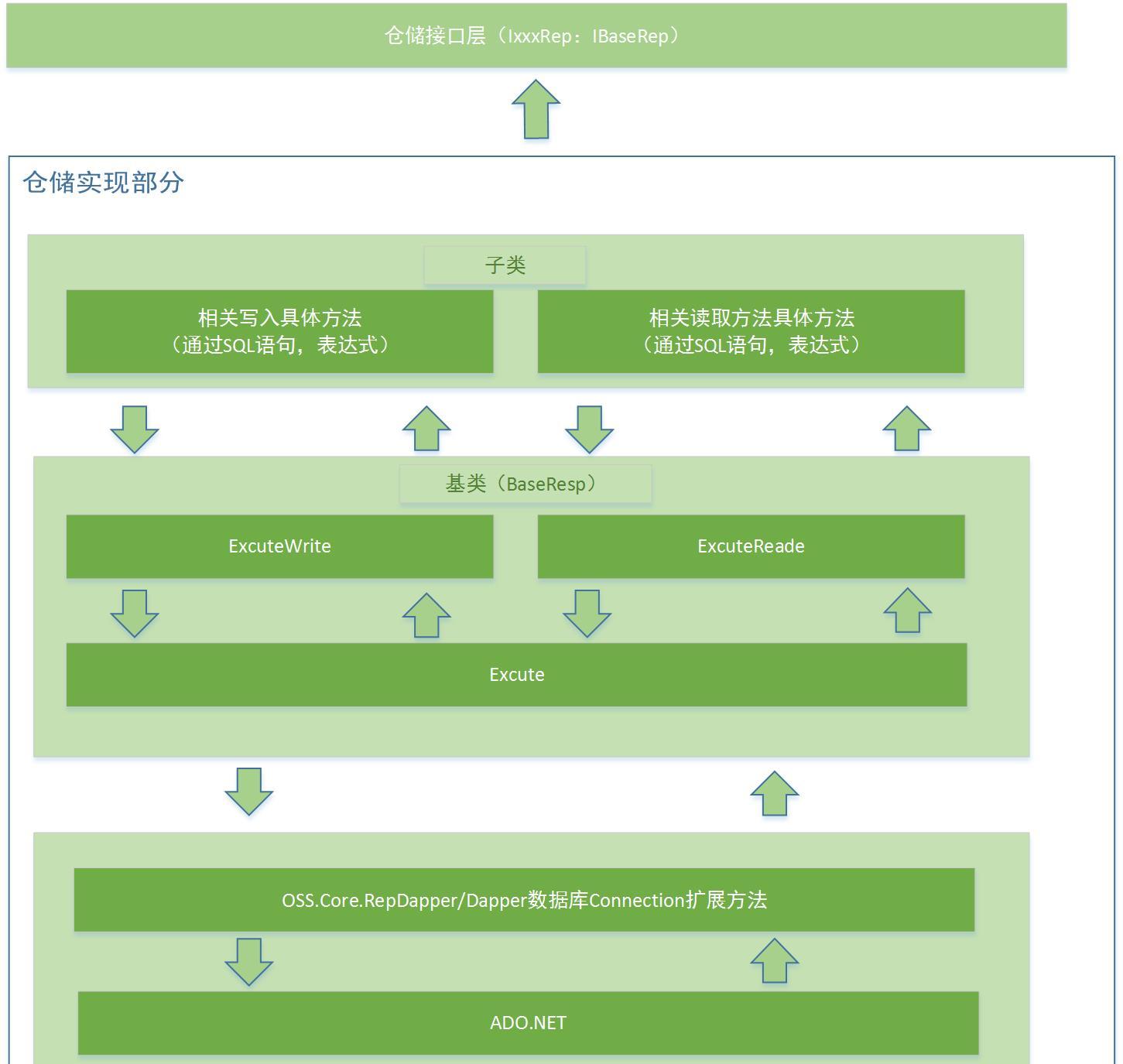
在這個圖裡展示一個簡單的方法調用流程,圍繞這張圖的幾個核心部分,我分别介紹下:
1. 接口設計
因為我希望這個是完整的示例項目,是以後邊希望能夠相容不同資料庫,是以對外的倉儲通路都基于接口調用。當然如果你的項目根本沒有切換資料庫的需求,我更建議去掉這一環節,直接在基類中實作單例模式,業務邏輯層直接調用。
圖中可以看到接口層獨立于實作部分,我将具體業務實體模型和接口 單獨放在了OSS.Core.DomainMos 類庫中,一方面是為了實體模型在各子產品中的共用,另一方面解耦業務邏輯層(Services)和倉儲層(Reps)之間的依賴關系。
同時一個項目中資料庫通路代碼多數都會以CRUD為主,是以這裡我定義了一個基礎接口(IBaseRep),其包含的方法主要有(表達式部分在後邊介紹):

具體的業務資料接口繼承至基礎接口就好,其中表達式部分是我自己做了一個封裝,後邊會簡單介紹。
2. 倉儲基類實作(BaseRep)
首先,如圖所示,我們實作了讀寫分離的兩個擴充,其實最終都會經過Excute方法,那麼這裡展示下方法的具體實作:
可以看到在這個方法提供了一個針對IDbConnection的委托,提供調用層自由使用Dapper方法的同時,統一了資料通路方法入口,便于日志記錄,和排查。
其次,在很多項目中會出現使用者和訂單在不同庫中的這類情況,因為涉及到分庫的情況,是以需要子類中能有修改連接配接串能力,那麼這裡我通過構造函數的形式,提供了兩個可空參數:
可以看到,如果子類中定義了自己的連接配接串,則以子類自定義為主,否則走預設的連接配接資訊。
最後,我們也實作了針對基礎接口方法的具體實作,舉一示例:
同時,為了保證子類中能夠加入緩存處理,是以采用了虛方法(virtual)的形式,保證子類能夠重寫。
3. 基于Connection的擴充
這個地方主要分為兩個部分,a. 表達式的解析,以及參數化的處理 b. 擴充Connection的Insert,Update...等Dapper沒有擴充的方法:
a. 熟悉Expression表達式的朋友應該比較了解,表達式本身是一個樹形接口,根據不同的類型,可以不斷的解析其子表達式,直到不具備繼續解析的可能。是以這個就很簡單就是遞歸的不斷疊代,根據其不同的NodeType可以組裝不同的sql元素,因為代碼較長,可以參見github下的SqlExpressionVisitor.cs類,其中參數的指派部分,沒有采用反射,而是使用的反射發射,代碼詳見SqlParameterEmit.cs
b. 有了表達式的擴充之後,就可以擷取對應的sql和參數,通過this擴充Connection方法即可,代碼見ConnoctionExtention.cs
四. 調用示例
1. 我們定義一個簡單UserInfoMo實體(包含mobile等屬性)
2. 定義接口 IUserInfoRep: IBaseRep
3. 定義實作類 UserInfoRep : BaseRep, IUserInfoRep
在不添加其他代碼的基礎上,我們就可以完成下面的調用:
本文轉自xmgdc51CTO部落格,原文連結: http://blog.51cto.com/12953214/1942916,如需轉載請自行聯系原作者