案例描述: 一個普通的事務送出,在應用裡面會提示commit逾時,失敗。
一、理論知識
1、關于commit原理,事務送出過程
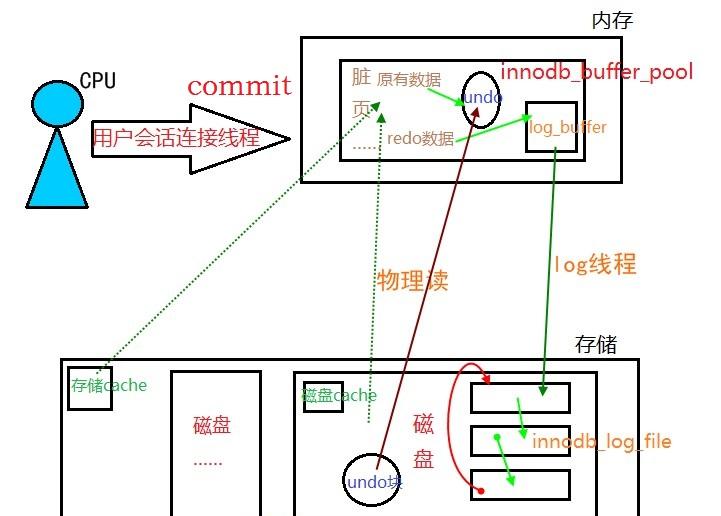
1、尋找修改的資料頁:
1、如果該資料頁在記憶體中,則直接是記憶體讀;
2、如果該資料頁記憶體中沒有,實體讀,就從磁盤調入記憶體;
2、磁盤中的undo頁調入記憶體;
3、先将原來的資料存入undo,然後修改資料(資料頁成髒頁);
4、修改資料的資訊生成redo資料存入log_buffer(記憶體buffer_pool的一個空間,預設16M)中;
5、log_buffer通過log線程(背景線程,非常勤快),持續不斷的将redo資訊寫入disk的innodb_log_file中;
6、事務送出,刻意觸發log線程,将剩餘的log_buffer中的redo資料資訊寫入磁盤中,資料量已剩不多,寫完送出成功。
注意:
1、修改記錄前,一定要先寫日志;
“日志先行”,這是資料庫最基本的原則。
2、事務送出過程中,一定要保證日志先落盤,才能算事務送出完成。
3、意外掉電,記憶體髒頁丢失,但是磁盤的innodb_log_file中存放了redo日志資訊,待重新開機伺服器,MySQL通過讀取磁盤的log_files資料,自動将資料的修改重新跑一邊。
Q:為什麼mysql commit速度總是很快,盡管事務修改的資料量可能很大? A: 因為事務送出,并不是對磁盤資料進行修改,而是将修改資料的redo資訊通過背景log線程寫入磁盤的redo logfile中,完成mysql commit,無論事務修改的資料量有多大,這個過程速度是很快的。 而記憶體中的髒塊,也就是修改後的資料頁,正常情況下是由背景相關write線程周期性的将髒頁資料刷入磁盤中,保證innodb buffer pool有足夠的幹淨塊、可用塊。
2、關于rollback原理,復原過程
1、MySQL讀取記憶體中undo頁資訊
2、通過undo資訊找到髒頁,反着對資料進行修改
3、do、undo的時間相同,且都會産成redo資訊
4、事務送出
MySQL復原處理機制:
如果線程中斷,事務沒有送出,undo會将記錄此資訊,待另一會話程序連上,檢視該塊資料資訊,MySQL自動復原進行資料頁修改,然後被讀取。也就是說為了避免系統因為rollback被hang住,通過直接殺死程序的方式,中斷事務,等待後來者要讀取該資料資訊時進行復原,再傳回結果。
Q:rollback為什麼有時候很慢,rollback的風險和風險避免方式? rollback的時間取決于復原前事務修改資料的時間,處理量大復原時間長,處理量小復原時間短。 1、rollback風險:容易導緻系統被hang住; 2、風險避免方式:直接殺死會話程序或是mysql程序。
3、存儲寫入性能分析
Q:mysql commit,存儲為什麼寫速度能夠保持在0ms,極少出現1ms情況?
對于存儲來說,寫性能相當高:假設存儲cache總有空閑空間的情況下,事務送出,将log buffer中剩餘的很少的redo資料寫入存儲cache,即為完成mysql commit,這個過程是相當快的(能夠保持在0ms,極少出現1ms情況),後續redo資料由cache寫入磁盤的過程是背景進行。
4、存儲級别的災備(同城災備)
1、災備同步過程:commit
1、redo、binlog寫入本地存儲cache;
2、通過網絡同步binlog寫入遠端同步的伺服器的存儲cache中;
3、響應本地資料庫;
4、事務送出成功;
2、風險:
網絡出現問題(信号斷續,纜線斷了),導緻寫hang住,commit逾時失敗。
3、解決:
通過逾時設定,網絡中斷超過限制,自動将同步改為災備異步,盡可能少的影響業務commit逾時失敗。
二、分析與處理
存儲寫性能比較差,很多時段會達到5ms,甚至于10ms以上
備注:災備同步已經停止的情況下。
1、存儲中BBU問題,出現監控BBU的bug;
解決:重新開機BBU,不行就更新BBU。
2、cache被占滿
1、海量資料寫入,commit資料占滿cache;
2、硬碟I/O異常,異常SQL導緻的海量實體讀;
解決:索引優化。
3、存儲性能差
解決:找老闆掏錢,更換優質裝置。
本文轉自 sshpp 51CTO部落格,原文連結:http://blog.51cto.com/12902932/1949356,如需轉載請自行聯系原作者
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)