關鍵詞是指能反映文本主題或者意思的詞語,如論文中的Keyword字段。大多數人寫文章的時候,不會像寫論文的那樣明确的指出文章的關鍵詞是什麼,關鍵詞自動标注任務正是在這種背景下産生的。
目前,關鍵詞自動标注方法分為兩類:1)關鍵詞配置設定,預先定義一個關鍵詞詞庫,對于一篇文章,從詞庫中選取若幹詞語作為文章的關鍵詞;2)關鍵詞抽取,從文章的内容中抽取一些詞語作為關鍵詞。
在文獻檢索初期,由于當時還不支援全文搜尋,關鍵詞就成為了搜尋文獻的重要途徑。随着網絡規模的增長,關鍵詞成為了使用者擷取所需資訊的重要工具,進而誕生了如Google、百度等基于關鍵詞的搜尋引擎公司。
關鍵詞自動标注技術在推薦領域也有着廣泛的應用。如圖1所示,當使用者閱讀圖中左邊的新聞時,推薦系統可以給使用者推薦包含關鍵詞”Dropbox”、”雲存儲”的資訊,同時也可以根據文章關鍵詞給使用者推薦相關的廣告。
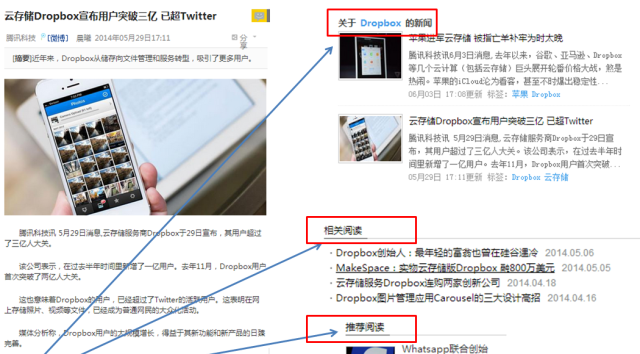
圖1基于關鍵詞的資訊推薦系統
關鍵詞可以作為使用者興趣的特征,進而滿足使用者的長尾閱讀興趣。傳統的資訊訂閱系統一般使用類别或者主題作為訂閱的内容,如圖2所示。如果使用者想訂閱更細粒度的内容,這類系統就無能為力了。關鍵詞作為一種對文章更細粒度的描述,剛好可以滿足上述需求。

圖2傳統的訂閱系統
除了這些以外,關鍵詞還在文本聚類、分類、摘要等領域中有着重要的作用。比如在聚類時,将關鍵詞相似的幾篇文章看成一個類團可以大大提高K-means聚類的收斂速度。從某天所有新聞中提取出這些新聞的關鍵詞,就可以大緻知道那天發生了什麼事情。或者将某段時間中幾個人的微網誌拼成一篇長文本,然後抽取關鍵詞就可以知道他們主要在讨論些什麼話題。
文章的關鍵詞通常具有以下三個特點[1]:
可讀性。關鍵詞本身應該是有意義的詞或者短語。例如,“我們約會吧”是有意義的短語,而“我們”則不是。
相關性。關鍵詞必須與文章的主題相關。例如,一篇介紹巴薩在德比中輸給皇馬的新聞,其中可能順帶提到了“中超聯賽”這個關短語,這時就不希望這個短語被選取作為該新聞的關鍵詞。
覆寫度。關鍵詞集合能對文章的主題有較好的覆寫度,不能隻集中在文章的某個主題而忽略了文章的其他主題。
從上述三個特點,可以看到關鍵詞标注算法的要求以及面臨的挑戰:
a.新詞發現以及短語識别問題,怎樣快速識别出網絡上最新出現的詞彙(人艱不拆、可行可珍惜…)?
b.關鍵詞候選集合的問題,并不是文章中所有的詞語都可以作為候選
c.怎麼計算候選詞和文章之間的相關性?
d.如何覆寫文章的各個主題?
關鍵詞配置設定算法需要預先定義一個關鍵詞詞庫,這就限定了關鍵詞候選範圍,算法的可擴充性較差,且耗時耗力;關鍵詞抽取算法是從文章的内容中抽取一些詞語作為标簽詞,當文章中沒有品質較高的詞語時,這類方法就無能為力了。為了解決上述這些問題和挑戰,我們設計了階層化關鍵詞自動标注算法.
針對新聞的關鍵詞識别任務,我們設計了一套階層化的關鍵詞體系,如圖3所示。第一層是新聞頻道(體育、娛樂、科技、etc),第二層是新聞的主題(一篇新聞可以包含多個主題),第三次是文章中出現的标簽詞。
圖3階層化關鍵詞體系
三層關鍵詞體系有以下幾個優點:
三層關鍵詞體系從不同角度描述文章所表達的内容,進而能讓标注結果能更好地覆寫文章的各個主題,緩解了關鍵詞覆寫度不夠的問題。
由于各層之間有隸屬關系,利用這種關系,可以抽取出更相關的關鍵詞,如:“非誠勿擾”在娛樂新聞中可能是指娛樂節目或者電影,可以作為一個關鍵詞;如果是出現在汽車新聞中,則不太可能是文章的關鍵詞。
圖4階層化關鍵詞自動标注結果示例
從圖3中可以看出,主題和标簽詞依賴于新聞頻道,是以在标注一篇新聞的關鍵詞時,首先需要擷取新聞的類别,然後根據新聞的類别選擇不同的主題模型預測新聞的主題,最後再抽取新聞中的标簽詞。
在關鍵詞标注方法上,我們融合了關鍵詞配置設定和關鍵詞抽取兩類方法。圖5描述了算法處理一篇文章的流程。其中頻道和主題的抽取方法屬于關鍵詞配置設定這一類算法,标簽詞抽取則屬于關鍵詞抽取這一類算法。除了上一節中所說的階層化關鍵詞的兩個優點之外,我們的算法有如下幾點好處:
關鍵詞配置設定算法有效緩解關鍵詞抽取算法召回不足的問題。
在關鍵詞配置設定算法中,使用頻道和主題代替傳統的關鍵詞,進而減少詞庫建構成本、增強算法的可移植性。
圖5階層化關鍵詞自動标注算法流程
2.1 文本分類器
文本分類器我們采用最大熵模型[2],使用業務最近一年帶頻道标簽的新聞作為訓練集。每個頻道選取頻道相關度最高的1W個詞語作為分類特征。
對于最大熵模型,網上可以找到很多相關資料,這裡就不作介紹了。
2.2 主題預測
使用LDA[3]作為主題聚類模型。LDA開源的大部分開源實作都是單程序的,在處理較大規模的語料時,其時間和記憶體開銷都非常大,無法滿足我們的要求。是以我們實作了一套分布式的LDA平台,使得能夠快速處理大規模的資料。
語料通過LDA平台處理後,會得到每個主題下機率較高的詞語。人工選取品質較高的主題,并使用一個詞語或者短語概括這個主題。對于一篇文章,LDA的inference結果是一個機率向量,我們選取機率值大于門檻值的主題作為文章所屬的主題。
圖6高品質的主題
圖7文章的主題關鍵詞
2.3 标簽詞抽取
标簽詞抽取包括:生成候選詞和相關性計算。下面分别介紹這兩部分。
1)生成候選詞
通過分詞得到的基本詞、短語等,過濾掉基本詞中的停用詞
命名實體(有效解決新詞、熱詞的自動發現)
2)相關性計算
使用線性權重對候選詞打分,其特征包括:
TF*IDF
候選詞和文章頻道的相關程度
候選詞和文章的相似度
候選詞的長度
候選詞出現的位置
候選詞的類型(基本詞、實體類型、短語等)
選取相關性得分大于門檻值的候選詞作為文章的标簽詞。
在騰訊網上随機抽取的351篇新聞上做測試,各項名額如表格1所示。由于主題集合的開放性,其召回率很難評價,故隻評價其準确率。
表格1 階層化關鍵詞自動标注算法準召率
對抽取錯誤的關鍵詞進行分析,算法還存在一些問題,後續會針對這些問題繼續改進。
泛義詞過濾不徹底,後續需要繼續優化候選詞過濾子產品。
抽取出來的兩個關鍵詞可能是表述同一個語義,後續引入同義詞等資源解決。
目前已經接入的公司業務有:騰訊新聞用戶端、手機Qzone個性化資訊。歡迎有需求的團隊聯系我們,使用騰訊文智自然語言處理。
[1] 劉知遠. 基于文檔主題結構的關鍵詞抽取方法研究[D]. 北京: 清華大學, 2011.
[2] Berger A L, Pietra VJ D, Pietra S A D. A maximum entropy approach to natural languageprocessing[J]. Computational linguistics, 1996, 22(1): 39-71.
[3] Blei D M, Ng A Y,Jordan M I. Latent dirichlet allocation[J]. the Journal of machine Learning research,2003, 3: 993-1022.