hadoop 是什麼?
1. 适合海量資料的分布式存儲與計算平台。
海量: 是指 1T 以上資料。
分布式: 任務配置設定到多态虛拟機上進行計算。
2. 多個任務是怎麼被配置設定到多個虛拟機當中的?
配置設定是需要網絡通訊的。而且是需要啟動資源 或者 消耗一些硬體上的配置。
單 JVM 關注的如何『處理』,而不是交給其他人進行處理這個 『管理』的過程。 是以最開始有兩個關鍵的字 『适合』,
隻有當資料量超過 1T 的大資料處理才能凸顯 hadoop 的優勢; 當然,用 hadoop 處理 幾十G、幾百G 這種小資料也是可以的,隻是展現不了 hadoop的優勢罷了,從硬體的角度,從效率的角度都是不太值得的。
3.Hadoop Ecosystem Map Hadoop生态系統圖
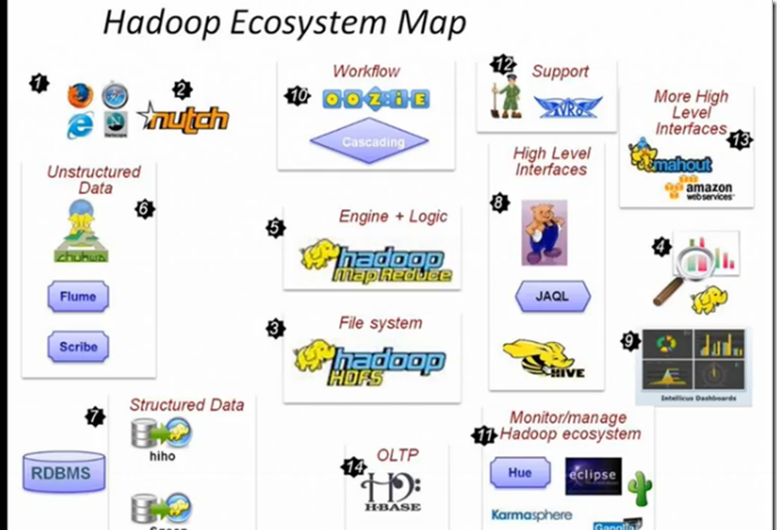
像其他架構一樣,hadoop 也是分層的, 序号③ ⑤ 就是 hadoop 中重要的組成, HDFS 負責資料存儲。MapReduce 是海量資料的分布式計算架構。
Structured Data(hiho, sqoop) 是 hadoop 中對傳統資料和 hadoop中資料互相轉化的工具。傳統資料庫中的資料可以導入到 hadoop中。hadoop中的資料也可以導入到傳統的關系型資料庫中。
HBASE 是 hadoop中用的最多和最重要的子項目之一。當然它也是建構于 MapReduce 和 HDFS 之上的。不過 HBASE 可以不基于 HDFS ,隻是如果不基于 HDFS時就無法使用 MapReduce 計算架構了。是處理大資料讀寫操作的,尤其适合一些大型線上系統。
大資料有兩層含義:第一層含義,大資料有自己的構造形态,key-value方式。 另外一層含義,就是大家了解的海量資料。 之是以能成為 大資料 是因為 他是 key-value的建構方式。
HDFS
HDFS: Hadoop Distributed File System 分布式檔案系統
檔案系統 是一套接口,一套平台。是用于管理檔案的存儲與操作的。
HDFS檔案系統,是用于管理分布式檔案的存儲與操作的。HDFS 就為我們提供了一套機制,讓海量資料能夠分布在不同的計算機上。他提供 言外知音就是 我們不用關心資料是怎麼存儲的, HDFS 負責存儲這件事情。這是我們使用 hadoop 的一個重要的原因,他幫我們屏蔽掉一些分布式操作的一些細節。
MapReduce
MapReduce : 并行計算架構
分布式系統中有很多台機器,每一台機器存儲資料的一部分,我們使用 hadoop 之是以能夠很快的計算得出結果,原因很簡單 我們計算的代碼會在不同的機器上運作, 每一台機器完成計算的一部分,因為每台機器上存儲的隻是我資料的一部分。多台機器并行計算。然後把計算結果收集過來得出最終的結果。這是Hadoop 之是以塊的根源。是以 MapReduce 是我們要研究非常重要的核心, HDFS 的操作是hadoop 架構屏蔽掉的,是以我們主要是去學習怎麼去使用它。作為開發而言,聚焦到核心的核心,肯定是 MapReduce。 因為 MapReduce 是計算架構。也就是說資料已經存儲了,我怎麼計算它,這在任何一個架構中都是一個比較核心的問題。當然也是最有技術含量的問題。是以 如果學習hadoop 的話,有必要詳細研究 MapReduce 的架構、使用、源代碼等等所有的核心環節。
開始做,堅持做,重複做
![Java String.format方法的簡單使用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)