對于越來越多的分析型場景,例如資料倉庫,科學計算等, 經典的資料庫DBMS的檢索性能頗顯乏力。
相反的,最近出現了很多面向列存的資料庫DBMS,像ClickHouse,Vertica, MonetDB等,因其充分利用了現代計算機的一些硬體優勢,同時舍棄了一些DBMS特性,得到了非常好的檢索性能。本文就MonetDB, 整理一些資料和代碼,簡單介紹其核心設計。 通過簡單Benchmark, 驗證其檢索性能。
在過去的幾十年中,CPU的架構設計經曆了巨大的發展和變化,如今的CPU結構已經變動的非常複雜和精巧,其計算能力也得到了顯著提升。新硬體的發展驅使應用軟體不斷改進其架構設計,以至于更加貼合新硬體的優勢,使應用軟體表現出更好的性能。
下圖展示了基礎CPU模型和Pentium 4 CPU的結構(雖然Pentium也已經過時了),為了簡化對CPU計算過程的認識,從基礎CPU模型開始:
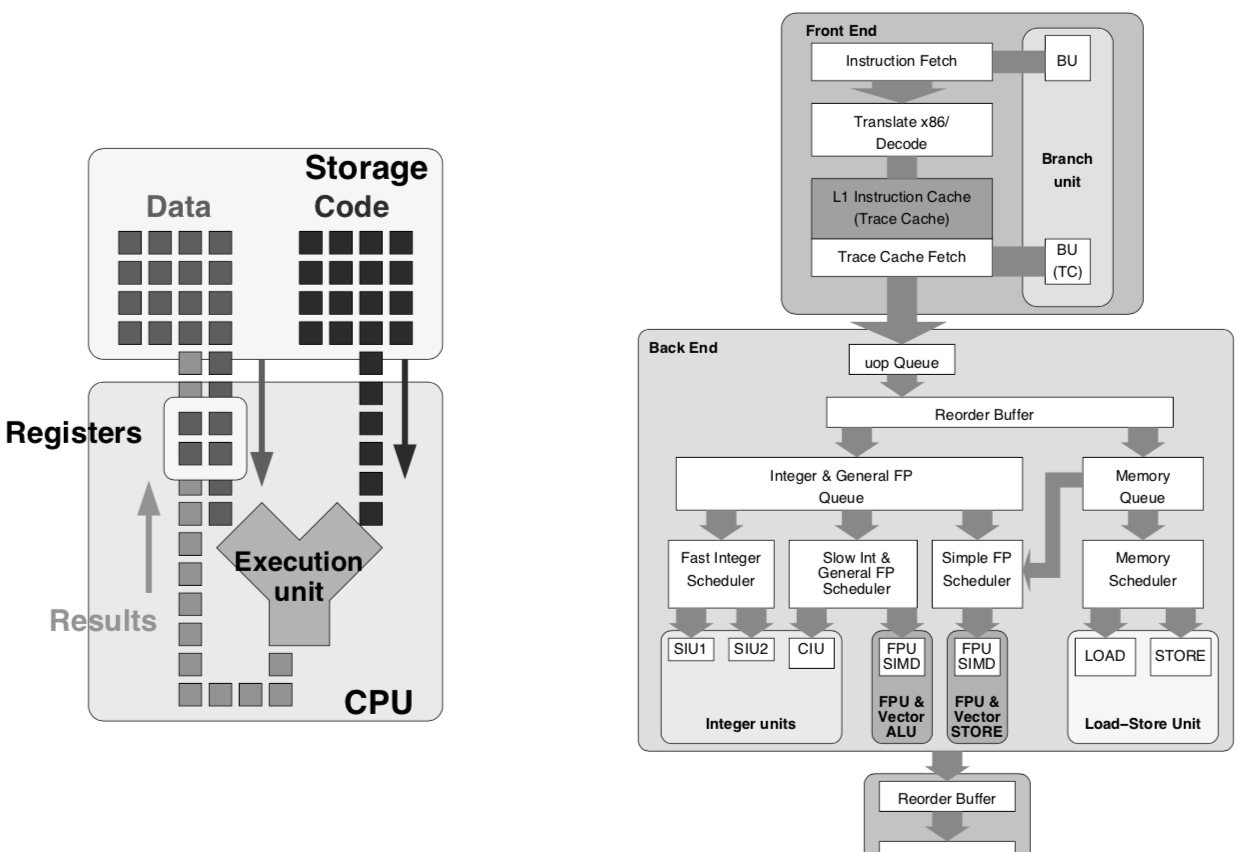
Data :
CPU 計算操作數,即每次計算的輸入資料,例如一個整型值;
Code :
CPU 計算指令,指令CPU做何種計算;
Storage :
存儲操作數和指令的容器,通常為主存RAM;
Registers:
寄存器,CPU内部存儲單元,存儲CPU目前執行的指令需要操作的資料。
Execution Unit :
計算執行單元,不斷讀取下一個待執行的指令,同時從寄存器讀取該指令要操作的資料,執行指令描述的計算,并将結果寫回寄存器。
以上這些抽象的邏輯單元都比較簡單易了解。 該模型下CPU的每一次Cycle隻執行一條指令。通常情況下,每條指令的執行又可以分解為以下4個嚴格串行的邏輯Stage :
Instruction Fetch(IF) : 指令擷取。擷取待執行的指令。
Instruction Decode(ID) : 指令解碼。根據系統指令集解碼指令為microcodes。
Execute(EX) : 執行指令。執行解碼後的microcodes, 不同類型的計算過程通常需要不同的實體計算單元來完成,例如代數計算單元,浮點數計算單元,操作數加載單元等。
Write-Back(WB) : 儲存計算結果到寄存器。
不同的Stage通常由不同的CPU實體單元來完成,由于這幾個Stage必須以嚴格串行的方式執行,是以最簡單的執行方式就是:每個CPU實體單元完成自己負責的Stage任務後将結果作為執行下一個Stage的CPU實體單元的輸入,弊端就是,例如執行'EX'的CPU 實體單元必須等待執行'ID'的CPU實體單元完成,在此之前,它都是空閑的, 如下圖"Sequential execution"所示。 為了提高效率,采用了pipeline 的模式,如下圖"Pipelined execution"所示:

盡管Pipelined的執行方式并沒有改變單條指令的執行時間,但整體指令流的執行吞吐明顯提升了。如上圖所示,吞吐提升了4倍。當然,這僅是理想情況。
為了進一步提高CPU指令計算的吞吐,現代CPU進一步發展了Superscalar的執行方式,通過内置多個同類型的實體執行單元,來擷取更"寬"的pipeline。 例如,在隻有一個代數運算單元的CPU中,代數運算的pipeline寬度為1,即每個CPU Cycle隻有一條代數運算指令被執行。如果把代數運算單元double一倍,那麼一個CPU Cycle内就可以有兩條代數運算指令在不同的代數運算單元上同時執行,IF Stage也可以一次性擷取兩條指令作為pipeline的輸入,此時Pipeline的寬度為2,CPU指令計算的吞吐又提升了一倍。
另外,除了通過擴充CPU單元的數量來提升CPU計算的吞吐,還可以通過提升單個CPU運算單元的能力來達到目的。 以前,一個代數運算單元一次(在一個CPU Cycle内)對一份操作數,執行一個代數運算指令,得到一份結果,這稱為單指令單資料流(SISD)。 如現在的大多數CPU的代數運算單元,可以一次對多份操作數,執行同一個運算指令,得到多份結果,這稱為單指令多資料流(SIMD)。假設在某些場景下,如果都是相同類型的計算,隻改變計算的參數(例如圖像領域,3D渲染等), 利用SIMD又可以成倍提升CPU計算吞吐。
Pipelined Execution, 其對CPU計算吞吐的提升都僅限于理想情況,其基本的假設是CPU正确的推測了馬上會執行的指令并将其加入Pipeline。但是很多情況下,下一個要執行的指令可能必須基于運作時的判斷。如果下一個指令恰好跳出了已經Pipelined的指令的範圍,那CPU不僅要等待加載該指令,而且目前整條Pipeline需要被清空并重新加載,這被稱之為Control Hazards, 另外,當跳轉發生時,不僅指令需要被加載,指令相關的操作數也需要被重新擷取,如果Cache-Miss導緻主存Lookup,則至少要浪費上百個CPU Cycle, 這稱之為Data Hazards。 這類因指令跳轉造成吞吐下降的現象稱為Pipeline-bubble。
現代CPU架構中,CPU-Cycle的Stage劃分更加精細,加深了Pipeline的深度。更深的Pipeline有利于提高CPU計算的吞吐,但Pipeline-bubble的問題也被進一步放大。是以,對CPU-Friendly的代碼,其性能更好,反之,性能反而有所下降。
抛開上面的邏輯模型,宏觀上,現代CPU大都采用同步多線程技術(SMT), 多處理器架構(CMP)等,整體提升CPU的并行計算能力。
相比于CPU計算能力的巨幅提升,Memory Access的時間并不顯著。是以,在現代主流計算機中,一個memory-access指令需要等很長的時間(幾百個CPU-Cycle)才能把資料加載到寄存器中。
為了緩解此類問題,記憶體系統被設計為多層次記憶體體系。一些更快,但容量較小的靜态存儲媒介被加到記憶體體系中,作為主存RAM的緩存Cache Memory。Cache Memory分為D-Cache 和I-Cache, 分别用于存儲資料和指令(代碼);
在該體系中,按data access的時間從小到大,依次有Register, L1 Cache, L2 Cache, L3 Cache, 主存RAM等(相應的data access時間可以參考Jeff Dean's Number)。
Cache Memory 通常被按固定大小分為很多個Cache lines, 每個Cache line緩存主存中的某一塊相應大小資料。Memory access 被設計為先通路Cache Memory,如果恰好通路位址在Cache lines中,稱為cache-hit, 反之cache-miss。 cache-miss 引發主存lookup,并換入lookup到的資料塊到cache line中。因為虛拟檔案系統的關系,cache-miss時,lookup主存有可能引發page-fault, 延長資料擷取時間。
經典關系資料庫在邏輯上把資料儲存成一系列行(row)的集合,每行對應關系資料的一個Tuple。在實體存儲上,也是如此。這種存儲方式稱之為NSM(N-ary storage model)。 與之相應的,是一種按列組織并存儲資料的方式,稱之為DSM(Decomposed storage model), 如下圖所示:
通常把這兩種不同存儲形式的資料庫稱為行存資料庫或列存資料庫。列存資料庫形式出現的也很早,隻是在當時硬體條件下,列存資料庫隻有在select很少列的情況下,性能才會稍好于各類行存資料庫。這也形成了現在很多人固有的觀念:"如果查詢很多列,行存資料庫完勝列存資料庫;"。加之以前資料庫覆寫的都是OLTP場景,使用者存取資料遵守三範式原則,隻要讀取一兩個列的情形也比較少。
但随着硬體技術發展,列存資料庫的能力又需要被重新審視。下圖列舉了到2010年為止,已知的一些列存資料庫讀取多列資料性能的增長, 橫軸為查詢列占該關系所有列的比例。
可以看到,近年來,即使是SELECT所有列資料,列存資料庫的性能也不輸行存資料庫。尤其在一些資料倉庫或OLAP的場合,資料組織不在遵守三範式,而是為了節省關聯時間存儲成大寬表。反而SELECT部分列更貼合需求。
除了資料存儲方式的異同,查詢執行層的設計也可能略有差異。經典關系資料庫基于一個稱之為Tuple-at-a-time的疊代模型,各種關系算子按照一定的拓撲結構串聯成查詢計劃。查詢執行時,資料按照算子之間拓撲關系構成pipeline。 如下圖右側所示,查詢語句為:
圖中,子算子(位于上層的算子)調用<code>next()</code>函數向父算子(位于下層的算子)請求資料,最底層父算子從存儲層擷取資料,處理後傳回給子算子,以此類推,每次next請求隻傳回一條資料(Tuple)。整個執行模型是基于子算子的Pull模型,也稱之為‘Pull based iterator model’。
Tuple-at-a-time疊代模型下,每個Tuple從存儲層讀取出來後,都要經曆很多個函數調用。例如,每個父子算子之間的<code>next()</code>函數,Select算子調用<code>filter</code>函數,Project算子要調用代數運算函數等等。整個執行過程中,很多函數,代碼,狀态被重複很多次的頻繁讀取,調用,更新。進而導緻了一些性能缺陷。有學者從理論上分析了一下一些性能問題:
CPU Instruction Cache : 由于查詢計劃可能包含很多不同類型的算子,其組合到一起的所有指令的大小可能超過了I-Cache的容量。 每處理一個Tuple,CPU都需要在不同的算子之間不斷的切換上下文(包括算子的計算指令,狀态資料等),如果I-Cache不足以容納所有指令,cache-miss會在整個執行過程頻繁發生。
Function call overhead : 函數調用本身需要額外的CPU-Cycle, 尤其是當參數很多的時候。另外,如果是dynamically-dispatched的函數,可能需要幾十個CPU-Cycle(因為跳轉導緻了Pipeline bubble)。
Tuple manipulation: 每個Tuple都包含多個屬性, 對幾個屬性的操作(例如Select Age > 30)需要先定位并讀取出Age屬性,這種對Tuple的解釋在每個Tuple處理時都要被重複很多次,花費很多額外的指令。
Superscalar CPUs utilization: 由于在Tuple-at-a-time模型中,每個算子一次隻處理一個Tuple, 是以無法有效利用現代CPU Superscalar的特性。進而對現代CPU而言,每個CPU-Cycle, 隻能執行很少的指令(low instructions-per-cycle)。
data volume : 由于按行存儲的原因,計算中每個Tuple所有屬性都被完整的讀取出來,從磁盤到主存,到Cache。如果計算隻需要部分屬性,即浪費了RAM和Cache的空間,也浪費了Disk->RAM->Cache的帶寬。
也有學者Trace TCP-H Query 1的執行,從實驗角度證明經典關系資料庫在CPU使用率的低效。
上圖Benchmark, 查詢執行過程中所有的函數調用按照其被調用的先後順序排序,第一列為表示查詢總時間,第二清單示目前Function執行耗時。第三清單示Function被調用執行的總次數,第四第五清單示每次Function執行所需的平均指令數以及平均IPC(Instruction-per-cycle)。
Benchmark至少說明了,在Tuple-at-a-time的經典行存資料庫查詢中,使用者定義的資料計算的函數(+,-,*,sum,avg),其執行時間占查詢總時間比例約10%。28%的時間耗費在聚合操作時,對Hash-Table的查找,寫入。而62%的時間耗費在像rec_get_nth_field這樣函數執行上,他們的主要功能,就是解釋Tuple, 例如定位,讀取或寫入Tuple中的某些屬性。如此來看,對于每一個Tuple, 需要被執行的指令(instructions-per-tuple)非常多。 另一方面,所有函數執行的平均IPC約為0.7, 極大的低于現代Superscalar 處理器的計算水準。
總結起來,在經典關系資料庫中,一個很高的instructions-per-tuple, 和一個很低的instructions-per-cycle, 導緻了查詢時很高的cycles-per-tuple。也就是說,即使是很簡單的計算操作,每個Tuple的處理也很可能需要幾百個CPU Cycle。 CPU的計算能力沒有被充分利用,資料庫查詢的性能還有很大的提升空間。 正是為了解決這些問題,才有了MonetDB這些高性能列存資料庫DBMS。
也許正是因為現有的資料庫系統都沒有充分利用現代電腦巨大潛力,才有了一些列像MonetDB這些高性能資料庫的出現。MonetDB被設計為面向資料密集型應用,使用新的查詢模型,更高效的處理資料。MonetDB裡提出的所有資料處理技術都圍繞兩個點:一是面向CPU-Efficient計算, 二是存儲帶寬優化。
差別于經典關系資料庫,MonetDB采用DSM模型作為資料存儲格式。Tuple的各個屬性被分開存儲,相同屬性的值被存儲在一起,即典型的按列存儲方式。邏輯上,MonetDB中每一列被存儲為一個Binary Association Table(BAT), 簡單來說,就是一個隻有兩列的表,第一列存儲虛拟ID,第而列存儲屬性值。同一個Tuple的不同屬性具有相同的虛拟ID, 即可以通過相同虛拟ID來關聯同一Tuple的不同屬性,進而建構Tuple的完整資料。 實體上,虛拟ID并不一定被真的被存儲,例如,對于定長屬性, 其所有值按緊湊資料格式存儲,相應的虛拟ID就是數組的下标。對于不定長屬性, 其不定長的資料内容存儲在連續存儲空間,用一個定長的指針來關聯真實值,而虛拟ID就是指針數組的下标。
如下圖,左邊資料按BAT的格式組織,右邊描繪了該格式下執行<code>SELECT Id,Name,Age,(Age-30) * 50 as Bonus FROM People WHERE Age > 30;</code> 查詢的方式:
這樣存儲的好處有,第一,相同屬性的值存儲在一起,可以比較高效的應用一些壓縮算法,減少其占用存儲空間大小。 第二, 針對特定列的計算隻需要讀取該特定列的值, 既可以較大提升存儲的I/O性能,也可以減少記憶體使用。第三, 每列資料按緊湊數組的方式存儲,大部分針對屬性的計算簡化為對數組值的周遊計算,可以比較高效的利用CPU的計算能力(如SIMD等)。
在以上列存格式的資料存儲的基礎上,MonetDB為應對資料密集型應用,專門研發了一套高效的查詢執行引擎,該引擎創造性的提出了一種新的執行模型,稱之為“Vectorized in-cache execution model”。
首先,和傳統的Pipelined模型一樣, MonetDB的查詢計劃是由各種算子(operator)構成了一個樹(或DAG)。 但不同的是,傳統Pipelined模型中的算子每次計算的對象是一個Tuple, 而MonetDB中,算子每次計算的,是一組由相同屬性的不同屬性值構成的向量(數組)。 在每個算子内部,針對其計算屬性的類型,使用高度優化的代碼(primitive)來處理向量資料。
向量是MonetDB執行模型中最基本的資料處理單元和傳輸單元(作為計算中間結果在算子之間傳遞), 向量其實是一個由同一屬性的多個不同屬性值構成的一維數組,根據屬性類型的異同,向量的大小也有差異。采用這種針對向量的計算模式的優勢是,每個算子在計算過程中不在需要像傳統Pipelined模型裡那般,要從Tuple裡定位,讀取某些屬性,計算完成後再定位寫入到輸出Tuple中, 而是完全順序的記憶體讀寫,省去了這些Tuple解釋操作,即高效的利用了記憶體帶寬,也節省了data-access的時間。同時,為CPU自動優化SIMD指令提供了機會。
以下通過TPC-H Query 1 舉例說明MonetDB查詢執行過程:
左圖為查詢執行時資料在不同存儲單元的傳輸過程。MonetDB提出了一種名為ColumnBM的列式資料組織方式,可以在有限帶寬條件下,盡可能提升scan的性能。 磁盤和記憶體的資料都是壓縮資料,當他們被以向量的形式加載的CPU Cache時才被解壓,有助于提升記憶體使用率。不同列上的計算是分開的,直到最後才被物化為使用者需要的行式結果。
右圖是查詢執行計劃和向量資料流,整個查詢計劃從下到上有四類算子: Scan, Select, Project, Aggregate。 但計算不同類型列的同種算子,其内部代碼也不同。 例如,負責處理'shipdate'列的Scan算子,内部代碼(primitive)是對Date資料類型的緊湊周遊, 同時按條件篩選值。而負責處理'extprice'的Scan算子,其内部代碼(primitive)隻是對Double的順序讀。所有算子的輸入和輸出都是向量,整個查詢計劃是由向量構成的pipeline (詳細的向量計算算法這裡不展開)。
由于主存帶寬無法滿足CPU-Efficient的代碼(primitive)對資料的饑渴需求, MonetDB打算充分利用cache-memory帶寬來緩解問題。由此提出了in-cache計算: 所有的向量都被用特殊的方式組織,已使他們的大小可以完全放入CPU Cache。 是以,一些計算的結果可以被儲存在CPU Cache,而不需要寫回到記憶體。後續的計算可以直接讀取這些Cache中的結果,節省了主存讀的時間。
仍然以一個SQL查詢的例子說明計算過程:
如圖, ‘l_quantity * l_extendedprice’ 的結果‘netto_value’被儲存在CPU-Cache中,當計算‘tax_value’時,隻需要從主存讀取‘l_tax’的向量值就可以了,同時,計算結果也被儲存在CPU-Cache中,當計算‘total_value’時不再需要從主存讀資料。由此,減輕了主存讀寫帶寬瓶頸對計算的限制。
右圖表明, "add"操作的性能要好于"mu1"和"mu2", 因為它的輸入資料都在CPU Cache中。 同時,也證明了不同向量大小對計算性能的影響,當向量較小時(向量總數較多),沒有充分利用CPU-Cache的空間。向量較大時,因為無法全部放入CPU-Cache,導緻部分資料必須從主存擷取。當向量大小接近CPU-Cache時,達到了平衡,此時的計算性能是最優。
對于現代計算機的主要硬體, MonetDB有以下優化:
CPU : MonetDB查詢執行過程中,負責處理資料的代碼(primitive)通常都是非常簡單的邏輯,即使有函數調用,也大都被設計為在一個函數調用中處理多組資料。大大減少了函數調用次數。對于單個資料來說,發生函數調用的overhead被多組資料所分攤。 加上SIMD等優化,每條資料計算所需的指令數被減少,也就得到了一個很低的instructions-per-tuple值。
Cache : 查詢過程中,各算子之間以向量(vector)的形式交換資料,向量被設計為一個比較優化的大小,可以完全放入記憶體(fully cache-resident), 節省了主存資料讀寫的大延時。處理資料的代碼(primitive)也被優化為采用cache-efficient的算法來實作。
RAM : 資料按列存儲,并高效壓縮。相同容量的RAM可以放入更多的資料。
Disk : MonetDB中幾乎沒有随機讀,所有的查詢計算都是基于Scan。 當資料需要存儲在磁盤上時,MonetDB優化了資料結構,形成了一套名為ColumnBM I/O Subsystem的機制來提升磁盤Scan的性能。
對照上文經典關系行存資料庫的理論分析的次元,分析MonetDB:
instruction-cache : 雖然MonetDB也采用pipelined的方式執行查詢,其各算子的所需的指令總和也可能超過I-Cache的容量大小。但不同于Tuple-at-a-time模型,MonetDB中各算子計算的是向量,CPU也需在不同算子之間切換,但即使發生指令的cache-miss, 其重新load的時間可以被向量中所有資料所分攤。
Function call overhead : 絕大多數算子實作都是對向量調用函數,而不是對單條資料的頻繁調用。大大減少了函數調用的次數。
Tuple manipulation : 所有算子的輸入輸出都是向量的形式,即一個連續的緊湊數組。 計算過程直接讀寫資料,不需要任何對資料做任何解釋。
Superscalar CPUs utilization : 因為計算都是針對向量的,即相同的指令處理一系列資料。MonetDB還特别針對資料處理代碼(primitive)做了優化,使其盡可能不包含跳轉指令,充分發揮SuperScalar CPU向量計算的能力。
Data volume : 由于采用了按列存儲的方式,隻有計算所需要的列才會被讀取,并且,列式資料被高效的壓縮,即節省了RAM空間,使其可以Keep更多的資料,也提高了Disk->RAM->Cache的帶寬使用率。
MonetDB中的資料讀是基于Scan的,是以資料存儲媒體的不同,性能差異也會比較大。在實作中, MonetDB采用Memory mapped file的方式,将所有資料存儲映射為虛拟記憶體位址,從代碼層面忽略了存儲媒體的類型, 依賴系統的MMU換入實體記憶體位址以外的資料頁。在實際查詢計算過程中, MonetDB為了保證向量計算的性能,通常盡可能一次換入目前計算所需列的所有資料,如果真實資料的某一列的大小超過MonetDB可支配實體記憶體的總大小,針對該列的查詢性能損耗會比較嚴重,但相對來說,還是優于使用相同硬體存儲資料,并且未建索引的行存DBMS。
說到索引,MonetDB目前支援兩類索引 IMPRINTS和ORDERED 。但這兩類索引隻支援定長數值類型,并且不支援複合索引。如果出現上面提到的情形,某列大小超過可支配實體記憶體,并且該列支援建索引,那麼建索引後可以極大提升查詢性能。
MonetDB paper中給出了TPC-H Query 1的查詢性能(如下), 證明其基于向量計算的性能已經接近hand-code C代碼的性能:
為了體驗MonetDB, 以下是SQLite-In-Memory和MonetDB 的對比測試。
其中,souceid,和 destid分别是對sourceip和desturl做Murmur哈希得到的long值。
批量資料導入: SQLite-In-Memory導入到記憶體, MonetDB導入到磁盤 ,原始CSV檔案大小6.3G :
DBMS
DDL
Cost /s
Total Size/G
SQLite-In-Memory
.mode csv;
.import raw.csv user_visit
347
6.37
MonetDB
COPY INTO user_visit FROM raw.csv
88
2.2
MonetDB批量資料導入速度是SQLite-In-Memory的4倍, 導入後資料大小隻有原始檔案的1/3 。
查詢語句:
批量導入後的第一次查詢, SQLite-In-Memory資料常駐記憶體,對其而言每次查詢性能穩定的, MonetDB資料持久化在磁盤,第一次查詢需要依賴mmu換入磁盤資料:
由于都沒有建索引,查詢都是基于Scan, 但SQLite-In-Memory Scan記憶體的性能要遠落後于MonetDB Scan磁盤。
第二次查詢,更改了查詢參數:
由于系統記憶體充足, 此時MonetDB的查詢幾乎是In-memory Scan, 查詢性能也提高了不少。
下面對sourceid和destid建索引:
CREATE INDEX sourceIdIndex on user_visit (sourceId);
CREATE INDEX destIdIndex on user_visit(destId);
127
7.52
CREATE ORDERED INDEX sourceIdIndex ON user_visit (sourceId);
CREATE ORDERED INDEX destIdIndex ON user_visit (destId);
12
2.7
可以利用索引的查詢有1,2,3,4,5。 SQLite-In-Memory在有索引的時查詢小于1ms, MonetDB的第一和第二次查詢延時如下圖:
在有索引的前提下,即使資料在磁盤,MonetDB的第一次查詢也可以在幾個毫秒内完成。
從以上Benchmark得到的結論:
對于MonetDB而言, 記憶體很重要。查詢的性能完全取決于資料是否In-Memory。 在實驗中,我們嘗試更換不同性能的磁盤,有SATA盤,SSD, 和記憶體挂載盤,其随機讀性能有千百倍的差異,但對MonetDB的查詢影響不大(因為MonetDB依賴順序讀)。MonetDB Paper中宣稱在In-Memory模式下,單核可以每秒處理多達GB資料。
對定長列的查詢要比對不定長列查詢要快很多。
對有很多重複值的列的查詢要比對值是Unique的列的查詢快很多。
查詢列的個數對查詢性能影響不大。
Zukowski M. Balancing vectorized query execution with bandwidth-optimized storage[J]. University of Amsterdam, PhD Thesis, 2009.
Abadi, Daniel, et al. "The design and implementation of modern column-oriented database systems." Foundations and Trends® in Databases 5.3 (2013): 197-280.
Zukowski, Marcin, et al. "MonetDB/X100-A DBMS In The CPU Cache." IEEE Data Eng. Bull. 28.2 (2005): 17-22.
Boncz, Peter A., Marcin Zukowski, and Niels Nes. "MonetDB/X100: Hyper-Pipelining Query Execution." Cidr. Vol. 5. 2005.
<a href="https://www.monetdb.org">https://www.monetdb.org</a>