Kombu 的定位是一個相容 AMQP 協定的消息隊列抽象,是一個把消息傳遞封裝成統一接口的庫。其特點是支援多種的符合APMQ協定的消息隊列系統。通過本系列,大家可以了解 Kombu 是如何實作 AMQP。本文先介紹相關概念和整體邏輯架構。
目錄
[源碼解析] 消息隊列 Kombu 之 基本架構
0x00 摘要
0x01 AMQP
1.1 基本概念
1.2 工作過程
0x02 Poll系列模型
2.1 select
2.2 poll
2.3 epoll
2.4 通俗了解
2.4.1 阻塞I/O模式
2.4.2 非阻塞模式
2.4.2.1 代理模式
2.4.2.2 epoll
0x03 Kombu 基本概念
3.1 用途
3.2 術語
0x04 概念具體說明
4.1 概述
4.2 Connection
4.3 Channel
4.3.1 定義
4.3.2 redis消息回調函數
4.4 Transport
4.5 MultiChannelPoller
4.6 Consumer
4.7 Producer
4.8 Hub
4.8.1 自己的poller
4.8.2 Connection
4.8.3 聯系
4.8.4 定義
0x05 總結
5.1 邏輯
5.2 示例圖
0xFF 參考
從本文開始,我們通過一個系列來介紹消息隊列 Kombu(為後續Celery分析打基礎)。
Kombu 的定位是一個相容 AMQP 協定的消息隊列抽象,是一個把消息傳遞封裝成統一接口的庫。其特點是支援多種的符合APMQ協定的消息隊列系統。不僅支援原生的AMQP消息隊列如RabbitMQ、Qpid,還支援虛拟的消息隊列如redis、mongodb、beantalk、couchdb、in-memory等。
通過本系列,大家可以了解 Kombu 是如何實作 AMQP。本文先介紹相關概念和整體邏輯架構。
介紹 AMQP 是因為 Kombu 的定位是一個相容 AMQP 協定的消息隊列抽象。
AMQP(Advanced Message Queuing Protocol,進階消息隊列協定)是一個程序間傳遞異步消息的網絡協定。
AMQP的基本概念如下:
生産者和消費者:生産者建立消息,然後釋出到代理伺服器的隊列中,代理伺服器會把消息發送給感興趣的接受方。消費者連接配接到代理伺服器,并訂閱到隊列上,進而接收消息。
通道 channel:信道是 “真實的” TCP連接配接内的虛拟連接配接,AMQP的指令都是通過通道發送的。在一條TCP連接配接上可以建立多條信道。
有些應用需要與 AMQP 代理建立多個連接配接。同時開啟多個 TCP 連接配接不合适,因為會消耗掉過多的系統資源并且使得防火牆的配置更加困難。AMQP 0-9-1 提供了通道(channels)來處理多連接配接,可以把通道了解成共享一個 TCP 連接配接的多個輕量化連接配接。
在涉及多線程 / 程序的應用中,為每個線程 / 程序開啟一個通道(channel)是很常見的,并且這些通道不能被線程 / 程序共享。
一個特定通道上的通訊與其他通道上的通訊是完全隔離的,是以每個 AMQP 方法都需要攜帶一個通道号,這樣用戶端就可以指定此方法是為哪個通道準備的。
隊列:存放消息的地方,隊列通過路由鍵綁定到交換機,生産者通過交換機将消息發送到隊列中。我們可以說應用注冊了一個消費者,或者說訂閱了一個隊列。一個隊列可以注冊多個消費者,也可以注冊一個獨享的消費者(當獨享消費者存在時,其他消費者即被排除在外)。
Exchange 和 綁定:生産者釋出消息時,先将消息發送到Exchange,通過Exchange與隊列的綁定規則将消息發送到隊列。
交換機是用來發送消息的 AMQP 實體。交換機拿到一個消息之後将它路由給一個或零個隊列。它使用哪種路由算法是由交換機類型和綁定(Bindings)規則所決定的。
交換機根據路由規則将收到的消息分發給與該交換機綁定的隊列(Queue)。
常見的Exchange有topic、fanout、direct:
direct Exchange:direct交換機是包含空白字元串的預設交換機,當聲明隊列時會主動綁定到預設交換機,并且以隊列名稱為路由鍵;
fanout Exchange:這種交換機會将收到的消息廣播到綁定的隊列;
topic Exchange:topic交換機可以通過路由鍵的正規表達式将消息發送到多個隊列;
工作過程是:
釋出者(Publisher)釋出消息(Message),經由交換機(Exchange)。消息從來不直接發送給隊列,甚至 Producers 都可能不知道隊列的存在。 消息是發送給交換機,給交換機發送消息時,需要指定消息的 routing_key 屬性;
交換機根據路由規則将收到的消息分發給與該交換機綁定的隊列(Queue)。交換機收到消息後,根據 交換機的類型,或直接發送給隊列 (fanout), 或比對消息的 routing_key 和 隊列與交換機之間的 banding_key。 如果比對,則遞交消息給隊列;
最後 AMQP 代理會将消息投遞給訂閱了此隊列的消費者,或者消費者按照需求自行擷取。Consumers 從隊列取得消息;
基本如下圖:
Kombu 利用了 Poll 模型,是以我們有必要介紹下。這就是IO多路複用。
IO多路複用是指核心一旦發現程序指定的一個或者多個IO條件準備讀取,它就通知該程序。IO多路複用适用比如當客戶處理多個描述字時(一般是互動式輸入和網絡套接口)。
與多程序和多線程技術相比,I/O多路複用技術的最大優勢是系統開銷小,系統不必建立程序/線程,也不必維護這些程序/線程,進而大大減小了系統的開銷。
select 通過一個select()系統調用來監視多個檔案描述符的數組(在linux中一切事物皆檔案,塊裝置,socket連接配接等)。
當select()傳回後,該數組中就緒的檔案描述符便會被核心修改标志位(變成ready),使得程序可以獲得這些檔案描述符進而進行後續的讀寫操作(select會不斷監視網絡接口的某個目錄下有多少檔案描述符變成ready狀态【在網絡接口中,過來一個連接配接就會建立一個'檔案'】,變成ready狀态後,select就可以操作這個檔案描述符了)。
poll 和select在本質上沒有多大差别,但是poll沒有最大檔案描述符數量的限制。
poll和select同樣存在一個缺點就是,包含大量檔案描述符的數組被整體複制于使用者态和核心的位址空間之間,而不論這些檔案描述符是否就緒,它的開銷随着檔案描述符數量的增加而線性增大。
select()和poll()将就緒的檔案描述符告訴程序後,如果程序沒有對其進行IO操作,那麼下次調用select()和poll() 的時候将再次報告這些檔案描述符,是以它們一般不會丢失就緒的消息,這種方式稱為水準觸發(Level Triggered)。
epoll由核心直接支援,可以同時支援水準觸發和邊緣觸發(Edge Triggered,隻告訴程序哪些檔案描述符剛剛變為就緒狀态,它隻說一遍,如果我們沒有采取行動,那麼它将不會再次告知,這種方式稱為邊緣觸發),理論上邊緣觸發的性能要更高一些。
epoll同樣隻告知那些就緒的檔案描述符,而且當我們調用epoll_wait()獲得就緒檔案描述符時,傳回的不是實際的描述符,而是一個代表 就緒描述符數量的值,你隻需要去epoll指定的一個數組中依次取得相應數量的檔案描述符即可,這裡也使用了記憶體映射(mmap)技術,這樣便徹底省掉了 這些檔案描述符在系統調用時複制的開銷。
另一個本質的改進在于epoll采用基于事件的就緒通知方式。在select/poll中,程序隻有在調用一定的方法後,核心才對所有監視的檔案描 述符進行掃描,而epoll事先通過epoll_ctl()來注冊一個檔案描述符,一旦基于某個檔案描述符就緒時,核心會采用類似callback的回調 機制,迅速激活這個檔案描述符,當程序調用epoll_wait()時便得到通知。
阻塞I/O模式下,核心對于I/O事件的處理是阻塞或者喚醒,一個線程隻能處理一個流的I/O事件。如果想要同時處理多個流,要麼多程序(fork),要麼多線程(pthread_create),很不幸這兩種方法效率都不高。
非阻塞忙輪詢的I/O方式可以同時處理多個流。我們隻要不停的把所有流從頭到尾問一遍,又從頭開始。這樣就可以處理多個流了,但這樣的做法顯然不好,因為如果所有的流都沒有資料,那麼隻會白白浪費CPU。
非阻塞模式下可以把I/O事件交給其他對象(select以及epoll)處理甚至直接忽略。
為了避免CPU空轉,可以引進一個代理(一開始有一位叫做select的代理,後來又有一位叫做poll的代理,不過兩者的本質是一樣的)。這個代理比較厲害,可以同時觀察許多流的I/O事件,在空閑的時候,會把目前線程阻塞掉,當有一個或多個流有I/O事件時,就從阻塞态中醒來,于是我們的程式就會輪詢一遍所有的流(于是我們可以把“忙”字去掉了)。代碼長這樣:
于是,如果沒有I/O事件産生,我們的程式就會阻塞在select處。但是依然有個問題,我們從select那裡僅僅知道了,有I/O事件發生了,但卻并不知道是那幾個流(可能有一個,多個,甚至全部),我們隻能無差别輪詢所有流,找出能讀出資料,或者寫入資料的流,對他們進行操作。
epoll可以了解為event poll,不同于忙輪詢和無差别輪詢,epoll隻會把哪個流發生了怎樣的I/O事件通知我們。此時我們對這些流的操作都是有意義的(複雜度降低到了O(1))。
epoll版伺服器實作原理類似于select版伺服器,都是通過某種方式對套接字進行檢驗其是否能收發資料等。但是epoll版的效率要更高,同時沒有上限。
在select、poll中的檢驗,是一種被動的輪詢檢驗,而epoll中的檢驗是一種主動地事件通知檢測,即:當有套接字元合檢驗的要求,便會主動通知,進而進行操作。這樣的機制自然效率會高一點。
同時在epoll中要用到檔案描述符,所謂檔案描述符實質上是數字。
epoll的主要用處在于:
如果程序在處理while循環中的代碼時,一些套接字對應的用戶端如果發來了資料,那麼作業系統底層會自動的把這些套接字對應的檔案描述符寫入該清單中,當程序再次執行到epoll時,就會得到了這個清單,此時這個清單中的資訊就表示着哪些套接字可以進行收發了。因為epoll沒有去依次的檢視,而是直接拿走已經可以收發的fd,是以效率高!
Kombu的最初的實作叫做carrot,後來經過重構才成了Kombu。
Kombu 主要用途如下:
Celery是Python中最流行的異步消息隊列架構,支援RabbitMQ、Redis、ZoopKeeper等作為Broker,而對這些消息隊列的抽象,都是通過Kombu實作的:
Celery一開始先支援的RabbitMQ,也就是使用 AMQP 協定。由于要支援越來越多的消息代理,但是這些消息代理是不支援 AMQP 協定的,需要一個東西把所有的消息代理的處理方式統一起來,甚至可以了解為把它們「僞裝成支援AMQ協定」。
Kombu實作了對AMQP transport和non-AMQP transports(Redis、Amazon SQS、ZoopKeeper等)的相容。
OpenStack 預設 是使用kombu連接配接rabbitmq伺服器。OpenStack使用kombu作為消息隊列使用的client庫而沒有用廣泛使用的pika庫有兩個原因:
kombu除了支援純AMQP的實作還支援虛拟AMQP的實作作為消息隊列系統,如redis、mongodb、beantalk等。
kombu可以通過配置設定AMQP連接配接的底層庫,比如librabbitmq或者pyamqp。前者是一個python嫁接C庫的實作,後者是一個純python的實作。如果用純python實作的AMQP庫,就可以應用eventlet的架構将設計網絡IO的部分變為協程,提高整體的網絡IO性能。如openstack内部使用的就是eventlet的架構。
在 Kombu 中,存在多個概念(部分和AMQP類似),他們分别是:
Message:消息,發送和消費的主體,生産消費的基本機關,其實就是我們所謂的一條條消息;
Connection:對 MQ 連接配接的抽象,一個 Connection 就對應一個 MQ 的連接配接;Connection 是 AMQP 對 連接配接的封裝;
Channel:與AMQP中概念類似,可以了解成共享一個Connection的多個輕量化連接配接;Channel 是 AMQP 對 MQ 的操作的封裝;
Transport:kombu 支援将不同的消息中間件以插件的方式進行靈活配置,使用transport這個術語來表示一個具體的消息中間件,可以認為是對broker的抽象:
對 MQ 的操作必然離不開連接配接,但是,Kombu 并不直接讓 Channel 使用 Connection 來發送/接受請求,而是引入了一個新的抽象 Transport,Transport 負責具體的 MQ 的操作,也就是說 Channel 的操作都會落到 Transport 上執行。引入transport這個抽象概念可以使得後續添加對non-AMQP的transport非常簡單;
Transport是真實的 MQ 連接配接,也是真正連接配接到 MQ(redis/rabbitmq) 的執行個體;
目前Kombu中build-in支援有Redis、Beanstalk、Amazon SQS、CouchDB,、MongoDB,、ZeroMQ,、ZooKeeper、SoftLayer MQ和Pyro;
Producers: 發送消息的抽象類;
Consumers:接受消息的抽象類。consumer需要聲明一個queue,并将queue與指定的exchange綁定,然後從queue裡面接收消息;
Exchange:MQ 路由,這個和 RabbitMQ 差不多,支援 5 類型。消息發送者将消息發至Exchange,Exchange負責将消息分發至隊列。用于路由消息(消息發給exchange,exchange發給對應的queue)。路由就是比較routing-key(這個message提供)和binding-key(這個queue注冊到exchange的時候提供)。使用時,需要指定exchange的名稱和類型(direct,topic和fanout)。
交換機通過比對消息的 routing_key 和 binding_key來轉發消息,binding_key 是consumer 聲明隊列時與交換機的綁定關系。
Queue:對應的 queue 抽象,存儲着即将被應用消費掉的消息,Exchange負責将消息分發Queue,消費者從Queue接收消息。
Routing keys: 每個消息在發送時都會聲明一個routing_key。routing_key的含義依賴于exchange的類型。一般說來,在AMQP标準裡定義了四種預設的exchange類型,此外,vendor還可以自定義exchange的類型。最常用的三類exchange為:
Direct exchange: 如果message的routing_key和某個consumer中的routing_key相同,就會把消息發送給這個consumer監聽的queue中。
Fan-out exchange: 廣播模式。exchange将收到的message發送到所有與之綁定的queue中。
Topic exchange: 該類型exchange會将message發送到與之routing_key類型相比對的queue中。routing_key由一系列“.”隔開的word組成,“*”代表比對任何word,“#”代表比對0個或多個word,類似于正規表達式。
以 redis 為 broker,我們簡要說明:
發送消息的對象,稱為生産者Producer。
connections建立 redis 連接配接,channel 是一次連接配接會話。
Exchange 負責交換消息,消息通過channel發送到Exchange,由于Exchange綁定Queue和routing_key。消息會被轉發到 redis 中比對routing_key的Queue中。
在Queue另一側的消費者Consumer 一直對Queue進行監聽,一旦Queue中存在資料,則調用callback方法處理消息。
Connection是對 MQ 連接配接的抽象,一個 Connection 就對應一個 MQ 的連接配接。現在就是對 <code>'redis://localhost:6379'</code> 連接配接進行抽象。
由之前論述可知,Connection是到broker的連接配接。從具體代碼可以看出,Connection更接近是一個邏輯概念,具體功能都委托給别人完成。
Connection主要成員變量是:
_connection:kombu.transport.redis.Transport 類型,就是真正用來負責具體的 MQ 的操作,也就是說對 Channel 的操作都會落到 Transport 上執行。
_transport:就是上面提到的對 broker 的抽象。
cycle:與broker互動的排程政策。
failover_strategy:在連接配接失效時,選取其他hosts的政策。
heartbeat:用來實施心跳。
精簡版定義如下:
Channel:與AMQP中概念類似,可以了解成共享一個Connection的多個輕量化連接配接。就是真正的連接配接。
Connection 是 AMQP 對 連接配接的封裝;
Channel 是 AMQP 對 MQ 的操作的封裝;
Channel 可以認為是 redis 操作和連接配接的封裝。每個 Channel 都可以與 redis 建立一個連接配接,在此連接配接之上對 redis 進行操作,每個連接配接都有一個 socket,每個 socket 都有一個 file,從這個 file 可以進行 poll。
簡化版定義如下:
關于上面成員變量,這裡需要說明的是
這是redis有消息時的回調函數,即:
BPROP 有消息時候,調用 Channel._brpop_read;
LISTEN 有消息時候,調用 Channel._receive;
大約如下:
手機如圖:
Transport:真實的 MQ 連接配接,也是真正連接配接到 MQ(redis/rabbitmq) 的執行個體。就是存儲和發送消息的實體,用來區分底層消息隊列是用amqp、Redis還是其它實作的。
我們順着上文理一下:
那麼兩者的關系就是對 MQ 的操作必然離不開連接配接,但是 Kombu 并不直接讓 Channel 使用 Connection 來發送/接受請求,而是引入了一個新的抽象 Transport,Transport 負責具體的 MQ 的操作,也就是說 Channel 的操作都會落到 Transport 上執行;
在Kombu 體系中,用 transport 對所有的 broker 進行了抽象,為不同的 broker 提供了一緻的解決方案。通過Kombu,開發者可以根據實際需求靈活的選擇或更換broker。
Transport負責具體操作,但是 很多操作移交給 loop 與 MultiChannelPoller 進行。
其主要成員變量為:
本transport的驅動類型,名字;
對應的 Channel;
cycle:MultiChannelPoller,具體下文會提到;
其中重點是MultiChannelPoller。一個Connection有一個Transport, 一個Transport有一個MultiChannelPoller,對poll操作都是由MultiChannelPoller完成,redis操作由channel完成。
定義如下:
MultiChannelPoller 定義如下,可以了解為 執行 engine,主要作用是:
收集 channel;
建立 socks fd 到 channel 的映射;
建立 channel 到 socks fd 的映射;
使用 poll;
或者從邏輯上這麼了解,MultiChannelPoller 就是:
把 Channel 對應的 socket 同 poll 聯系起來,一個 socket 在 linux 系統中就是一個file,就可以進行 poll 操作;
把 poll 對應的 fd 添加到 MultiChannelPoller 這裡,這樣 MultiChannelPoller 就可以 打通 <code>Channel ---> socket ---> poll ---> fd ---> 讀取 redis</code> 這條通路了,就是如果 redis 有資料來了,MultiChannelPoller 就馬上通過 poll 得到通知,就去 redis 讀取;
具體定義如下:
Consumer 是消息接收者。Consumer & 相關元件 的作用主要如下:
Exchange:MQ 路由,消息發送者将消息發至 Exchange,Exchange 負責将消息分發至隊列。
Queue:對應的隊列抽象,存儲着即将被應用消費掉的消息,Exchange 負責将消息分發 Queue,消費者從Queue 接收消息;
Consumers 是接受消息的抽象類,consumer 需要聲明一個 queue,并将 queue 與指定的 exchange 綁定,然後從 queue 裡面接收消息。就是說,從使用者角度,知道了一個 exchange 就可以從中讀取消息,而具體這個消息就是從 queue 中讀取的。
在具體 Consumer 的實作中,它把 queue 與 channel 聯系起來。queue 裡面有一個 channel,用來通路redis,也有 Exchange,知道通路具體 redis 哪個key(就是queue對應的那個key)。
Consumer 消費消息是通過 Queue 來消費,然後 Queue 又轉嫁給 Channel。
是以服務端的邏輯大緻為:
建立連接配接;
建立Exchange ;
建立Queue,并将Exchange與Queue綁定,Queue的名稱為routing_key ;
建立Consumer對Queue監聽;
Consumer 定義如下:
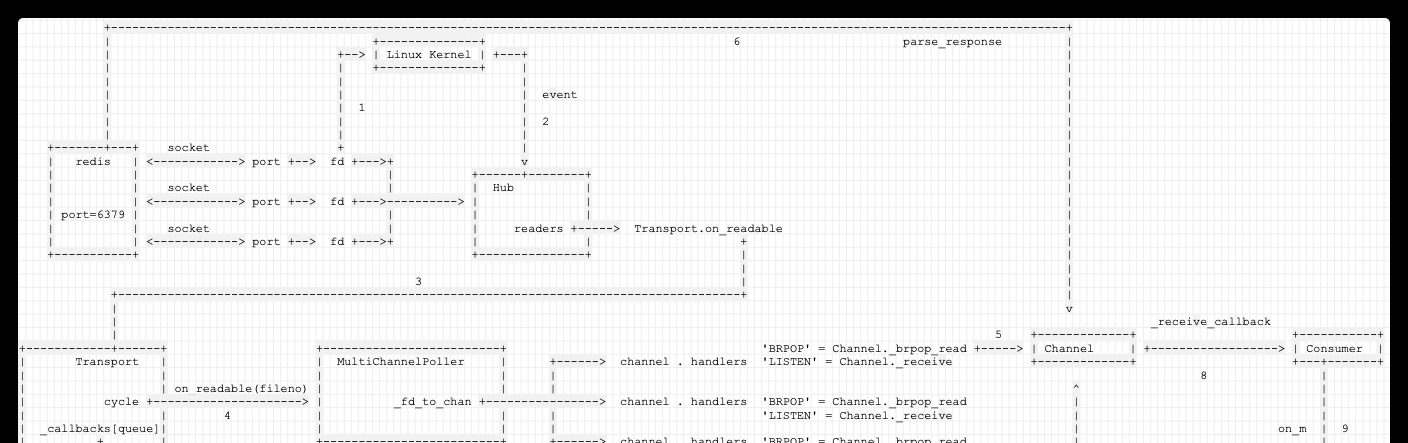
此時總體邏輯如下圖:
手機如下:

現在我們知道:
Producer 是消息發送者。Producer中,主要變量是:
_channel :就是channel;
exchange :exchange;
邏輯如圖:
使用者可以通過同步方式自行讀取消息,如果不想自行讀取,也可以通過Hub(本身建構了一個異步消息引擎)讀取。
Hub 是一個eventloop,擁有自己的 poller。
前面在 MultiChannelPoller 中間提到了,MultiChannelPoller 會建立了自己内部的 poller。但是實際上在注冊時候,Transport 會使用 hub 的 poller,而非 MultiChannelPoller 内部的 poller。
Connection注冊到Hub,一個Connection對應一個Hub。
在注冊過程中,Hub 把自己内部的 poller 配置在 Transport 之中。這樣就通過 transport 内部的 MultiChannelPoller 可以把 Hub . poller 和 Channel 對應的 socket 同poll聯系起來,一個 socket 在 linux 系統中就是一個file,就可以進行 poll 操作;
因而,如前面所述,這樣 MultiChannelPoller 就可以 打通 <code>Channel ---> socket ---> poll ---> fd ---> 讀取 redis</code> 這條通路了,就是如果 redis 有資料來了,MultiChannelPoller 就馬上通過 poll 得到通知,就去 redis 讀取。
Hub定義如下:
我們通過文字和圖例來總結下本文。
Message:消息,發送和消費的主體,其實就是我們所謂的一條條消息;
Connection是AMQP對消息隊列連接配接的封裝抽象,那麼兩者的關系就是:對MQ的操作必然離不開連接配接。
Channel是AMQP對MQ的操作的封裝,可以了解成共享一個Connection的多個輕量化連接配接。
<code>Channel</code>将<code>Consumer</code>标簽,<code>Consumer</code>要消費的隊列,以及标簽與隊列的映射關系都記錄下來,等待循環調用。
還通過<code>Transport</code>将隊列與回調函數清單的映射關系記錄下來。
Kombu對所有需要監聽的隊列<code>_active_queues</code>都查詢一遍,直到查詢完畢或者遇到一個可以使用的Queue,然後就擷取消息,回調此隊列對應的callback。
Channel初始化的過程就是連接配接的過程。
Kombu并不直接讓Channel使用Connection來發送/接受請求,而是引入了一個新的抽象Transport,Transport負責具體的MQ的操作,也就是說Channel的操作都會落到Transport上執行。是以Transport為中心,把Channel代表的真實redis與Hub其中的poll聯系起來。
Queue:消息隊列,消息内容的載體,存儲着即将被應用消費掉的消息。Exchange 負責将消息分發 Queue,消費者從 Queue 接收消息;
Exchange:交換機,消息發送者将消息發至 Exchange,Exchange 負責将消息分發至 Queue;
消息發送是交給 Exchange 來做的,但Exchange隻是将發送的 <code>routing_key</code> 轉化為 <code>queue</code> 的名字,這樣發送就知道應該發給哪個queue;實際發送還是得 channel 來幹活,
即從 exchange 得到 routing_key ---> queue 的規則,然後再依據 routing_key 得到 queue。就知道 Consumer 和 Producer 需要依據哪個 queue 交換消息。
每個不同的 Transport 都有對應的 Channel;生産者将消息發送到Exchange,Exchange通過比對BindingKey和消息中的RouteKey來将消息路由到隊列,最後隊列将消息投遞給消費者。
Producers: 發送消息的抽象類,Producer 包含了很多東西,有 Exchange、routing_key 和 channel 等等;
Consumers:接受消息的抽象類,consumer需要聲明一個queue,并将queue與指定的exchange綁定,然後從queue裡面接收消息;
Consumer綁定了消息的處理函數,每一個Consumer初始化的時候都是和Channel綁定的,也就是說我們Consumer包含了Queue也就和Connection關聯起來了。
Consumer消費消息是通過Queue來消費,然後Queue又轉嫁給Channel,再轉給connection。
Hub是一個eventloop,Connection注冊到Hub,一個Connection對應一個Hub。Hub 把自己内部的 poller 配置在 Transport 之中。這樣就通過 transport 内部的 MultiChannelPoller 可以把 Hub . poller 和 Channel 對應的 socket 同poll聯系起來,一個 socket 在 linux 系統中就是一個file,就可以進行 poll 操作;
<code>MultiChannelPoller</code>是Connection 和 Hub的樞紐,它負責找出哪個 Channel 是可用的,但是這些 Channel 都是來自同一個 Connection。
具體如圖,可以看到,
目前是以Transport為中心,把Channel代表的真實redis與Hub其中的poll聯系起來,但是具體如何使用則尚未得知。
使用者是通過Connection來作為API入口,connection可以得到Transport。
我們下文用執行個體來介紹Kombu的啟動過程。
因為本文是一個綜述,是以大家會發現,一些概念講解文字會同時出現在後續文章和綜述之中。
celery 7 優秀開源項目kombu源碼分析之registry和entrypoint
IO 多路複用是什麼意思?
IO多路複用之select總結
Kombu消息架構
rabbitmq基本原理總結