1.引言
我經常會看到有人在知乎上提問如何入門 Python 爬蟲?如何學習Python爬蟲[入門篇]?等這一些問題,我今天寫這篇文章的目的就是來告訴大家,我為什麼要學爬蟲,爬蟲的本質是什麼。
2.我為什麼要學爬蟲
先說我吧,我當初為什麼要學爬蟲呢?
兩年前,我還是個懵懂的小孩,那時候,基本上每天晚上都會上老司機論壇找電影,不知道大家知不知道老司機論壇,其實可以按照分類查找你想要看的電影的,但是它竟然沒有多選(不能同時選擇兩個或多個分類進行查找)。比如 我想看“xxx”劇情+中文字幕的,我是怎麼做的呢,先選擇分類“xxx”,然後一頁一頁的ctrl+f 輸入“中文” 查找......這樣找了幾天後,我發現這種方法簡直太傻了,而是我百度了下,第一次知道了“爬蟲”...于是,在強大的興趣驅動下,我1個禮拜就入了門....這就是我為什麼要學爬蟲的經過
我覺得爬蟲就是幫助我們偷懶的,如上面,當我爬下來整個老司機論壇後,我可以自定義多條件查找了,不用再那麼傻傻的一頁一頁的翻了;爬蟲能幫我們省掉一系列繁瑣的時間(比如我要下載下傳我愛看圖這個網站的圖檔,我不可能一張一張的點,我可以寫一個爬蟲幫我全部下載下傳完)
3.爬蟲的本質是什麼
爬蟲的本質我覺得就是一句話 模仿浏覽器去打開網頁
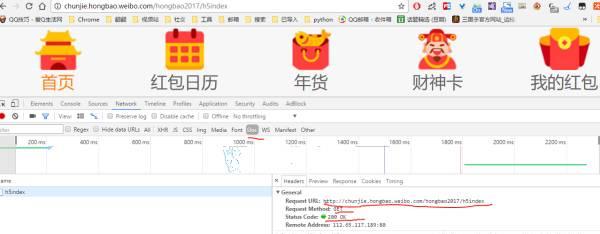
我們來看一個例子吧(讓紅包飛)
打開這個網頁後,按F12,打開開發者工具,然後F5重新整理下頁面(我用的Google浏覽器)
先點選“最上面的Network”然後點選“Doc”,應該會看到如下圖一樣的界面
我們先看General 下面的
request url ,表示我們打開這個網頁的位址,也就是我們上面的位址
request method ,表示我們請求的方式,這裡我們看到用的是GET
status code 表示伺服器傳回的狀态嗎,這裡是200,表示OK
Cache-Control 是用來控制網頁的緩存,詳細可以Cache-control_百度百科
Cookie,有時也用其複數形式 Cookies,指某些網站為了辨識使用者身份、進行 session 跟蹤而儲存在使用者本地終端上的資料(通常經過加密)。定義于 RFC2109 和 2965 中的都已廢棄,最新取代的規範是 RFC6265[1] 。(可以叫做浏覽器緩存)
HOST 表示你請求網址的請求域
User-Agent 表示目前浏覽器的名稱及版本
Referer: 告訴伺服器你是從哪個頁面連結過來的(下圖沒有.)

原文釋出時間為:2017-02-15
本文作者:高金