在CAP理論與MongoDB一緻性、可用性的一些思考一文中提到,MongoDB提供了一些選項,如Read Preference、Read Concern、Write Concern,對MongoDB的一緻性、可用性、可靠性(durability)、性能會有較大的影響。與Read Concern、Write Concern不同的是,Read Preference基本上完全由MongoDb Driver實作,是以,本文通過PyMongo來看看Read Preference具體是如何實作的。
本文分析的PyMongo版本是PyMongo3.6,該版本相容MongoDB3.6及以下的MongoDB。
本文位址:https://www.cnblogs.com/xybaby/p/10256812.html
Read preference describes how MongoDB clients route read operations to the members of a replica set.
Read Prefenrece決定了使用複制集(replica set)時,讀操作路由到哪個mongod節點,如果使用Sharded Cluster,路由選擇由Mongos決定,如果直接使用replica set,那麼路由選擇由driver決定。如下圖所示:
MongoDB提供了以下Read Preference Mode:
primary:預設模式,一切讀操作都路由到replica set的primary節點
primaryPreferred:正常情況下都是路由到primary節點,隻有當primary節點不可用(failover)的時候,才路由到secondary節點。
secondary:一切讀操作都路由到replica set的secondary節點
secondaryPreferred:正常情況下都是路由到secondary節點,隻有當secondary節點不可用的時候,才路由到primary節點。
nearest:從延時最小的節點讀取資料,不管是primary還是secondary。對于分布式應用且MongoDB是多資料中心部署,nearest能保證最好的data locality。
這五種模式還受到maxStalenessSeconds和tagsets的影響。
不同的read Preference mode适合不同的應用場景,如果資料的一緻性很重要,比如必須保證read-after-write一緻性,那麼就需要從primary讀,因為secondary的資料有一定的滞後。如果能接受一定程度的stale data,那麼從secondary讀資料可以減輕primary的壓力,且在primary failover期間也能提供服務,可用性更高。如果對延時敏感,那麼适合nearest。另外,通過tagsets,還可以有更豐富的定制化讀取政策,比如指定從某些datacenter讀取。
首先給出pymongo中與read preference相關的類,友善後面的分析。
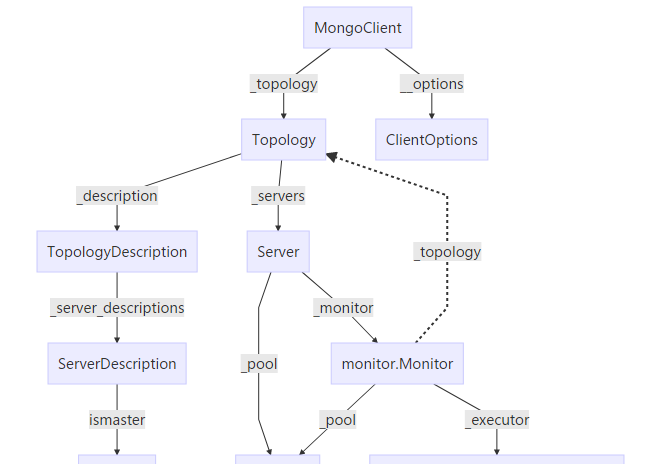
上圖中實線箭頭表示強引用(複合),虛線箭頭表示弱引用(聚合)
PyMongo的文檔給出了如何連接配接到複制集:指定複制集的名字,以及一個或多個該複制集内的節點。如:
MongoClient('localhost', replicaset='foo')
上述操作是non-blocking,立即傳回,通過背景線程去連接配接指定節點,PyMongo連接配接到節點後,會從mongod節點擷取到複制集内其他節點的資訊,然後再連接配接到複制集内的其他節點。
from time import sleep c = MongoClient('localhost', replicaset='foo'); print(c.nodes); sleep(0.1); print(c.nodes) frozenset([]) frozenset([(u'localhost', 27019), (u'localhost', 27017), (u'localhost', 27018)])
可以看到,剛初始化MongoClient執行個體時,并沒有連接配接到任何節點(c.nodes)為空;過了一段時間,再檢視,那麼會發現已經連上了複制集内的三個節點。
那麼問題來了,建立MongoClient後,尚未連接配接到複制集節點之前,能否立即操作資料庫?
If you need to do any operation with a MongoClient, such as a find() or an insert_one(), the client waits to discover a suitable member before it attempts the operation.
通過後續的代碼分析可以看到,會通過一個條件變量(threading.Condition)去協調。
上面提到,初始化MongoClient對象的時候,會通過指定的mognod節點去發現複制集内的其他節點,這個就是通過<code>monitor.Monitor</code>來實作的。從上面的類圖可以看到,每一個server(與一個mongod節點對應)都有一個monitor。Monitor的作用在于:
Health: detect when a member goes down or comes up, or if a different member becomes primary
Configuration: detect when members are added or removed, and detect changes in members’ tags
Latency: track a moving average of each member’s ping time
Monitor會啟動一個背景線程 <code>PeriodExecutor</code>,定時(預設10s)通過socket連接配接<code>Pool</code>給對應的mongod節點發送 ismaster 消息。核心代碼(略作調整)如下
類<code>IsMaster</code>是對ismaster command reponse的封裝,比較核心的屬性包括:
replica_set_name:從mongod節點看來,複制集的名字
primary:從mongod節點看來,誰是Priamry
all_hosts: 從mongod節點看來,複制集中的所有節點
last_write_date: mongod節點最後寫入資料的時間,用來判斷secondary節點的staleness
set_version:config version
election_id:隻有當mongod是primary時才會設定,表示最新的primary選舉編号
當某個server的monitor擷取到了在server對應的mongod上的複制集資訊資訊時,調用<code>Tolopogy.on_change</code>更新複制集的拓撲資訊:
核心在<code>updated_topology_description</code>, 根據本地記錄的topology資訊,以及收到的server_description(來自IsMaster- ismaster command response),來調整本地的topology資訊。以一種情況為例:收到一個ismaster command response,對方自稱自己是primary,不管目前topology有沒有primary,都會進入調用以下函數
注意看docstring中的Returns,都是傳回新的複制集資訊
那麼整個函數從上往下檢查
是不是同一個複制集
新節點(自認為是primary)與topology記錄的primary相比,誰更新。比較(set_version, election_id)
比較set_servion
如果topology中已經有stale primary,那麼将其server-type改成Unknown
從Primary節點的all_hosts中取出新加入複制集的節點
移除已經不存在于複制集中的節點
PyMongo關于複制集的狀态都來自于所有節點的ismaster消息,Source of Truth在于複制集,而且這個Truth來自于majority 節點。是以,某個節點傳回給driver的資訊可能是過期的、錯誤的,driver通過有限的資訊判斷複制集的狀态,如果判斷失誤,比如将寫操作發到了stale primary上,那麼會在複制集上再次判斷,保證正确性。
前面詳細介紹了PyMongo是如何更新複制集的資訊,那麼這一部分來看看基于拓撲資訊具體是如何根據read preference路由到某個節點上的。
我們從Collection.find出發,一路跟蹤, 會調用<code>MongoClient._send_message_with_response</code>
代碼很清晰,根據指定的address或者read_preference, 選擇出server,然後通過server發請求,等待回複。topology.select_server一路調用到下面這個函數
可以看到,不一定能一次選出來,如果選不出server,意味着此時還沒有連接配接到足夠多的mongod節點,那麼等待一段時間(<code>_condition.wait</code>)重試。在上面Topology.on_change 可以看到,會調用<code>_condition.notify_all</code>喚醒。
上面selector就是<code>read_preference._ServerMode</code>的某一個子類,以<code>Nearest</code>為例
首先要受到maxStalenessSeconds的限制,然後再用tagsets過濾一遍,這裡隻關注前者。
關于maxStalenessSeconds
The read preference maxStalenessSeconds option lets you specify a maximum replication lag, or “staleness”, for reads from secondaries. When a secondary’s estimated staleness exceeds maxStalenessSeconds, the client stops using it for read operations.
怎麼計算的,如果節點有primary,則調用下面這個函數
上面的代碼用到了IsMaster的last_write_date屬性,正是用這個屬性來判斷staleness。
公式的解釋可參考max-staleness.rst
個人覺得可以這麼了解:假設網絡延時一緻,如果在同一時刻收到心跳回複,那麼隻用P.lastWriteDate - S.lastWriteDate就行了,但心跳時間不同,是以得算上時間差。我會寫成(P.lastWriteDate - S.lastWriteDate) + (S.lastUpdateTime - P.lastUpdateTime) 。加上 心跳間隔是基于悲觀假設,如果剛心跳完之後secondary就停止複制,那麼在下一次心跳之前最多的stale程度就得加上 心跳間隔。
從代碼可以看到Nearest找出了所有可讀的節點,然後通過<code>apply_local_threshold</code>函數來刷選出最近的。
Read preference
PyMongo 3.6.0 Documentation
本文版權歸作者xybaby(博文位址:http://www.cnblogs.com/xybaby/)所有,歡迎轉載和商用,請在文章頁面明顯位置給出原文連結并保留此段聲明,否則保留追究法律責任的權利,其他事項,可留言咨詢。
![windows 解壓安裝Mogdb[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)