文本聚類是文本處理領域的一個重要應用,其主要目标是将給定的資料按照一定的相似性原則劃分為不同的類别,其中同一類别内的資料相似度較大,而不同類别的資料相似度較小。聚類與分類的差別在于分類是預先知道每個類别的主題,再将資料進行劃分;而聚類則并不知道聚出來的每個類别的主題具體是什麼,隻知道每個類别下的資料相似度較大,描述的是同一個主題。是以,文本聚類比較适合用于大資料中熱點話題或事件的發現。
文智平台提供了一套文本聚類的自動化流程,它以話題或事件作為聚類的基本機關,将描述同一話題或事件的文檔聚到同一類别中。使用者隻需要按照規定的格式上傳要聚類的資料,等待一段時間後就可以獲得聚類的結果。通過文本聚類使用者可以挖掘出資料中的熱門話題或熱門事件,進而為使用者對資料的分析提供重要的基礎。本文下面先對文本聚類的主要算法作介紹,然後再具體介紹文智平台文本聚類系統的原理與實作。
文本聚類需要将每個文檔表示成向量的形式,以友善進行相似度的計算。詞袋模型(bag of words,BOW)是文本聚類裡面的一種常用的文檔表示形式,它将一個文檔表示成一些詞的集合,而忽略了這些詞在原文檔中出現的次序以及文法句法等要素,例如對于文本“北京空氣重污染拉響黃色預警”,可以表示為詞集{北京,空氣,污染,黃色,預警}。通過詞袋模型将文檔轉化為N維向量,進而構造整個文檔集合的詞語矩陣,就可以使用一些數值運算的聚類算法進行文本聚類。
當然,并不是所有的詞都用來建構文檔的詞向量,可以去掉一些像a、an、the這樣的出現頻率很高而又無實際意義的詞,這樣的詞沒有什麼類别區分能力,應作為停用詞而去掉。另外,可以使用TF-IDF等方法來評估一個詞對于文檔的重要程度,保留對文檔較為重要的詞作為詞向量之用。
以詞袋模型為基礎,将文檔表示成N維向量,進而可以利用相關的聚類算法進行聚類計算。常用的文本聚類算法有層次聚類算法、劃分聚類算法(例如k-means、k-medoids算法)以及基于主題模型的聚類算法(例如PLSA、LDA)等。
層次聚類算法是對給定的資料集進行層次的分解,直到達到某個終止條件為止。具體可以分為凝聚和分裂兩種方式。凝聚是自底向上的政策,首先将每個對象作為一個類别,然後根據對象之間的相似度不斷地進行合并,直到所有對象都在一個類别中或是滿足某個終止條件;而分裂則與凝聚相反,用的是自頂向下的政策,它首先将所有對象都放到一個類别中,然後逐漸分裂為越來越小的類别,直到每個對象自成一個類别或是滿足某個終止條件。大多數的層次聚類算法都采用凝聚的方式,這裡就以凝聚的方式為例對算法進行介紹。
層次聚類算法的輸入是資料集中所有對象的距離矩陣,并預先設定一個距離門檻值
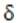
,用于疊代的終止,算法的主要步驟如下:
将每個對象作為一類,類與類之間的距離就是它們所包含的對象之間的距離
找出距離最接近的兩個類,如果它們的距離小于
,則将它們合并為一類
重新計算新的類與所有其它舊類之間的距離
重複第2步和第3步,直到所有的類無法再進行合并為止
其中步驟3中類與類之間距離的計算方法有3種,分别為:
Single Linkage:類間距離等于兩類對象之間的最小距離,這種方法計算簡便,但是容易導緻兩個類從大範圍看是比較遠的,卻由于個别的點比較近而被合并的情況,而且這種情況還會不斷擴散,最後造成類别比較松散
Complete Linkage:類間距離等于兩類對象之間的最大距離,這種方法有時也不太好,容易導緻兩個比較近的類由于存在一些較遠的點而老死不合并
Group-AverageLinkage:類間距離等于兩類對象之間的平均距離,前面兩種方法的不足都是由于隻考慮了類内資料的局部情況,而缺乏整體上的考慮,取平均距離能夠改善前面兩種方法的不足,但是計算量相應也有所增加。
層次聚類算法的優點是計算速度較快,并且不需要指定最終聚成的類别個數,但是需要預先指定一個距離門檻值作為終止條件,這個距離門檻值的設定需要一定的先驗知識。
劃分聚類算法中有代表性的算法是k-means算法和k-medoids算法,這裡以較為常用的k-means算法為代表進行介紹。
k-means算法是基于距離的聚類算法,輸入是資料集中所有文檔的詞向量矩陣,需要預先指定最終聚成的類别個數k,并且還需要指定算法疊代終止的條件,這可以通過指定疊代的次數或是指定前後兩次疊代中k個質心距離變化的總和小于一定門檻值作為算法疊代終止的條件。k-means算法的主要步驟如下:
初始條件下,随機選取k個對象作為初始的質心
計算每個對象到k個質心的距離,将對象歸到距離最近的質心的類中
重新計算各個類的質心,取類中所有點的平均值作為該類新的質心
重複第2步和第3步,直到達到指定的疊代次數或是新舊質心距離變化之和小于指定門檻值
k-means算法需要預先指定聚成類别的數目k,這需要一定的先驗知識,而且算法疊代終止條件的設定也是要根據一定的經驗。另外,算法初始質心的選取會影響到最終的聚類結果,有不少文獻都在研究優化k-means算法初始質心的選取。
基于主題模型的聚類算法是假定資料的分布是符合一系列的機率分布,用機率分布模型去對資料進行聚類,而不是像前面的層次聚類和劃分聚類那樣基于距離來進行聚類。是以,模型的好壞就直接決定了聚類效果的好壞。目前比較常用的基于主題模型的聚類算法有LDA和PLSA等,其中LDA是PLSA的一個“更新”,它在PLSA的基礎上加了Dirichlet先驗分布,相比PLSA不容易産生過拟合現象,LDA是目前較為流行的用于聚類的主題模型,這裡以LDA為代表介紹基于主題模型的聚類算法。
LDA(Latent Dirichlet Allocation,隐含狄利克雷配置設定),是一種三層貝葉斯機率模型,它由文檔層、主題層和詞層構成。LDA對三層結構作了如下的假設:
整個文檔集合中存在k個互相獨立的主題
每一個主題是詞上的多項分布
每一個文檔由k個主題随機混合組成
每一個文檔是k個主題上的多項分布
每一個文檔的主題機率分布的先驗分布是Dirichlet分布
每一個主題中詞的機率分布的先驗分布是Dirichlet分布

圖1 LDA三層模型結構
LDA模型的訓練過程是一個無監督學習過程,模型的生成過程是一個模拟文檔生成的過程,文檔中的一個詞首先是根據一定的主題機率分布抽取出一個主題,然後是從這個主題中以一定的機率分布抽取出一個詞,如此重複,直到生成文檔中所有的詞。LDA在模型中以Dirichlet分布為基本假設,其生成過程如圖2所示。
圖2 LDA的模型生成過程
在實際的應用中,可以通過Gibbs Sampling來對給定的文檔集合進行LDA訓練。首先是使用者需要設定生成的模型的主題個數k,然後是對給定的文檔進行分詞,去掉停用詞,獲得文檔的詞袋模型,作為訓練的輸入。
圖3 使用Gibbs Sampling的LDA訓練過程
LDA中隐含的變量包括文檔的主題分布Θ、主題的詞分布Φ以及詞所屬的主題Z。Gibbs Sampling通過不斷的抽樣與疊代,推算出這些隐含變量。如圖3所示,Gibbs Sampling在初始時随機給每個詞配置設定主題z(0),然後統計每個主題z下出現詞t的數量以及每個文檔m下出現主題z中的詞的數量,再計算
,即排除目前詞的主題分布,根據其它詞的主題分布來估計目前詞配置設定到各個主題的機率。當得到目前詞屬于所有主題的機率分布後,再根據這一機率分布為該詞抽樣一個新的主題z(1)。然後用同樣的方法不斷更新下一個詞的主題,直到文檔的主題分布Θ和主題的詞分布Φ收斂或是達到預定的疊代次數為止。最終輸出所有的隐含變量,每個詞所屬的主題也能夠得到。根據每個詞所屬的主題分布,就可以進一步計算出每個文檔所屬的主題及其機率,這就是LDA聚類的結果。
在上一節中我們介紹了常用的文本聚類算法,其中層次聚類算法和k-means算法等都是基于距離的聚類算法,而LDA則是使用機率分布模型來進行聚類。基于距離的聚類算法的優點是速度比較快,但是它們都是通過兩個文檔共同出現的詞的多少來衡量文檔的相似性,而缺乏在語義方面的考慮。相反,LDA等基于模型的聚類算法能夠通過文本中詞的共現特征來發現其中隐含的語義結構,對“一詞多義”和“一義多詞”的現象都能夠模組化,并在聚類結果中得到展現。“一詞多義”就例如“蘋果”一詞,它可能是指水果,可能是指手機,也可能是指公司,LDA能夠将其配置設定到不同的主題中;而“一義多詞”就例如衆多的同義詞,它們雖然在文本上并不相似,但是在語義上是相似的,LDA能夠将它們聚集到一起。正是由于LDA在語義分析方面的優勢,我們文智平台的聚類系統使用LDA來進行文本聚類。但是LDA在訓練中會比較耗時,單機情況下300萬的文檔資料訓練需要100多個小時,這是不能接受的,是以需要對LDA做并行化計算。
Spark是繼Hadoop之後新一代的大資料并行計算架構,是目前大資料分析的利器。相比于傳統的Hadoop MapReduce,Spark将計算時的中間結果寫到記憶體中,而不是寫磁盤,而且在同一個任務中可以重複利用task對象,而無需重新建立,這使得Spark非常适合應用于類似LDA這樣的需要反複疊代的算法中。
圖4 Spark任務執行總體架構
Spark在任務的執行上也是跟Hadoop類似,通過一定的任務管理器和排程器将任務配置設定給各個節點來并行化執行,進而能夠取得比單機環境下快數十倍的計算效率,如圖4所示。對于LDA,其訓練過程主要是Gibbs Sampling,目前已經有對LDA中Gibbs Sampling進行并行化的方法。具體地說,就是将訓練資料分成多份,配置設定給每個節點進行獨立的并行化訓練,訓練完成後再更新全局模型,然後再根據全局模型進行下一輪的疊代訓練,如此重複,直到任務結束,如圖5所示。
圖5 LDA并行化計算
在Spark中實作上述的LDA并行化流程,可以極大地提升LDA的計算效率,訓練300萬的文檔資料由原來的需要100多個小時減少到隻需5到6個小時。
文智平台文本聚類系統的整體架構如圖6所示,主要分為接入層、計算層和存儲層三層。使用者通過前台頁面按照規定的格式上傳資料檔案,然後在計算層首先會對資料進行預處理,去除無效資料,接着使用Spark對資料進行LDA聚類,這是一個反複疊代的過程。使用者可以指定生成的主題個數以及疊代的最大次數,如果使用者不指定我們也會有預設值。LDA聚類得到的結果再經過簡單的統計和排序整理就能夠生成資料中的熱門話題,熱門話題和聚類結果最後會傳回給使用者。整個計算層的操作都是無需使用者參與的,使用者隻需要上傳資料檔案,然後等待一段時間後就可以獲得文本聚類的結果。
圖6 文本聚類系統整體架構
文智平台基于Spark的LDA聚類系統能夠快速而有效地對資料進行聚類,聚類的平均準确率達到80%以上,而且經過對Spark平台的不斷優化,聚類的效率也在不斷提高,表1中所示的是系統目前聚類的性能情況,後續還會在性能方面對系統不斷進行優化。
表1 基于Spark的LDA聚類系統性能情況
文智平台文本聚類系統使用Spark對文本資料進行LDA聚類,可以從語義的層面上挖掘出使用者資料中的熱門話題。系統的應用範圍非常廣泛,可以應用于各類文本資料,尤其是對海量社交資料的分析非常有效。這一整套使用LDA進行文本聚類的機制目前已經較為成熟,已經在為公司内的一些部門提供文本聚類服務,我們期待今後系統能得到更為廣泛的應用。