繼 GPipe 之後,我們開一個流水線并行訓練新系列,介紹微軟的PipeDream。本文介紹其總體思路,架構和Profile階段。
目錄
[源碼解析] 深度學習流水線并行之PipeDream(1)--- Profile階段
0x00 摘要
0x01 概述
1.1 前文回顧
1.2 目前問題
1.2.1 資料并行
1.2.2 模型并行
1.2.3 Gpipe
0x02 論文
2.1 方案概述
2.1.1 并行方式
2.1.2 1F1B
0x03 流水線
3.1 流水線改進
3.2 挑戰
3.4 流水線劃分算法
3.5 Profile
0x04 Profile階段
4.1 思路
4.1.1 如何計算
4.1.2 Profile内容
4.2 代碼
4.2.1 訓練腳本
4.2.1.1 訓練過程
4.2.1.2 計算參數
4.2.1.3 建立圖
4.2.2 建立圖
4.2.2.1 設定wrapper
4.2.2.2 TensorWrapper
4.2.3 持久化
4.3 結果
0xFF 參考
Gpipe流水線其存在兩個問題:硬體使用率低,記憶體占用大。于是在另一篇流水并行的論文裡,微軟 PipeDream 針對這些問題提出了改進方法,就是1F1B (One Forward pass followed by One Backward pass)政策。這種改進政策可以解決緩存 activation 的份數問題,使得 activation 的緩存數量隻跟 stage 數相關,進而進一步節省顯存,可以訓練更大的模型。
PipeDream 可以分為4個階段:profile,compute partition,convert model,runtime等四個階段。
Profile階段:通過小批量資料的profile推理出DNN訓練時間。
Compute Partition階段:依據profile結果确定所有層的運作時間,然後進行優化,優化器傳回一個帶注釋的運算符圖,每個模型層映射到一個階段ID。
Convert model 階段:對運算符圖執行BFS周遊,為每個階段生成一個單獨的torch.nn.Module代碼。PipeDream對每個階段中的運算符進行排序,以確定它們保持與原始PyTorch模型圖的輸入輸出依賴關系的一緻性。
Runtime 階段:PipeDream運作時根據其1F1B-RR排程政策将每個階段(包括複制階段的副本)配置設定給單個工作程序。
本文首先看看 PipeDream 總體思路,架構和Profile階段。
前文提到,目前分布式模型訓練有幾個必要并行技術:
流水線并行,尤其是如何自動設定流水;
梯度累加(Gradient Accumulation);
後向重計算;
1F1B 政策;
在前面幾篇文章之中,我們介紹了Gpipe 如何前三種技術。本文開始,我們通過微軟分布式DNNs訓練系統PipeDream來看看其如何實作流水線并行和1F1B 政策。
DNN 訓練的特點是雙向訓練,訓練在前向和後向通道中疊代進行計算,兩種傳播以相反順序穿過相同層,在每輪疊代中,訓練過程循環處理輸入資料的一個 minibatch,并且更新模型參數。
最常見的 DNN 并行化訓練方法是資料并行化,這種方法把輸入資料分散到各個 workers中(每個worker擁有全部模型)運作。不幸的是,盡管在加速資料并行的性能優化方面取得了一些進展,但若要在雲基礎設施上訓練就會産生很大的通信開銷。而且,随着GPU 計算速度的飛快提升,所有模型訓練的耗時瓶頸會更進一步轉向通信環節。
下圖為資料并行,但是其對硬體使用率依然太低。因為資料并行化中的單個 worker 在交換梯度資料時不得不進行通信等待。
模型并行化是另一種并行化訓練形式,這種方法是把算子分散到各個 worker 上進行計算,這通常用于訓練大型 DNN 模型。本文中,模型并行指的就是把模型的不同layer放在不同的機器上,不涉及将同一個layer切分到不同機器上的場景。
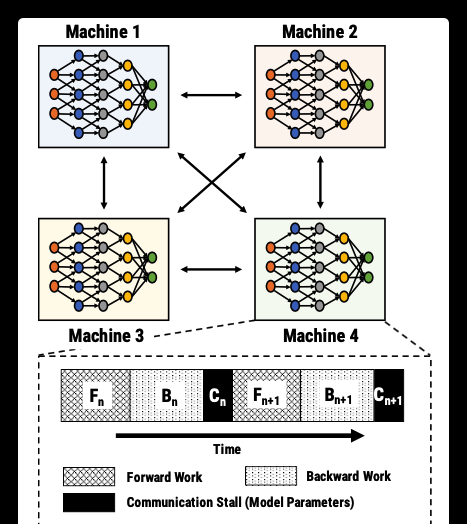
下圖是模型并行化,顯示了一個計算時間線,該示例有四台機器和一個管道。
在正向階段,每個階段對本階段中的層的minibatch執行正向傳遞,并将結果發送到下一階段。輸出級在完成前向傳遞後,計算minibatch的損失。
在後向階段,每個階段形成後向通道,逐一将損失傳播到前一階段。
worker 之間隻能同時處理一個 minibatch,系統中隻有一個minibatch是活動的,這極大限制了硬體使用率。
而且,模型并行化需要程式員決定怎樣按照給定的硬體資源來分割特定的模型,這其實無形之中加重了程式員的負擔。

除了通用問題之外,GPipe 流水并行政策還有一個記憶體問題:需要緩存多份activation。
假如一個batch被分為 n 個micro-batch,則需要緩存 n 份activation。這個 n 是梯度累加的次數,為了盡可能流水,通常這個累加次數都比較大,一般大于兩倍 stage 數目。那麼即使隻緩存少數 Tensor,這種政策依然需要較多顯存。
PipeDream 就針對這些問題提出了改進方法1F1B。PipeDream是第一個以自動化和通用的方式将流水線并行,模型并行和資料并行結合起來的系統。PipeDream首先使用模型并行對DNN進行劃分,并将每層的子集配置設定給每個worker。但是與傳統的模型并行不同,PipeDream對小批量資料進行流水線處理,實作了潛在的管道并行設計。在任何時刻,不同的worker處理不同的輸入,進而保證了流水線的滿負荷以及并行BSP。
微軟在論文 PipeDream: Fast and Efficient Pipeline Parallel DNN Training 之中對于PipeDream進行了詳細闡述,是以我們就基于此論文進行分析。
PipeDream 模型的基本機關是層,PipeDream将DNN的這些層劃分為多個階段。每個階段(stage)由模型中的一組連續層組成。
PipeDream的主要并行方式就是把模型的不同層放到不同的stage之上,不同的的stage部署在不同的機器上,順序地進行前向和反向計算,形成了一個pipeline。
每個階段對該階段中的所有層執行向前和向後傳遞。PipeDream将包含輸入層的階段稱為輸入階段,将包含輸出層的階段稱為輸出階段。但是每個stage可能有不同的replication,這就是資料并行。
對于使用資料并行的stage,采用 round-robin的方式将任務配置設定在各個裝置上,需要保證一個batch的資料在前向和後向發生在同一台機器上,
由于前向計算的 activation 需要等到對應的後向計算完成後才能釋放(無論有沒有使用 Checkpointing 技術),是以在流水并行下,如果想盡可能節省緩存 activation 的份數,就要盡量縮短每份 activation 儲存的時間,也就是讓每份 activation 都盡可能早的釋放,是以要讓每個 micro-batch 的資料盡可能早的完成後向計算,是以需要把後向計算的優先級提高,讓 micro-batch 标号小的後向比 micro-batch 标号大的前向先做。是以,如果我們讓最後一個 stage 在做完一次 micro-batch 的前向後,立馬就做本 micro-batch 的後向,那麼我們就能讓其他的 stage 盡可能早的開始後向計算,這就是 1F1B 政策。
1F1B(one-forward-one-backward)的排程模式會在每台worker機器上交替進行小批次資料的前向後向計算,同時確定這些小批量在"後向傳播"時可以路由到"前向傳播"的相同worker。
這種方案可以使得每個GPU上都會有一個batch的資料正在被處理,使所有worker保持忙碌,而不會出現管道暫停,整個pipeline是比較均衡的。同時能確定以固定周期執行每個stage上的參數更新,也有助于防止同時處理過多小批量并確定模型收斂。
PipeDream的pipeline parallelism(PP)是一種新的并行化政策,它将批内并行與批間并行結合起來。
我們首先看看流水線對于模型并行的改進。
在上節的示例中,如果隻有一個活動的minibatch,系統在任何給定的時間點最多有一個GPU處于活動狀态。
但是我們希望所有GPU都處于活動狀态。是以PipeDream 多個小批量逐一注入到流水線中,進而通過流水線來增強模型并行訓練。在完成小批量的前向傳遞時,每個階段都會異步地将輸出激活發送到下一階段,同時開始處理另一個小批量。類似地,在完成一個小批量的向後傳遞後,每個階段都會将梯度異步發送到前一階段,同時開始計算另一個小批量。
與普通層間并行訓練相比,流水線有兩個主要優點:
流水線通信量較少。流水線并行比資料并行的通信量要少得多。與資料并行方法(使用集體通信或參數伺服器)中的做法(把所有參數聚合梯度并且将結果發送給所有worker)不同,流水線并行中的每個worker隻需要在兩個 stage 邊界之間将梯度和輸出激活的一個子集發送給另一個worker,這可能導緻某些模型的通信量大幅減少。
流水線重疊了計算和通信。跨階段前向輸出激活和後向梯度的異步通信可以使得這些通信與後續小批量計算在時間上重疊,因為它們在不同的輸入上運作,計算和通信完全獨立,沒有依賴邊,是以可以更容易的并行化。在穩定理想狀态下,所有的 workers 時刻都在運轉,不像模型并行化訓練中會有停下來等待的時候。
下圖是實施了 1F1B 的流水線。Machine 1先計算 藍色 1,然後把藍色 1 發送給 Machine 2 繼續計算。Machine 1 接着計算 藍色 2。Machine 1 和 Machine 2 之間隻傳送模型的一個子集。計算和通訊可以并行。
PipeDream的目标是以最小化總體訓練時間的方式将流水線并行,模型并行性和資料并行性結合起來。然而,要使這種方法對大型DNN模型有效,獲得流水線并行化訓練的潛在收益,PipeDream 必須克服幾個主要挑戰:
如何高效劃分流水線。與處理器中的流水線一樣,需要将DNN高效正确地劃分為若幹“階段”(層序列),每個階段部署在不同的worker上執行。
模型特質和硬體拓撲會降低效率,劃分應該具體取決于模型體系結構和硬體部署。不好的劃分(階段性的工作量大範圍傾斜)可能會導緻worker長時間閑置。是以需要依據一定原則(通信和資源使用率)來劃分,比如:彼此有通信的層應該配置設定到相鄰的處理器;如果多個層操作同一資料結構,它們應該被配置設定到同一個處理器上,彼此獨立的層可以映射到不同處理器上。是以配置設定算法也必須考慮模型特質和硬體拓撲。
機器間的過度通信會降低硬體效率。
在確定訓練任務向前推進的同時,如何排程計算以最大化吞吐量。
如何防止流水線瓶頸。
由木桶原理我們可以知道,在穩定狀态下,一個流水線管道的吞吐量由這個流水線上最慢環節的吞吐量決定。如果各個環節的處理能力彼此差别很大,會導緻管道中出現空閑時間(一半稱之為bubble),這樣最快環節必須停下來等待其他環境,會造成饑餓現象,進而導緻資源利用不足。是以需要確定流水線中所有階段都大緻花費相同的計算時間,否則最慢的階段将會成為整個流水線的瓶頸。
如何在不同的輸入資料之間排程工作以均衡流水線。
與傳統的單向流水線管道不同,DNN訓練是雙向的:前向傳播和後向傳播,兩種傳播以相反順序穿過相同層。如何協調流水線工作是一個問題。
面對流水線帶來的異步性,如何確定訓練有效。
流水線帶來的一個問題就是weight版本衆多。在後向傳播時候如果使用比前向傳播時更高版本的weight來計算,則會造成訓練模型品質降低。
PipeDream管理後向通道裡的權重版本,通過為每個小批量的weight維護版本号來解決這個問題,這樣在後向通道裡使用的權重版本就和前向通道裡使用的相同,進而在數值上能夠正确計算梯度(我們後續文章會講解)。
PipeDream基于一個短期運作分析結果來自動劃分DNN的層,依據分析結果使用算法來對不同階段之間的計算負載進行平衡,同時最小化通信。PipeDream的自動劃分算法總體目标是輸出一個平衡的管道,確定每個階段大緻執行相同的總工作量。同時還必須確定各階段之間通信的資料量盡可能小,以避免通信中斷。算法如下:
将DNN層劃分為多個階段,以便每個階段以大緻相同的速率完成,即花費大緻相同的計算時間。
嘗試以拓撲感覺的方式盡量減少worker之間的通信(例如,如果可能,向更高帶寬的鍊路發送較大的輸出)。
因為DNN并不總可以在可用的workers做平均配置設定,為了進一步改進負載平衡,PipeDream允許複制一個stage,即在這個stage上使用多個worker進行資料并行。這樣多個worker可以配置設定到流水線同一階段,并行處理一個batch的不同的mini-batch,提高處理效率。因為資料并行采用了RR,是以這套政策也被稱為 1F1B-RR(one-forward-noe-backward-round-robin)。
這個劃分問題等價于最小化流水線的最慢階段所花費的時間,并且具有最優子問題屬性:在給定worker工作量前提下,吞吐量最大化的流水線由一系列子流水線構成,其中每一個子流水線針對較小worker工作量來最大化自己的輸出。是以,PipeDream使用動态規劃來尋找最優解。
具體如下圖:
DNN訓練有一個特點:不同輸入的計算時間幾乎沒有變化。于是 PipeDream充分利用了這一事實,給定一個具有N層和M台可用機器的DNN,PipeDream首先在一台機器上分析模型,記錄向前和向後過程所花費的計算時間,層輸出的大小以及每個層的相關參數的大小,最後輸出為一個結果檔案。
分區算法不但使用profile結果檔案作為輸入,而且還考慮了其他限制,如硬體拓撲和帶寬、勞工數量和計算裝置的記憶體容量,最終将層分為多個階段,同時還确定每個階段的複制因子,以最小化模型的總訓練時間。
是以總體算法大緻如下:
因為PipeDream借鑒了很多GPipe的思路,是以可以看到其比Gpipe的進步之處。
比如 Gpipe是通過在代碼中硬性預估ops來進行流水線負載均衡,PipeDream則是先做profile,根據實際情況再做推理。
Profile是PipeDream工作的第一個階段,是分區算法的基礎。PipeDream根據profiling的結果,使用動态規劃對模型進行劃分,将模型劃分為不同的stage,以及每個stage的replication數。
這是PipeDream針對GPipe的一個改進,兩者都是對每層的運作時間進行預估,然後對模型進行劃分。
GPipe是利用經驗值或者數學的方法來對運作時間進行預估。
PipeDream根據profiling的結果對運作時間進行預估。
因為有實際資料進行支撐,是以PipeDream更加準确和先進。
評測機制利用了這樣一個事實:DNN訓練在計算和通信時間上幾乎沒有變化。是以我們可以通過小批量資料的profile推理出DNN訓練時間。為了确定所有層的運作時間,PipeDream在其中一台機器上使用1000個小批量對DNN模型的短期(幾分鐘)運作進行 profile。
運作時間
對于每一層的運作時間,我們可以通過 運作時間 = 計算時間 + 通信時間 來得到。
計算時間就是每層layer前向和後向的計算時間,這個可以從profile得出。
通信時間就需要根據模型大小進行估算,PipeDream 估計通信所需的時間為"需要傳輸的資料量"除以"通信鍊路上的帶寬"。
通信時間
在流水線上,大多數通信都有三個步驟:
1)在發送端機器上,從GPU傳輸到CPU移動資料。
2)通過網絡從發送者到接收者發送資料。
3)在接收端,從CPU到GPU移動資料。
而 通過網絡從發送者到接收者發送資料 是最耗時的,是以PipeDream主要考慮這個因素。如果再對這個因素細分,則有:
對于從層 i 到 層 i + 1 傳輸激活值的時間,PipeDream 基于 "激活值"來估計。
假如配置成了資料并行(對于 層 i 使用 m 個 worker 做資料并行)的情況,做權重同步的時間使用"權重"來估計:
如果使用分布式參數伺服器,則權重數量被預估為 4 x ( m - 1 ) x | w i | / m。
如果使用 all_reduce,則每個worker給其他workers發送 ( m - 1 ) x | w i | / m 個 bytes,也接受到同樣數量位元組。
綜上所述,PipeDream在profile之中,為每個層 i 記錄三個數量:
Ti,層 i 的在GPU上向前和向後計算時間之和,即每層layer前向和後向的計算時間;
ai,層 i 的輸出激活的大小(以及向後過程中輸入梯度的大小)以位元組為機關,即每層layer的輸出的大小;
wi,層 i 的權重參數的大小(以位元組為機關),即每層layer參數的大小;
不同模型或者說不同領域有不同的profile檔案。
我們以 profiler/translation/train.py 為入口進行分析。
以下我們省略了無關代碼。
上節在訓練腳本制作的時候,torchsummary 的作用是計算網絡的計算參數等資訊,對于 torchsummary 我們舉例如下:
其列印如下:
create_graph 的作用就是使用torchgraph.GraphCreator建立一個圖,這個圖就可以了解為模型内部的DAG圖,每個節點記錄如下資訊。
具體代碼如下:
建立圖基本是在 GraphCreator 内完成。
hook_modules 的作用是給模型的forward函數設定一個wrapper,并且周遊為子子產品設定,這樣在模型運作時候可以跟蹤模型之間的聯系。
TensorWrapper 就實作了wrapper功能,graph_creator.summary 就是之前torchsummary.summary得到的網絡等資訊。可以看到此類會周遊 summary,計算 forward_compute_time 等資訊,最終建構了一個 node。
需要注意的是:activation_sizes 是根據 output_shape 來計算的。
對于某些内置方法,則也會相應處理,比如如下。
最終對應:
persist_graph 就是把profile結果輸出到檔案。
具體調用了 graph.py 的函數完成,這裡摘錄 to_dot函數如下:
我們使用源碼中的結果為例 pipedream-pipedream/profiler/translation/profiles/gnmt/graph.txt,給大家展示下具體結果。
至此,我們知道了Profile階段的内容,就是:運作訓練腳本,依據運作結果來計算參數,建立一個模型内部的DAG圖,然後把參數和DAG圖持久化到檔案之中,後續階段會使用這個檔案的内容。
下一篇我們分析如何計算自動分區。
https://www.microsoft.com/en-us/research/blog/pipedream-a-more-effective-way-to-train-deep-neural-networks-using-pipeline-parallelism/
lingvo架構走讀筆記
Tensorflow實作先累加多個minibatch計算的梯度,再反向傳播
用tensorflow2實作梯度累積
十倍模型計算時間僅增20%:OpenAI開源梯度替換插件
PipeDream: Fast and Efficient Pipeline Parallel DNN Training
論文解讀系列第五篇:微軟斯坦福等PipeDream快速訓練大規模神經網絡
https://cs231n.github.io/neural-networks-3/#gradcheck
https://www.cnblogs.com/geekfx/p/14182048.html
訓練時顯存優化技術——OP合并與gradient checkpoint
Pytorch筆記04-自定義torch.autograd.Function
PyTorch教程之Autograd
pytorch的自定義拓展之(三)——torch.autograd.Function的簡單定義與案例
pytorch的自定義拓展之(二)——torch.autograd.Function完成自定義層
PyTorch 源碼解讀之 torch.autograd:梯度計算詳解
再談反向傳播(Back Propagation)
CS231n課程筆記翻譯:反向傳播筆記
偏序集的最大反鍊【二分圖】
拓撲排序(Topological Sorting)