目錄
前言
微服務概述
微服務與微服務架構
微服務優缺點
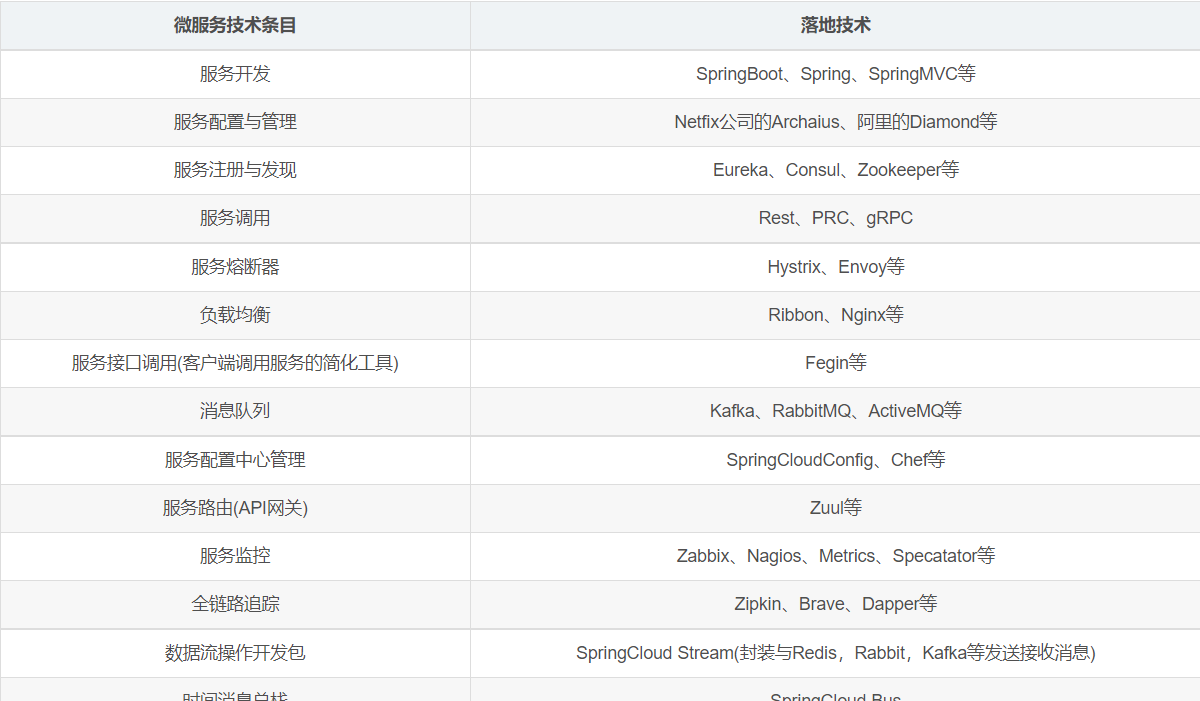
微服務技術棧
為什麼選擇SpringCloud作為微服務架構
SpringCloud入門
SpringCloud和SpringBoot的關系
Dubbo 和 SpringCloud技術選型
SpringCloud能幹嘛?
SpringCloud下載下傳
Rest學習環境搭建
API子產品
Provider-8001子產品
consumer-80子產品
Eureka
什麼是Eureka?
原理了解
建構步驟(重點)-所有的服務收都是這個步驟
Eureka服務注冊
Eureka自我保護機制
Eureka叢集配置
EurekaCAP原則和對比Zookeeper
Ribbon
是什麼?
Ribbon能幹嘛?
使用Ribbon實作負載均衡
自定義負載均衡算法
Feign
Hystrix
服務雪崩
服務熔斷
服務降級
服務熔斷和降級的差別
入門案例
服務雪崩&服務熔斷
Dashboard 流監控
Zuul入門案例
Config
總結
項目位址:https://gitee.com/zwtgit/spring-cloud-study
微服務架構4個核心問題?
服務很多,用戶端該怎麼通路?
這麼多服務? 服務之間如何通信?
這麼多服務? 如何治理?
服務挂了怎麼辦?
解決方案:
Spring Cloud NetFlix 一站式解決方案!
api網關,zuu1元件
Feign ---HttpClinet ---- Http通信方式,同步,阻塞
服務注冊發現: Eureka
熔斷機制: Hystrix …………
Apache Dubbo ZooKeeper 半自動,需要整合别人的東西
Spring Cloud Alibaba 一站式解決方案!更簡單
新概念:服務網格,Server Mesh
但是他們的共同點是解決這幾個問題:
API網關,服務路由
HTTP,RPC架構,異步調用
服務注冊與發現,高可用
熔斷機制,服務降級
為什麼有這幾個問題,還是因為網絡的不可靠,是以我們要研究解決他們的方案。
什麼是微服務?
微服務(Microservice Architecture) 是近幾年流行的一種架構思想,關于它的概念很難一言以蔽之。
究竟什麼是微服務呢?我們在此引用ThoughtWorks 公司的首席科學家 Martin Fowler 于2014年提出的一段話:
原文:https://martinfowler.com/articles/microservices.html
漢化:https://www.cnblogs.com/liuning8023/p/4493156.html
就目前而言,對于微服務,業界并沒有一個統一的,标準的定義。
但通常而言,微服務架構是一種架構模式,或者說是一種架構風格,它提倡将單一的應用程式劃分成一組小的服務,每個服務運作在其獨立的自己的程序内,服務之間互相協調,互相配置,為使用者提供最終價值,服務之間采用輕量級的通信機制(HTTP)互相溝通,每個服務都圍繞着具體的業務進行建構,并且能夠被獨立的部署到生産環境中,另外,應盡量避免統一的,集中式的服務管理機制,對具體的一個服務而言,應該根據業務上下文,選擇合适的語言,工具(Maven)對其進行建構,可以有一個非常輕量級的集中式管理來協調這些服務,可以使用不同的語言來編寫服務,也可以使用不同的資料存儲。
再來從技術次元角度了解下:
微服務化的核心就是将傳統的一站式應用,根據業務拆分成一個一個的服務,徹底地去耦合,每一個微服務提供單個業務功能的服務,一個服務做一件事情,從技術角度看就是一種小而獨立的處理過程,類似程序的概念,能夠自行單獨啟動或銷毀,擁有自己獨立的資料庫。
微服務
強調的是服務的大小,它關注的是某一個點,是具體解決某一個問題/提供落地對應服務的一個服務應用,狹義的看,可以看作是IDEA中的一個個微服務工程,或者Moudel。 IDEA 工具裡面使用Maven開發的一個個獨立的小Moudel,它具體是使用SpringBoot開發的一個小子產品,專業的事情交給專業的子產品來做,一個子產品就做着一件事情。 強調的是一個個的個體,每個個體完成一個具體的任務或者功能。
微服務架構
一種新的架構形式,Martin Fowler 于2014年提出。
微服務架構是一種架構模式,它體長将單一應用程式劃分成一組小的服務,服務之間互相協調,互相配合,為使用者提供最終價值。每個服務運作在其獨立的程序中,服務與服務之間采用輕量級的通信機制(如HTTP)互相協作,每個服務都圍繞着具體的業務進行建構,并且能夠被獨立的部署到生産環境中,另外,應盡量避免統一的,集中式的服務管理機制,對具體的一個服務而言,應根據業務上下文,選擇合适的語言、工具(如Maven)對其進行建構。
優點
單一職責原則;
每個服務足夠内聚,足夠小,代碼容易了解,這樣能聚焦一個指定的業務功能或業務需求;
開發簡單,開發效率高,一個服務可能就是專一的隻幹一件事;
微服務能夠被小團隊單獨開發,這個團隊隻需2-5個開發人員組成;
微服務是松耦合的,是有功能意義的服務,無論是在開發階段或部署階段都是獨立的;
微服務能使用不同的語言開發;
易于和第三方內建,微服務允許容易且靈活的方式內建自動部署,通過持續內建工具,如jenkins,Hudson,bamboo;
微服務易于被一個開發人員了解,修改和維護,這樣小團隊能夠更關注自己的工作成果,無需通過合作才能展現價值;
微服務允許利用和融合最新技術;
微服務隻是業務邏輯的代碼,不會和HTML,CSS,或其他的界面混合;
每個微服務都有自己的存儲能力,可以有自己的資料庫,也可以有統一的資料庫;
缺點
開發人員要處理分布式系統的複雜性;
多服務運維難度,随着服務的增加,運維的壓力也在增大;
系統部署依賴問題;
服務間通信成本問題;
資料一緻性問題;
系統內建測試問題;
性能和監控問題;
選型依據
整體解決方案和架構成熟度
社群熱度
可維護性
學習曲線
目前各大IT公司用的微服務架構有那些?
阿裡:Dubbo+HFS
京東:JFS
新浪:Motan
當當網:DubboX
…
各微服務架構對比

Spring官網:https://spring.io/
SpringCloud,基于SpringBoot提供了一套微服務解決方案, 包括服務注冊與發現,配置中心,全鍊路監控,服務網關,負載均衡,熔斷器等元件,除了基于NetFlix的開源元件做高度抽象封裝之外,還有一些選型中立的開源元件。
SpringCloud利用SpringBoot的開發便利性,巧妙地簡化了分布式系統基礎設施的開發, SpringCloud為開發人員提供了快速建構分布式系統的一些工具,包括配置管理,服務發現,斷路器,路由,微代理,事件總線,全局鎖,決策競選,分布式會話等等,他們都可以用SpringBoot的開發風格做到一鍵啟動和部署。
SpringBoot并沒有重複造輪子,它隻是将目前各家公司開發的比較成熟,經得起實際考驗的服務架構組合起來,通過SpringBoot風格進行再封裝,屏蔽掉了複雜的配置和實作原理,最終給開發者留出了一套簡單易懂,易部署和易維護的分布式系統開發工具包。
SpringCloud是分布式微服務架構下的一站式解決方案,是各個微服務架構落地技術的集合體,俗稱微服務全家桶。
SpringBoot專注于開發友善的開發單個個體微服務;
SpringCloud是關注全局的微服務協調整理治理架構,它将SpringBoot開發的一個個單體微服務,整合并管理起來,為各個微服務之間提供:配置管理、服務發現、斷路器、路由、為代理、事件總棧、全局鎖、決策競選、分布式會話等等內建服務;
SpringBoot可以離開SpringCloud獨立使用,開發項目,但SpringCloud離不開SpringBoot,屬于依賴關系;
SpringBoot專注于快速、友善的開發單個個體微服務,SpringCloud關注全局的服務治理架構;
分布式+服務治理Dubbo
目前成熟的網際網路架構,應用服務化拆分+消息中間件
Dubbo 和 SpringCloud對比
可以看一下社群活躍度:
https://github.com/dubbo
https://github.com/spring-cloud
設計模式+微服務拆分
最大差別:Spring Cloud 抛棄了Dubbo的RPC通信,采用的是基于HTTP的REST方式
嚴格來說,這兩種方式各有優劣。雖然從一定程度上來說,後者犧牲了服務調用的性能,但也避免了上面提到的原生RPC帶來的問題。而且REST相比RPC更為靈活,服務提供方和調用方的依賴隻依靠一紙契約,不存在代碼級别的強依賴,這個優點在當下強調快速演化的微服務環境下,顯得更加合适。
總結:
二者解決的問題域不一樣:Dubbo的定位是一款RPC架構,而SpringCloud的目标是微服務架構下的一站式解決方案。
Distributed/versioned configuration 分布式/版本控制配置
Service registration and discovery 服務注冊與發現
Routing 路由
Service-to-service calls 服務到服務的調用
Load balancing 負載均衡配置
Circuit Breakers 斷路器
Distributed messaging 分布式消息管理
官網:http://projects.spring.io/spring-cloud/
SpringCloud沒有采用數字編号的方式命名版本号,而是采用了倫敦地鐵站的名稱,同時根據字母表的順序來對應版本時間順序,比如最早的Realse版本:Angel,第二個Realse版本:Brixton,然後是Camden、Dalston、Edgware,目前最新的是Hoxton SR4 CURRENT GA通用穩定版。
學習資料:
SpringCloud Netflix 中文文檔:https://springcloud.cc/spring-cloud-netflix.html
SpringCloud 中文API文檔(官方文檔翻譯版):https://springcloud.cc/spring-cloud-dalston.html
SpringCloud中國社群:http://springcloud.cn/
SpringCloud中文網:https://springcloud.cc
首先導入我們需要的依賴
建立資料庫,Navicat中的springcloudstudy01,後面有多個資料庫,因為是一個分布式的項目。
然後編寫實體類,注意要序列化,ORM類表關系映射。
這時候一個微服務就已經寫好了。
mybatis-config.xml裡面編寫配置
dao層(或者叫mapper層)寫接口,再在mapper檔案夾中編寫sql
mapper層
service層
controller層
啟動類
啟動後發現上面代碼中的 devtools版本不相容,注釋即可。
啟動項目後報錯,Invalid bound statement (not found),後發現是DeptMapper.xml中
導緻沒有對應到相應的檔案,是以編寫代碼的時候要細心,bug也不可避免,檢查要有條理,不着急。
添加依賴
application.yml
controller
然後編寫啟動類,先啟動provider載啟動consumer。
Netflix在涉及Eureka時,遵循的就是API原則。
Eureka是Netflix的有個子子產品,也是核心子產品之一。Eureka是基于REST的服務,用于定位服務,以實作雲端中間件層服務發現和故障轉移,服務注冊與發現對于微服務來說是非常重要的,有了服務注冊與發現,隻需要使用服務的辨別符,就可以通路到服務,而不需要修改服務調用的配置檔案了,功能類似于Dubbo的注冊中心,比如Zookeeper。
Eureka基本的架構
SpringCloud 封裝了Netflix公司開發的Eureka子產品來實作服務注冊與發現 (對比Zookeeper)。
Eureka采用了C-S的架構設計,EurekaServer作為服務注冊功能的伺服器,他是服務注冊中心。
而系統中的其他微服務,使用Eureka的用戶端連接配接到EurekaServer并維持心跳連接配接。這樣系統的維護人員就可以通過EurekaServer來監控系統中各個微服務是否正常運作,SpringCloud 的一些其他子產品 (比如Zuul) 就可以通過EurekaServer來發現系統中的其他微服務,并執行相關的邏輯。
Eureka 包含兩個元件:Eureka Server 和 Eureka Client。
Eureka Server 提供服務注冊,各個節點啟動後,回在EurekaServer中進行注冊,這樣Eureka Server中的服務系統資料庫中将會儲存所有課用服務節點的資訊,服務節點的資訊可以在界面中直覺的看到。
Eureka Client 是一個Java用戶端,用于簡化EurekaServer的互動,用戶端同時也具備一個内置的,使用輪詢負載算法的負載均衡器。在應用啟動後,将會向EurekaServer發送心跳 (預設周期為30秒) 。如果Eureka Server在多個心跳周期内沒有接收到某個節點的心跳,EurekaServer将會從服務系統資料庫中把這個服務節點移除掉 (預設周期為90s)。
三大角色
Eureka Server:提供服務的注冊與發現
Service Provider:服務生産方,将自身服務注冊到Eureka中,進而使服務消費方能狗找到
Service Consumer:服務消費方,從Eureka中擷取注冊服務清單,進而找到消費服務
導入依賴
編寫配置檔案
開啟這個功能 @EnableXXX
要注冊服務,是以在Provider-8001中添加Eureka的依賴并且編寫相應的配置。
@EnableEurekaServer一下
一句話總結就是:某時刻某一個微服務不可用,Eureka不會立即清理,依舊會對該微服務的資訊進行儲存!
預設情況下,當eureka server在一定時間内沒有收到執行個體的心跳,便會把該執行個體從系統資料庫中删除(預設是90秒),但是,如果短時間内丢失大量的執行個體心跳,便會觸發eureka server的自我保護機制,比如在開發測試時,需要頻繁地重新開機微服務執行個體,但是我們很少會把eureka server一起重新開機(因為在開發過程中不會修改eureka注冊中心),當一分鐘内收到的心跳數大量減少時,會觸發該保護機制。可以在eureka管理界面看到Renews threshold和Renews(last min),當後者(最後一分鐘收到的心跳數)小于前者(心跳門檻值)的時候,觸發保護機制,會出現紅色的警告:EMERGENCY!EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY’RE NOT.RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEGING EXPIRED JUST TO BE SAFE. 從警告中可以看到,eureka認為雖然收不到執行個體的心跳,但它認為執行個體還是健康的,eureka會保護這些執行個體,不會把它們從系統資料庫中删掉。
該保護機制的目的是避免網絡連接配接故障,在發生網絡故障時,微服務和注冊中心之間無法正常通信,但服務本身是健康的,不應該登出該服務,如果eureka因網絡故障而把微服務誤删了,那即使網絡恢複了,該微服務也不會重新注冊到eureka server了,因為隻有在微服務啟動的時候才會發起注冊請求,後面隻會發送心跳和服務清單請求,這樣的話,該執行個體雖然是運作着,但永遠不會被其它服務所感覺。是以,eureka server在短時間内丢失過多的用戶端心跳時,會進入自我保護模式,該模式下,eureka會保護系統資料庫中的資訊,不在登出任何微服務,當網絡故障恢複後,eureka會自動退出保護模式。自我保護模式可以讓叢集更加健壯。
但是我們在開發測試階段,需要頻繁地重新開機釋出,如果觸發了保護機制,則舊的服務執行個體沒有被删除,這時請求有可能跑到舊的執行個體中,而該執行個體已經關閉了,這就導緻請求錯誤,影響開發測試。是以,在開發測試階段,我們可以把自我保護模式關閉,隻需在eureka server配置檔案中加上如下配置即可:eureka.server.enable-self-preservation=false
DeptController.java新增方法, //擷取一些配置的資訊,得到具體的微服務!
簡單複制一下
但是這三個現在還沒有關系,是以我們配置他們之間的關系。
改一下host之後這三個的配置檔案是:
然後把釋出服務中的配置也修改一下,啟動三個注冊中心,再啟動服務。
CAP原則又稱CAP定理,指的是在一個分布式系統中,一緻性(Consistency)、可用性(Availability)、分區容錯性(Partition tolerance)。CAP 原則指的是,這三個要素最多隻能同時實作兩點,不可能三者兼顧。
一個分布式系統不可能同時很好的滿足一緻性,可用性和分區容錯性這三個需求,根據CAP原理,将NoSQL資料庫分成了滿足CA原則,滿足CP原則和滿足AP原則三大類:
CA:單點叢集,滿足一緻性,可用性的系統,通常可擴充性較差
CP:滿足一緻性,分區容錯的系統,通常性能不是特别高
AP:滿足可用性,分區容錯的系統,通常可能對一緻性要求低一些
Zookeeper保證的是CP
當向注冊中心查詢服務清單時,我們可以容忍注冊中心傳回的是幾分鐘以前的注冊資訊,但不能接收服務直接down掉不可用。也就是說,服務注冊功能對可用性的要求要高于一緻性。但zookeeper會出現這樣一種情況,當master節點因為網絡故障與其他節點失去聯系時,剩餘節點會重新進行leader選舉。問題在于,選舉leader的時間太長,30-120s,且選舉期間整個zookeeper叢集是不可用的,這就導緻在選舉期間注冊服務癱瘓。在雲部署的環境下,因為網絡問題使得zookeeper叢集失去master節點是較大機率發生的事件,雖然服務最終能夠恢複,但是,漫長的選舉時間導緻注冊長期不可用,是不可容忍的。
Eureka保證的是AP
Eureka看明白了這一點,是以在設計時就優先保證可用性。Eureka各個節點都是平等的,幾個節點挂掉不會影響正常節點的工作,剩餘的節點依然可以提供注冊和查詢服務。而Eureka的用戶端在向某個Eureka注冊時,如果發現連接配接失敗,則會自動切換至其他節點,隻要有一台Eureka還在,就能保住注冊服務的可用性,隻不過查到的資訊可能不是最新的,除此之外,Eureka還有之中自我保護機制,如果在15分鐘内超過85%的節點都沒有正常的心跳,那麼Eureka就認為用戶端與注冊中心出現了網絡故障,此時會出現以下幾種情況:
Eureka不在從注冊清單中移除因為長時間沒收到心跳而應該過期的服務
Eureka仍然能夠接受新服務的注冊和查詢請求,但是不會被同步到其他節點上 (即保證目前節點依然可用)
當網絡穩定時,目前執行個體新的注冊資訊會被同步到其他節點中
是以,Eureka可以很好的應對因網絡故障導緻部分節點失去聯系的情況,而不會像zookeeper那樣使整個注冊服務癱瘓。
Spring Cloud Ribbon 是基于Netflix Ribbon 實作的一套用戶端負載均衡的工具。
簡單的說,Ribbon 是 Netflix 釋出的開源項目,主要功能是提供用戶端的軟體負載均衡算法,将 Netflix 的中間層服務連接配接在一起。Ribbon 的用戶端元件提供一系列完整的配置項,如:連接配接逾時、重試等。簡單的說,就是在配置檔案中列出 LoadBalancer (簡稱LB:負載均衡) 後面所有的及其,Ribbon 會自動的幫助你基于某種規則 (如簡單輪詢,随機連接配接等等) 去連接配接這些機器。我們也容易使用 Ribbon 實作自定義的負載均衡算法。
LB,即負載均衡 (LoadBalancer) ,在微服務或分布式叢集中經常用的一種應用。
負載均衡簡單的說就是将使用者的請求平攤的配置設定到多個服務上,進而達到系統的HA (高用)。
常見的負載均衡軟體有 Nginx、Lvs 等等。
Dubbo、SpringCloud 中均給我們提供了負載均衡,SpringCloud 的負載均衡算法可以自定義。
負載均衡簡單分類:
集中式LB
即在服務的提供方和消費方之間使用獨立的LB設施,如Nginx,由該設施負責把通路請求通過某種政策轉發至服務的提供方。
程序式LB
将LB邏輯內建到消費方,消費方從服務注冊中心獲知有哪些位址可用,然後自己再從這些位址中選出一個合适的伺服器。
Ribbon 就屬于程序内LB,它隻是一個類庫,內建于消費方程序,消費方通過它來擷取到服務提供方的位址。
導入依賴-80
配置
再使用@EnableEurekaClient開啟Eureka服務以及@LoadBalanced使用負載均衡。
更改controller的位址
為了觀察負載均衡的效果,我們設計多個資料庫來看
sql語句:
然後Provider-8001也要同步變為Provider-8002和Provider-8003。
效果圖:
Feign簡介
Feign是聲明式Web Service用戶端,它讓微服務之間的調用變得更簡單,類似controller調用service。SpringCloud內建了Ribbon和Eureka,可以使用Feigin提供負載均衡的http用戶端
隻需要建立一個接口,然後添加注解即可。
Feign,主要是社群版,大家都習慣面向接口程式設計。這個是很多開發人員的規範。調用微服務通路兩種方法:
微服務名字 【ribbon】
接口和注解 【feign】
Feign能幹什麼?
Feign旨在使編寫Java Http用戶端變得更容易
前面在使用Ribbon + RestTemplate時,利用RestTemplate對Http請求的封裝處理,形成了一套模闆化的調用方法。但是在實際開發中,由于對服務依賴的調用可能不止一處,往往一個接口會被多處調用,是以通常都會針對每個微服務自行封裝一個用戶端類來包裝這些依賴服務的調用。是以,Feign在此基礎上做了進一步的封裝,由他來幫助我們定義和實作依賴服務接口的定義,在Feign的實作下,我們隻需要建立一個接口并使用注解的方式來配置它 (類似以前Dao接口上标注Mapper注解,現在是一個微服務接口上面标注一個Feign注解),即可完成對服務提供方的接口綁定,簡化了使用Spring Cloud Ribbon 時,自動封裝服務調用用戶端的開發量。
Feign預設內建了Ribbon
利用Ribbon維護了MicroServiceCloud-Dept的服務清單資訊,并且通過輪詢實作了用戶端的負載均衡,而與Ribbon不同的是,通過Feign隻需要定義服務綁定接口且以聲明式的方法,優雅而簡單的實作了服務調用。
分布式系統面臨的問題
複雜分布式體系結構中的應用程式有數十個依賴關系,每個依賴關系在某些時候将不可避免失敗!
多個微服務之間調用的時候,假設微服務A調用微服務B和微服務C,微服務B和微服務C又調用其他的微服務,這就是所謂的“扇出”,如果扇出的鍊路上某個微服務的調用響應時間過長,或者不可用,對微服務A的調用就會占用越來越多的系統資源,進而引起系統崩潰,所謂的“雪崩效應”。
對于高流量的應用來說,單一的後端依賴可能會導緻所有伺服器上的所有資源都在幾十秒内飽和。比失敗更糟糕的是,這些應用程式還可能導緻服務之間的延遲增加,備份隊列,線程和其他系統資源緊張,導緻整個系統發生更多的級聯故障,這些都表示需要對故障和延遲進行隔離和管理,以便單個依賴關系的失敗,不能取消整個應用程式或系統。
我們需要,棄車保帥。
什麼是Hystrix?
Hystrix是一個應用于處理分布式系統的延遲和容錯的開源庫,在分布式系統裡,許多依賴不可避免的會調用失敗,比如逾時,異常等,Hystrix能夠保證在一個依賴出問題的情況下,不會導緻整個體系服務失敗,避免級聯故障,以提高分布式系統的彈性。
“斷路器”本身是一種開關裝置,當某個服務單元發生故障之後,通過斷路器的故障監控 (類似熔斷保險絲) ,向調用方方茴一個服務預期的,可處理的備選響應 (FallBack) ,而不是長時間的等待或者抛出調用方法無法處理的異常,這樣就可以保證了服務調用方的線程不會被長時間,不必要的占用,進而避免了故障在分布式系統中的蔓延,乃至雪崩。
Hystrix能幹嘛?
服務限流
接近實時的監控
當一切正常時,請求流可以如下所示:
當許多後端系統中有一個問題時,它可以阻止整個使用者請求:
随着大容量通信量的增加,單個後端依賴項的潛在性會導緻所有伺服器上的所有資源在幾秒鐘内飽和。
應用程式中通過網絡或用戶端庫可能導緻網絡請求的每個點都是潛在故障的來源。比失敗更糟糕的是,這些應用程式還可能導緻服務之間的延遲增加,進而備份隊列、線程和其他系統資源,進而導緻更多跨系統的級聯故障。
當使用hystrix包裝每個基礎依賴項時,上面的圖表中所示的體系結構會發生類似于以下關系圖的變化。每個依賴項是互相隔離的,限制在延遲發生時它可以填充的資源中,并包含在回退邏輯中,該邏輯決定在依賴項中發生任何類型的故障時要做出什麼樣的響應:
官網資料:https://github.com/Netflix/Hystrix/wiki
什麼是服務熔斷?
熔斷機制是雪崩效應的一種微服務鍊路保護機制。
在微服務架構中,微服務之間的資料互動通過遠端調用完成,微服務A調用微服務B和微服務C,微服務B和微服務C又調用其它的微服務,此時如果鍊路上某個微服務的調用響應時間過長或者不可用,那麼對微服務A的調用就會占用越來越多的系統資源,進而引起系統崩潰,導緻“雪崩效應”。
服務熔斷是應對雪崩效應的一種微服務鍊路保護機制。例如在高壓電路中,如果某個地方的電壓過高,熔斷器就會熔斷,對電路進行保護。同樣,在微服務架構中,熔斷機制也是起着類似的作用。當調用鍊路的某個微服務不可用或者響應時間太長時,會進行服務熔斷,不再有該節點微服務的調用,快速傳回錯誤的響應資訊。當檢測到該節點微服務調用響應正常後,恢複調用鍊路。
當扇對外連結路的某個微服務不可用或者響應時間太長時,會進行服務的降級,進而熔斷該節點微服務的調用,快速傳回錯誤的響應資訊。檢測到該節點微服務調用響應正常後恢複調用鍊路。在SpringCloud架構裡熔斷機制通過Hystrix實作。Hystrix會監控微服務間調用的狀況,當失敗的調用到一定閥值預設是5秒内20次調用失敗,就會啟動熔斷機制。熔斷機制的注解是:@HystrixCommand 。
服務熔斷解決如下問題:
當所依賴的對象不穩定時,能夠起到快速失敗的目的;
快速失敗後,能夠根據一定的算法動态試探所依賴對象是否恢複。
為了避免因某個微服務背景出現異常或錯誤而導緻整個應用或網頁報錯,使用熔斷是必要的。
服務降級是指 當伺服器壓力劇增的情況下,根據實際業務情況及流量,對一些服務和頁面有政策的不處理或換種簡單的方式處理,進而釋放伺服器資源以保證核心業務正常運作或高效運作。說白了,就是盡可能的把系統資源讓給優先級高的服務。
資源有限,而請求是無限的。如果在并發高峰期,不做服務降級處理,一方面肯定會影響整體服務的性能,嚴重的話可能會導緻當機某些重要的服務不可用。是以,一般在高峰期,為了保證核心功能服務的可用性,都要對某些服務降級處理。比如當雙11活動時,把交易無關的服務統統降級,如檢視螞蟻深林,檢視曆史訂單等等。
服務降級主要用于什麼場景呢?
當整個微服務架構整體的負載超出了預設的上限門檻值或即将到來的流量預計将會超過預設的門檻值時,為了保證重要或基本的服務能正常運作,可以将一些 不重要 或 不緊急 的服務或任務進行服務的 延遲使用 或 暫停使用。降級的方式可以根據業務來,可以延遲服務,比如延遲給使用者增加積分,隻是放到一個緩存中,等服務平穩之後再執行 ;或者在粒度範圍内關閉服務,比如關閉相關文章的推薦。
例子
由上圖可得,當某一時間内服務A的通路量暴增,而B和C的通路量較少,為了緩解A服務的壓力,這時候需要B和C暫時關閉一些服務功能,去承擔A的部分服務,進而為A分擔壓力,叫做服務降級。
服務降級需要考慮的問題
1)那些服務是核心服務,哪些服務是非核心服務?
2)那些服務可以支援降級,那些服務不能支援降級,降級政策是什麼?
3)除服務降級之外是否存在更複雜的業務放通場景,政策是什麼?
自動降級分類
1)逾時降級:主要配置好逾時時間和逾時重試次數和機制,并使用異步機制探測回複情況。
2)失敗次數降級:主要是一些不穩定的api,當失敗調用次數達到一定閥值自動降級,同樣要使用異步機制探測回複情況。
3)故障降級:比如要調用的遠端服務挂掉了(網絡故障、DNS故障、Http服務傳回錯誤的狀态碼、RPC服務抛出異常),則可以直接降級。降級後的處理方案有:預設值(比如庫存服務挂了,傳回預設現貨)、兜底資料(比如廣告挂了,傳回提前準備好的一些靜态頁面)、緩存(之前暫存的一些緩存資料)。
4)限流降級:秒殺或者搶購一些限購商品時,此時可能會因為通路量太大而導緻系統崩潰,此時會使用限流來進行限制通路量,當達到限流閥值,後續請求會被降級;降級後的處理方案可以是:排隊頁面(将使用者導流到排隊頁面等一會重試)、無貨(直接告知使用者沒貨了)、錯誤頁(如活動太火爆了,稍後重試)。
服務熔斷—>服務端:某個服務逾時或異常,引起熔斷,類似于保險絲(自我熔斷)。
服務降級—>用戶端:從整體網站請求負載考慮,當某個服務熔斷或者關閉之後,服務将不再被調用,此時在用戶端,我們可以準備一個 FallBackFactory ,傳回一個預設的值(預設值)。會導緻整體的服務下降,但是好歹能用,比直接挂掉強。
觸發原因不太一樣,服務熔斷一般是某個服務(下遊服務)故障引起,而服務降級一般是從整體負荷考慮;管理目标的層次不太一樣,熔斷其實是一個架構級的處理,每個微服務都需要(無層級之分),而降級一般需要對業務有層級之分(比如降級一般是從最外圍服務開始)。
實作方式不太一樣,服務降級具有代碼侵入性(由控制器完成/或自動降級),熔斷一般稱為自我熔斷。
限流:限制并發的請求通路量,超過門檻值則拒絕。
降級:服務分優先級,犧牲非核心服務(不可用),保證核心服務穩定;從整體負荷考慮。
熔斷:依賴的下遊服務故障觸發熔斷,避免引發本系統崩潰;系統自動執行和恢複。
啟動類中使用@EnableCircuitBreaker啟動,CircuitBreaker(斷路器)
被監控的服務添加一個bean
什麼是Zuul?
Zull包含了對請求的路由(用來跳轉的)和過濾兩個最主要功能:
其中路由功能負責将外部請求轉發到具體的微服務執行個體上,是實作外部通路統一入口的基礎,而過濾器功能則負責對請求的處理過程進行幹預,是實作請求校驗,服務聚合等功能的基礎。Zuul和Eureka進行整合,将Zuul自身注冊為Eureka服務治理下的應用,同時從Eureka中獲得其他服務的消息,也即以後的通路微服務都是通過Zuul跳轉後獲得。
注意:Zuul服務最終還是會注冊進Eureka。
提供:代理+路由+過濾 三大功能
Zuul能幹嘛?
路由
過濾
官方文檔:https://github.com/Netflix/zuul/
詳情參考springcloud中文社群zuul元件 :https://www.springcloud.cc/spring-cloud-greenwich.html#_router_and_filter_zuul
Spring Cloud Config為分布式系統中的外部配置提供伺服器和用戶端支援。
使用Config Server,您可以在所有環境中管理應用程式的外部屬性。用戶端和伺服器上的概念映射與Spring Environment和PropertySource抽象相同,是以它們與Spring應用程式非常契合,但可以與任何以任何語言運作的應用程式一起使用。随着應用程式通過從開發人員到測試和生産的部署流程,您可以管理這些環境之間的配置,并确定應用程式具有遷移時需要運作的一切。伺服器存儲後端的預設實作使用git,是以它輕松支援标簽版本的配置環境,以及可以通路用于管理内容的各種工具。很容易添加替代實作,并使用Spring配置将其入。
學無止境,加油。