Redis 基礎資料類型重溫
有一天你突然收到一條線上告警:Redis 記憶體使用率 85%。你吓壞了趕緊先進行擴容然後再去分析 big key。等你進行完這一系列操作之後老闆叫你去複盤,期間你們聊到了業務的資料存儲在 Redis 中占用多大記憶體的問題。老闆按照序列化為 String 的方式來評估每個 key 對應的 value 大概多少位元組來計算總 key 數占用多大空間。你努力的回想了一下當年你面試的時候背誦的 ”真理“,總感覺哪裡不太對。于是你在夜深人靜的時候又打開了 ”Redis 面試寶典“。
為什麼 Redis 不直接存儲一個字元串進去非要自己封裝一個對象呢?
Redis 為使用者提供了多種類型的資料結構,對于使用者而言你無需關心資料結構内部是如何存儲,隻需要一條指令行即可。在 Redis 内部要實作這些不同指令行對應的功能遠遠不止這麼簡單,使用者越簡單,底層越複雜。需要根據不同的指令去處理不同的類型的操作,那麼這些類型資訊就是在 redisObject 對象中封裝。基于 redisObject 對象,底層可以進行類型檢查,對象配置設定、銷毀等操作。
redisObject 定義如下:
lru屬性: 記錄了對象最後一次被指令程式通路的時間
空轉時長:目前時間減去鍵的值對象的 lru 時間,就是該鍵的空轉時長。Object idle time 指令可以列印出給定鍵的空轉時長。如果伺服器打開了 maxmemory 選項,并且伺服器用于回收記憶體的算法為 volatile-lru 或者 allkeys-lru,那麼當伺服器占用的記憶體數超過了maxmemory 選項所設定的上限值時,空轉時長較高的那部分鍵會優先被伺服器釋放,進而回收記憶體。
type、encoding、ptr 是最重要的三個屬性。
type 記錄了對象所儲存的值的類型,它的值可能是以下常量中的一個:
encoding 記錄了對象所儲存的值的編碼,它的值可能是以下常量中的一個:
ptr 是一個指針,指向實際儲存值的資料結構,這個資料結構由 type 和 encoding 屬性決定。舉個例子, 如果一個 redisObject 的 type 屬性為<code>OBJ_LIST</code> , encoding 屬性為<code>OBJ_ENCODING_QUICKLIST</code> ,那麼這個對象就是一個Redis 清單(List),它的值儲存在一個 QuickList 的資料結構内,而 ptr 指針就指向 quicklist 的對象。
下圖展示了 redisObject 、Redis 所有資料類型、Redis 所有編碼方式以及底層資料結構之間的關系:
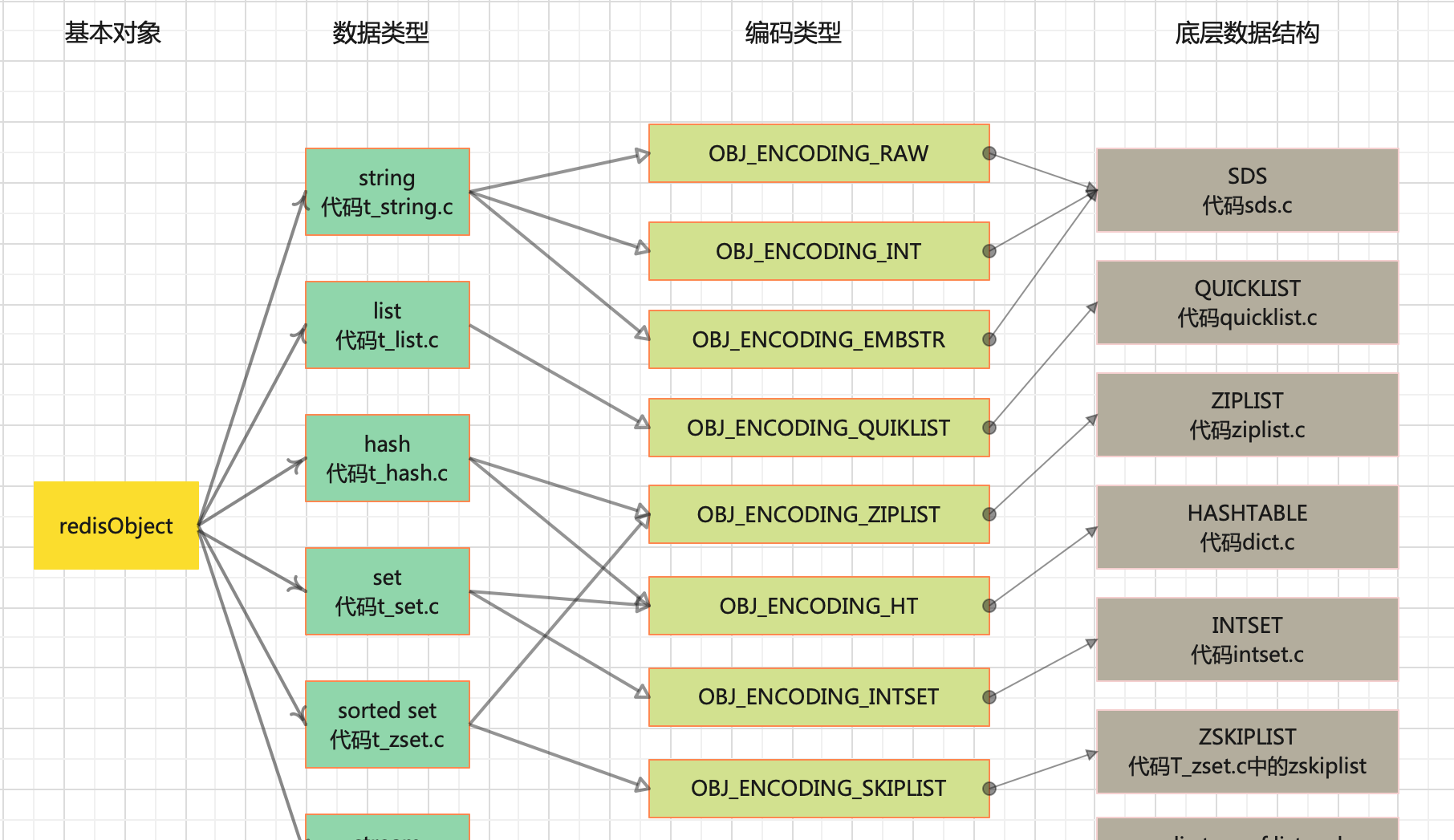
可能這樣說你看起來還是懵逼,那我們就把每一種資料類型都拿出來分析一下。
string 是 Redis 中最基本的資料類型,Redis 是用 C 開發的,但是 Redis 中的 string 和 C 中的 string 有很大的差別。
string 類型在 Redis 中有三種存儲方式:int、raw、embstr。即 這種 string 并不是字面意義上的 string。
當一個 key 的 value 是整型并且 value 長度不超過 20 個字元,Redis 就将其編碼為 int 類型。很顯然這樣做是為了節約記憶體。
Redis 預設會緩存 10000 個整型值(<code>#define OBJSHAREDINTEGERS 10000</code>),這就意味着,如果有 10 個不同的 key,value 都是 10000 以内的值,事實上全部都是共享同一個對象。
在 Redis 3.2 版本之前如果存儲的是一個字元串且長度大于 39 個位元組,就會使用 SDS 的格式來存儲,并且将 encoding 設定為 raw。如果存儲的是一個字元串但是長度小于等于 39 個位元組,則将 encoding 設定為 embstr 來存儲。
在 3.2 版本之後 39 被改為 44。
sds 的定義如下:
字段含義:
len 用于記錄 buf 中已經使用的空間長度;
free 用于記錄 buf 中還空餘的空間(初次配置設定空間一般沒有空餘,在對字元串修改的時候,會有剩餘空間出現);
buf 字元數組,用于記錄我們的字元串。
當你在 Redis 存儲一個 hello 時,它在 sds 中存儲的結構大概如下:

raw 格式和 embstr 格式的差別在于:
raw 編碼會調用兩次記憶體配置設定來分别建立 redisObject 結構和 sdshdr 結構,而 embstr 編碼則通過一次記憶體配置設定函數來獲得一塊連續的空間,空間中依次包含 redisObject 和 sdshdr 結構。
同樣對于記憶體釋放來說,embstr 隻需要一次,而 sdshdr 需要兩次。
另外,因為 embstr 編碼格式的字元串對象所有資料都是儲存在一塊連續的記憶體塊中,那麼對于查找操作來說可以将整塊資料放入緩存中,更有利于讀取。
SDS 和 C 字元串的差別
字元串長度計算
C 語言中的字元串使用長度為 n+1 的字元串數組來表達長度為 n 的字元串,擷取字元串長度需要周遊整個數組。而 SDS 使用獨立的 len 字段來記錄長度。
C 緩沖區溢出
有兩個在記憶體中緊鄰的字元串”hello“ 和 ”world“,現在要把 ”hello“ 改為 ”helloo“,但是忘記重新為 ”helloo“ 配置設定新的記憶體空間,那麼在 C 中會把 ”helloo“ 的位置往後溢出到後面的記憶體空間,即 ”world“ 的位置會被擠占。這兩個單詞就變為:"hellooorld"。
使用 SDS 則不用擔心這種問題。Redis 會在執行修改操作之前先檢查配置設定給 SDS 的空間是否夠用,如果不夠會先拓展空間再執行修改操作。
另外 SDS 還提供兩個實用功能:空間預配置設定 和 惰性釋放空間。
預配置設定政策:
如果修改後的 SDS 長度 < 1MB,預配置設定同樣 len 大小的空間;
如果修改後的 SDS 長度 > 1MB,預配置設定1MB 大小的空間。
惰性空間釋放
縮短 SDS 空間時并不立即進行記憶體空間釋放,而是記錄 free 位元組數。下次修改資料如果需要重新配置設定空間時優先取這一部分位元組而不是重新配置設定。
hash 類型的底層存儲分别有兩種方式:ziplist 和 hashtable。
hashtable 實作方式我們就不細說大家都懂,基于 hash 值來實作,Redis 解決 hash 沖突使用鍊位址法。與 Java 中的 HashMap 不同的是,在鍊位址法解決沖突的過程中,對于一個沖突的 key 總是會添加到目前連結清單的表頭而不是表尾,這樣添加節點的時間複雜度就為 o(1)。
hash 的存儲邏輯我們就不說,詳細說一下 rehash 的過程,這個實作比較有意思。
Redis 的 字典結構體 dict 中存放了兩張 hash 表:
正常使用的就是 ht[0],ht[1] 是隻有在擴容/縮容 的時候才會用到。hash 都是有負載因子的,這裡也不例外:
load factor = ht[0].used / ht[0].size
觸發 rehash 有兩種情況,一種是觸發擴容,一種是觸發縮容。
觸發擴容的條件包括:
伺服器目前沒有在執行 BGSAVE 指令或者 BGREWRITEAOF 指令,并且 load factor >= 1;
伺服器目前正在執行 BGSAVE 指令或者 BGREWRITEAOF 指令,并且 load factor >= 5;
觸發縮容的條件:
負載因子 < 0.1 時((ht[0].used / ht[0].siz) < 0.1)。
再說很好玩的一點:漸進式 rehash。這個在 Java 的 HashMap 中是沒有的。
所謂漸進式 rehash 即 rehash 不是一次性、集中式的完成,而是分多次、漸進式的進行。
這樣做的原因在于如果 hash 表裡的 KV 對很大時,比如上百萬的情況如果一次性将這些資料全部從 ht[0] 移到 ht[1] 所需的龐大計算量可能會導緻 Redis 在一段時間内停止服務。為了避免這種情況是以 Redis 采取了漸進式 rehash。
漸進式 rehash 期間,Redis 會逐漸的将 ht[0] 的資料轉移到 ht[1] ,查找/删除/更新 操作會先查 ht[0], 查不到會再查 ht[1],新增操作隻會在 ht[1] 上執行。
說完 hashtable 存儲我們再來說另一種存儲方式:zipList。翻譯過來是壓縮清單,但是并不是我們了解表意上面的那種壓縮。
zipList 是 list 鍵、 hash 鍵以及 zset 鍵的底層實作之一(3.0 之後 list 鍵已經不直接使用 zipList 和 linkedList 作為底層實作,取而代之的是 quickList)。
Redis 官方文檔表示: zipList 是一個經過特殊編碼的雙向連結清單,這種雙向連結清單與普通的雙向連結清單的差別在于:它不存儲上個節點和下個節點的指針,而是上個節點的長度和目前節點的長度。它的設計目标就是為了提高存儲效率,zipList 适用于字段少和字段值少的場景。可用于存儲字元串或整數,整數是按照二進制表示進行編碼,而不是編碼成字元串。
另外普通的連結清單中的每一項可能都不在一塊連續的記憶體空間中,通過指針來表示資料引用。而 zipList 為了減少記憶體碎片率和提高查詢效率,一個 zipList 對象将獨自占用一塊完整的獨立記憶體空間。
下圖展示了 zipList 的構成:
zlbytes:32 bit,表示 zipList 占用的位元組總數(也包括 zlbytes 本身占用的 4 個位元組)。
zltail: 32 bit,表示 zipList 表中最後一項(entry)在 zipList 中的偏移位元組數。zltail 的存在使得我們可以很友善地找到最後一項(不用周遊整個zipList ),進而可以在 zipList 尾端快速地執行 push 或 pop 操作。
zllen: 16 bit, 表示 zipList 中資料項(entry)的個數。zllen 字段因為隻有 16 bit,是以可以表達的最大值為 2^16-1。這裡需要特别注意的是,如果 zipList 中資料項個數超過了 16bit 能表達的最大值,zipList 仍然可以來表示。那怎麼表示呢?這裡做了這樣的規定:如果 zllen 小于等于 216-2(也就是不等于216-1),那麼 zllen 就表示 zipList 中資料項的個數;否則,也就是 zllen 等于 16bit 全為 1 的情況,那麼 zllen 就不表示資料項個數了,這時候要想知道 zipList 中資料項總數,那麼必須對 zipList 從頭到尾周遊各個資料項才能計數出來。
entry:表示真正存放資料的資料項,長度不定。一個資料項(entry)也有它自己的内部結構。具體結構我們下面畫圖解釋。
zlend:zipList 最後 1 個位元組,是一個結束标記,值固定等于 255。
再說 zipList entry 的結構:
pre_entry_length:根據編碼方式的不同, pre_entry_length 可能占用 1 位元組或者 5 位元組:
1 位元組:如果前一節點的長度小于 254 位元組,便使用一個位元組儲存它的值。
5 位元組:如果前一節點的長度大于等于 254 位元組,那麼将第 1 個位元組的值設為 254 ,然後用接下來的 4 個位元組儲存實際長度。
encoding 和 length
encoding 和 length 兩部分一起決定了 content 部分所儲存的資料的類型(以及長度)。其中, encoding 的長度為 2 bit , 它的值可以是 00 、 01 、 10 和 11 :
00 、 01 和 10 表示 content 部分儲存着字元數組。
11 表示 content 部分儲存着整數。
content 部分儲存着節點的内容,類型和長度由 encoding 和 length 決定。
壓縮清單的本質還是一個位元組數組,操作時按照既定規則将字元寫入 entry 中。既然底層是一塊連續的記憶體塊那麼大小肯定是有限制的, hash 結構何時使用 hashtable ,何時使用 zipList 來進行存儲呢?
當我們為某個 key 第一次執行 <code>hset key field value</code> 的時候,Redis 會建立一個 hash 結構,這個新建立的 hash 結構的底層就是 zipList 結構來存儲的。
随着資料插入的越多,達到 Redis 配置的預設值:
當 hash 中的資料項(即field-value對)的數目超過 512 的時候,也就是 zipList 資料項超過 1024 的時候(請參考 t_hash.c 中的 hashTypeSet 函數)。
當 hash 中插入的任意一個 value 的長度超過了 64 的時候(請參考 t_hash.c 中的 hashTypeTryConversion函數)。
之是以有這兩個條件限制,是因為 zipList 變大後會有幾個缺點:
每次插入或修改引發的 realloc 操作會有更大的機率造成記憶體拷貝,進而降低性能。
一旦發生記憶體拷貝,記憶體拷貝的成本也相應增加,因為要拷貝更大的一塊資料,類似 COW 的複制機制。
當 zipList 資料項過多的時候,在它上面查找指定的資料項就會性能變得很低,需要周遊整個連結清單。
List 結構在 3.2 版本之前是使用 zipList 和 linkedList 來實作的, 之後引入的新的資料結構 quickList。這裡我們來看一下 linkedList 和 quickList 的結構是什麼樣的。
linkedList 是一個雙向連結清單,他和普通的連結清單一樣都是由指向前後節點的指針。插入、修改、更新的時間複雜度尾 O(1),但是查詢的時間複雜度确實 O(n)。
linkedList 和 quickList 的底層實作是采用連結清單進行實作,在 C 語言中并沒有内置的連結清單這種資料結構,Redis 實作了自己的連結清單結構。linkList 維護了一個 length 字段來儲存連結清單長度,是以查詢長度時間複雜度為o(1)。
之是以 zipList 和 linkedList 會被取代,是因為這兩種資料結構都有各自的缺點:
zipList 因為使用的是一塊連續的記憶體塊,存儲和讀取效率高,但是不利于修改删除這種需要頻繁的申請和釋放記憶體的操作,并且當 zipList 長度很長的時候, 一次 realloc 可能會耗費很長時間。
linkedList 勝在插入資料時間複雜度低,但是每個節點需要維護兩個指針增加了開銷,各個節點又是單獨的記憶體塊,位址不一定連續,這就會導緻回收的時候記憶體碎片率增高。
為了解決這兩個資料結構天然帶來的影響,開發者研究出 quickList 結構,quickList 也不是什麼銀彈神奇,概略來說它就是 zipList 和 linkedList 兩者的結合體。quickList 的定義如下:
從結構體不難看出,quickList 的外層就是一個 linkedList ,隻不過 linkedList 裡面放的不是 source data,而是 zipList。是以 quickList 不能算作是偉大的發明,稱為在偉大發明肩上做了一點微小的工作比較合适(事實上也不算微小)。
了解了 quickList 是什麼之後我們應該會有一些問題:既然底層還是 zipList,那怎麼解決 zipList 過長的問題呢?
如果每個 zipList 上的資料越少,那麼整個 quickList 上的節點就越多,記憶體碎片率就越高;反之如果隻有一個 zipList 那跟直接使用 zipList 也沒什麼差別。是以 quickList 還是做了一些細節處理的。
Redis 提供了一個配置參數 <code>list-max-ziplist-size</code>,使用者可以來根據自己的情況進行調整。
這個參數可以取正值,也可以取負值。當取正數時,表示按照你配置的個數來限制每個 zipList 的長度。比如配置了 <code>list-max-ziplist-size=5</code> 即表示 zipList 最多包含 5 個元素。
當取負數時,表示按照占用位元組數來限制每個 zipList 的長度。Redis 配置隻能從 -1 - -5 這幾個數中選擇:
-5: 每個 quickList 節點上的 zipList 大小不能超過 64 Kb。
-4: 每個 quickList 節點上的 zipList 大小不能超過 32 Kb。
-3: 每個 quickList 節點上的 zipList 大小不能超過 16 Kb。
-2: 每個 quickList 節點上的 zipList 大小不能超過 8 Kb。(-2是Redis給出的預設值)
-1: 每個 quickList 節點上的 zipList 大小不能超過 4 Kb。
使用 List 結構來存儲資料大機率也是兩邊的資料被先通路的機率大一些 ,中間的資料被通路的頻率很低。如果你的應用場景符合這個特點,List 還提供一個選項:即把中間的資料進行壓縮以節省空間。Redis 的配置參數 <code>list-compress-depth</code> 就是用來完成這個設定。
這個參數表示一個 quickList 兩端不被壓縮的節點個數。注:這裡的節點個數是指 quickList 雙向連結清單的節點個數,而不是指 zipList 裡面的資料項個數。實際上一個 quickList 節點上的 zipList 如果被壓縮就是整體被壓縮。
參數 <code>list-compress-depth</code> 的取值含義如下:
0: 是個特殊值,表示都不壓縮。這是 Redis 的預設值。
1: 表示 quickList 兩端各有 1 個節點不壓縮,中間的節點壓縮。
2: 表示 quickList 兩端各有 2 個節點不壓縮,中間的節點壓縮。
3: 表示 quickList 兩端各有 3 個節點不壓縮,中間的節點壓縮。
依此類推…
由于 0 是個特殊值,很容易看出 quickList 的頭節點和尾節點總是不被壓縮的,以便于在表的兩端進行快速存取。
List 清單不會管你存入的資料是否是重複的,來了即入隊。Set 是不可重複的集合,底層使用兩種存儲結構來支援:一種是 hashtable,一種是 inset。
hashtable 我們上面已經說過,key 為 set 元素的值, value 為 null。inset 是一種新的資料結構,可以了解為數組。使用 inset 資料結構需要滿足兩個條件:
元素個數不少于預設值 512;
元素可以用整型來表示。
簡單說:Set 集合如果存儲的是非整型資料或者是整型資料且元素個數少于 512 個時底層會用 hashtable 結構來存儲;否則就用 inset 結構來存儲。
inset 結構是由整數組成的集合,實際上是有序集合,進而便于使用二分查找法更快的搜尋。它在記憶體配置設定上同 zipList 一樣,也是使用一塊連續的記憶體空間,但是它做的更好的是:對于大整數和小整數(按照絕對值)采取了不同的編碼以節省空間。
inset 的定義如下:
encoding 表示資料編碼方式。它有三種可取的值:
<code>INTSET_ENC_INT16</code> 表示每個元素用 2 個位元組存儲;
<code>INTSET_ENC_INT32</code> 表示每個元素用 4 個位元組存儲
<code>INTSET_ENC_INT64</code> 表示每個元素用 8 個位元組存儲。
是以,intset 中存儲的整數最多隻能占用 64 bit。
length 表示 inset 中元素的個數。它和encoding 一起構成了 inset 的頭部。contents 數組是實際存儲資料的地方,
contents 總長度(byte) = ( encoding * length)/ 8
contents 裡面的元素有兩個特性:
元素不重複;
元素在數組中由小到大排列。
正因為此特性,是以在查找元素的時候可以采用二分查找法,查詢的時間複雜度為 o(lgN)。
需要注意的是: encoding 是對整個 inset 結構體生效,是以意味着 contents 裡面所有的資料都采用同一種編碼。如果一開始你存儲的資料比較小使用的是 int16 類型的編碼方式,後面存儲了一個大資料之後需要更新為 int64 類型,contents 裡面所有的資料都将使用這一類型編碼。是否更新使用新的編碼格式取決于數組中最長的元素。
ZSet 是有序集合,底層是基于 zipList 和 SkipList 來實作的。zipList 我們已經說過,這裡來說一下 SkipList。
SkipList 我們在準備面試的時候多多少少都會去準備一下,是以大家應該也不陌生。以下是個典型的跳躍表例子(圖檔來自維基百科):
從圖中可以看到, 跳躍表主要由以下部分構成:
表頭(head):負責維護跳躍表的節點指針。
跳躍表節點:儲存着元素值,以及多個層。
層:儲存着指向其他元素的指針。高層的指針越過的元素數量大于等于低層的指針,為了提高查找的效率,程式總是從高層先開始通路,然後随着元素值範圍的縮小,慢慢降低層次。
表尾:全部由 <code>NULL</code> 組成,表示跳躍表的末尾。
SkipList 設計之初是作為替換平衡樹的一種選擇。AVL樹有着嚴格的 o(lgN)的查詢效率,但是對于插入操作可能需要多次旋轉導緻效率變低是以又研發了紅黑樹結構。但是紅黑樹有個問題就是在并發更新環境下效率變低,左右旋自平衡的過程中需要鎖住較多節點。
跳表的實作也比較簡單,就是在普通的單向連結清單基礎上增加了一些分層的索引。算法大家可以自行搜尋,這裡就不詳細介紹。Redis 的跳表與普通跳表有一些差別,除了有 value 之外,還有一個 score 的屬性。score 對 value 做排序輔助用。我們主要關注 Redis 對跳表做的更改:
允許重複的 <code>score</code> 值:多個不同的 <code>member</code> 的 <code>score</code> 值可以相同。
進行對比操作時,不僅要檢查 <code>score</code> 值,還要檢查 <code>member</code> :當 <code>score</code> 值可以重複時,單靠 <code>score</code> 值無法判斷一個元素的身份,是以需要連 <code>member</code> 域都一并檢查才行。
每個節點都帶有一個高度為 1 層的後退指針,用于從表尾方向向表頭方向疊代:當執行 ZREVRANGE 或 ZREVRANGEBYSCORE 這類以逆序處理有序集的指令時,就會用到這個屬性。
ZSet 底層使用 zipList 和 SkipList 分别在不同的情況下:
[value,score] 鍵值對數少于 128 個且每個元素長度小于 64 位元組的時候使用 zipList 存儲。當不滿足前面的條件時則使用 SkipList 來存儲 value,key 和 score 則使用 hashtable 來存儲。
目前常用的 key-value 資料結構有三種:Hash 表、紅黑樹、SkipList,它們各自有着不同的優缺點:
Hash 表:插入、查找最快,為 O(1);如使用連結清單實作則可實作無鎖;資料有序化需要顯式的排序操作
紅黑樹:插入、查找為 O(logn),但常數項較小;無鎖實作的複雜性很高,一般需要加鎖;資料天然有序。
SkipList:插入、查找為 O(logn),但常數項比紅黑樹要大;底層結構為連結清單,可無鎖實作;資料天然有序。
ZSet 之是以選用 SkipList 而不是紅黑樹,是因為對于 ZRANGE 或者 ZREVRANGE 這樣的範圍查找操作,跳表底層的雙向連結清單十分便捷,如果使用紅黑樹結構在找到指定範圍的小值之後,還需要中序周遊查找其他不超過大值得節點。并且對于插入删除來說,跳表隻用更改底層連結清單的指針即可,而紅黑樹可能需要調整子樹層高。
我們看一下 SkipList 的結構:
如果一個連結清單有 n 個結點,如果每兩個結點抽取出一個結點建立索引的話,那麼第一級索引的結點數大約就是 n/2,第二級索引的結點數大約為 n/4,以此類推第 m 級索引的節點數大約為 n/(2^m)。
假如一共有 m 級索引,第 m 級的結點數為兩個,通過上邊我們找到的規律,那麼求得 n / ( 2^m ) = 2,進而求出 m=log(n) - 1。如果加上原始連結清單,那麼整個跳表的高度就是 log(n) 。
我們在查詢跳表的時候,如果每一層都需要周遊 k 個結點,那麼最終的時間複雜度就為 O(k * log(n))。那這個 k 值為多少呢,按照我們每兩個結點提取一個基點建立索引的情況,我們每一級最多需要周遊兩個節點,是以 k=2。那跳表查詢資料的時間複雜度就是 o(2 * log(n)),常數 2 忽略不計,就是 o(log(n))了。
如果嚴格按照這種兩下兩層連結清單上節點個數 2:1 的對應關系進行維護索引,對于插入或者删除資料的時候很有可能會将索引調整的複雜度升到o(n),Redis 為了避免這一問題,它不要求上下兩層索引之間節點個數有嚴格的對應關系,而是為每層節點随機出一個層數,這個随機過程并不是一個服從均勻分布的随機數,計算過程如下:
每個節點都有一個指向第一層的指針(所有資料都在第一層);
如果一個節點有第 i 層(i >=1)指針,即節點已經在第一層到第i層連結清單中,那麼它有第i+1層指針的機率為P;
節點最大層數不允許超過一個最大值,記為 MaxLevel。
以上過程的僞碼如下:
在 Redis 中上面兩個參數 p 和 MaxLevel 的取值是固定的:
p = 1/4
MaxLevel = 32 (5.0版本以後是64)
根據這個算法,一個新增的節點有 50% 的機率在level[1],25%的機率在level[2],12.5%的機率在level[3],以此類推,有 2^63 個元素的情況下會有 31 層,且每一層向上晉升的機率都是50%。
以上介紹了 Redis 的 5 種基本類型資料結構:string、list、hash、set、zset,詳細讨論了這些資料結構底層的實作邏輯,可以看到 Redis 在節約記憶體方面做了很多的努力,不僅僅是新存儲結構的開發還包括多少資料量用什麼資料結構的探讨。
除了 5 種基本類型資料結構外,還有 3 種進階資料結構:HyperLogLog、Geo、BloomFilter。限于篇幅,我們下一篇接着探讨。