微軟認知服務包括了影像、語音、語言、搜尋、知識五大領域,通過對這些認知服務的獨立或者組合使用,可以解決很多現實世界中的問題。作為AI小白,我們可以選擇艱難地攀登崇山峻嶺,也可以選擇像牛頓一樣站在巨人的肩膀上。本章節的内容就以"漫畫翻譯"為例,介紹如何靈活使用微軟認知服務來實作自己的AI夢想。
日本漫畫非常著名,如海賊王,神探柯南等系列漫畫在中國的少年一代中是非常普及。國内專門有一批志願者,全手工翻譯這些漫畫為中文版本,過程艱辛複雜,花費時間很長。能否使用AI來幫助加快這個過程呢?
小提示:漫畫是有版權的,請大家要在尊重版權的前提下做合法的事。
漫畫翻譯,要做的事情有三步:
調用微軟認知服務,用OCR(光學字元識别)服務識别出漫畫上所有文字;
調用微軟認知服務,用Text Translate(文本翻譯)服務把日文翻譯成中文;
自己寫邏輯代碼把中文文字貼回到以前的漫畫中,覆寫以前的日文,生成新的漫畫幀。
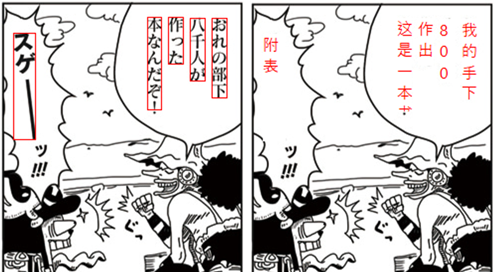
下圖是展示最後的翻譯效果,左側是原漫畫,右側是翻譯成中文的結果:
安裝Windows 10版本 1803,低一些的Windows 10版本也可以使用。Windows 7也可以運作本示例程式,但不建議使用,Windows 7的官方技術支援到2020/01/14結束。
小提示:如果您的機器不能運作Windows 10,說明硬體性能還是有些不夠的。AI是建立在軟硬體快速發展的基礎上的,不建議您使用低配置的機器來做AI知識的學習。
安裝Visual Studio 2017 Community。點選這裡下載下傳,對于本案例,安裝時選擇".NET桌面開發"即可滿足要求。
點選進入此頁面:

在上圖所示頁面中"計算機影像"下點選"免費試用":
根據自己的實際情況選擇以上三個選項之一,這裡以選擇第一個"來賓"選項為例:
選擇一個熱愛的國家/地區,在上下兩個複選框上("我同意","我接受")都打勾,點選"下一步":
上圖中以選擇"Microsoft"賬戶為例繼續:
最後得到了上面這個頁面,這裡的密鑰(Key)和終結點(Endpoint)要在程式中使用,請儲存好!
小提示:上面例子中的密鑰隻能再使用1天了,因為是7天的免費試用版本。是以當你的程式以前運作正常,某一天忽然從伺服器不能得到正常的傳回值時并且得到錯誤代碼Unauthorized (401),請首先檢查密鑰狀态。
小提示:當試用的Key過期後,你是無法再申請試用Key的,隻能申請正式的Key,這就要通過Azure門戶。在Azure門戶中申請好Computer Vision服務(包括OCR服務)的Key後,它會告訴你Endpoint是…../vision/v1.0,這個不用管它,在code裡還保持……/vision/v2.0就可以了,兩者的Key是通用的。
用自己的Azure賬号登入Azure門戶:
在上圖中點選左側的"All resources":
在上圖中點選上方的 "+ Add"圖示來建立資源,得到資源清單如下 :
在上圖中點選右側清單中的"AI + Machine Learning",得到下圖的具體服務項目清單:
這裡有個坑,文本翻譯不在右側的清單中,需要點選右上方的"See all"來展開所有項目:
哦,好吧,還是沒有!保持耐心,繼續點選Cognitive Services欄目的右側的"More"按鈕,得到更詳細的清單:
還是沒有?卷滾一下看看?到底,到底!OK,終于有了Translator Text,就是Ta:
建立這個服務時,我們選擇F0就可以了。如果要是做商用軟體的話,你可以選擇S1或其他,100萬個字元才花10美元,不貴不貴!
是不是以上申請Key的過程太複雜了?那是因為Azure内容龐雜,網頁設計層次太多!其實這個過程是可以簡化的,因為我們有個Visual Studio Tools for AI擴充包!
打開VS2017,菜單上選擇"工具(Tools)->擴充和更新(Extensions and Updates)",在彈出的對話框左側選擇"聯機(Online)",在右側上方輸入"AI" 進行搜尋,會看到"Microsoft Visual Studio Tools for AI"擴充包,下載下傳完畢後關閉VS,這個擴充包就會自動安裝。
安裝完畢後,再次打開VS2017,點選菜單View->Server Explorer。如果安裝了Tools for AI,此時會看到以下界面:
在AI Tools->Azure Cognitive Services下,可以看到我已經申請了2個service,ComputerVisionAPI和TranslateAPI就是我們想要的,這兩個名字是自己在申請服務時指定的。
假設你還沒有這兩個服務,那麼在Azure Cognitive Services上滑鼠右鍵,然後選擇Create New Cognitive Service,出現以下對話框:
在每個下拉框中顯示的内容可能會每個人都不一樣,絕大多數是用下拉框完成填充的,很友善。假設我想申請TextTranslation服務,那麼我在Service Name上填寫一個自己能看懂的名字就行了,比如我填寫了"TranslateAPI",這樣比較直接。同理可以建立ComputerVisionAPI服務。服務的名字不會在Code中使用。
我們廢了老鼻子勁,得到了以下兩個REST API的Endpoint和相關的Key:
OCR服務
Endpoint: https://westcentralus.api.cognitive.microsoft.com/vision/v2.0
Text Translate文本翻譯服務
Endpoint: https://api.cognitive.microsofttranslator.com/translate?api-version=3.0
小提示:以上兩個Endpoint的URL是目前最新的版本,請不要使用舊的版本如v1.0等等。
咱們是洗洗睡了,還是寫代碼?看天色還早,繼續寫代碼吧!
建構這個PC桌面應用,我們需要幾個步驟:
在得到第一次的顯示結果後,經過測試,有很大可能會根據結果再對界面進行調整,實際上也是一個局部的軟體工程中的疊代開發。
啟動Visual Studio 2017, 建立一個基于C#語言的WPF(Windows Presentation Foundation)項目:
WPF是一個非常成熟的技術,在有界面展示和互動的情況下,使用XAML設計/渲染引擎,比WinForm程式要強101倍,再加上有C#語言利器的幫助,是寫PC桌面前端應用的最佳組合。
給Project起個名字,比如叫"CartoonTranslate",選擇最新的.NET Framework (4.6以上),然後點選"OK"。我們先一起來設計一下界面:
Input URL:用于輸入網際網路上的一張漫畫圖檔的URL
Engine:指的是兩個不同的算法引擎,其中,OCR舊引擎可以支援25種語言,識别效果可以接受;而Recognize Text新引擎目前隻能支援英文,但效果比較好。
Language:制定目前要翻譯的漫畫的語言,我們隻以英文和日文為例,其它國家的漫畫相對較少,但一通百通,一樣可以支援。
右側的一堆Button了解一下:
Show:展示Input URL中的圖檔到下面的圖檔區
OCR:調用OCR服務
Translate:調用文本翻譯服務,将日文或者英文翻譯成中文
下側大面積的圖檔區了解一下:
Source Image:原始漫畫圖檔
Target Image:翻譯成中文對白後的漫畫圖檔
我們在MainWindow.xaml檔案裡面填好以下code:
關于XAML文法的問題不在本文的讨論範圍之内。上面的XAML寫好後,編譯時會出錯,因為裡面定義了很多事件,在C#檔案中還沒有實作。是以,我們現在把事件代碼補上。
局部變量定義(在MainWindow.xaml.cs的MainWindow class裡面):
點選Show按鈕的事件,把URL中的漫畫的位址所指向的圖檔加載到視窗中顯示:
在上面的代碼中,同時給左右兩個圖檔區域指派,顯示兩張一樣的圖檔。
點選OCR按鈕的事件,會調用OCR REST API,然後根據傳回結果把所有識别出來的文字用紅色的矩形框标記上:
在上面的代碼中,通過調用DoOCR()自定義函數傳回了反序列化好的類,再依次把傳回結果集中的每個矩形生成一個Rectangle圖形類,它的left和top用Margin的方式來定義,width和height直接指派即可,把這些Rectangle圖形類的執行個體添加到canvas_1的Visual Tree裡即可顯示出來(這個就是WPF的好處啦,不用處理繪圖事件,但性能不如用Graphics類直接繪圖)。
點選Translate按鈕的事件:
上面這段代碼中,包含了兩個函數:this.Translate()和this.ShowTargetText()。
我們先看第一個函數:最難了解的地方可能是有個"25"數字,這是因為Translate API允許一次送出多個字元串并一起傳回結果,這樣比你送出25次字元串要快的多。翻譯好的結果按順序放在listOutput裡,供後面使用。
再看第二個函數:先根據原始文字的矩形區域,生成一些白色的實心矩形,把它們貼在右側的目标圖檔上,達到把原始文字覆寫(扣去)的目的。然後再根據每個原始矩形生成一個TextBlock,設定好它的位置和尺寸,再設定好翻譯後的結果(translatedLine),這樣就可以把中文文字貼到圖上了。
點選Radio Button的事件:
我們需要在CatroonTranslate工程中添加以下三個.cs檔案:
CognitiveServiceAgent.cs
OcrResult.cs
TranslateResult.cs
CognitiveServiceAgent.cs檔案完成與REST API互動的工作,包括調用OCR服務的和調用翻譯服務的代碼:
小提示:以上兩個Key是無法直接使用的,請使用自己申請的Key。
其中,DoTranslate()函數和DoOCR()函數都是HTTP調用,很容易了解。隻有CreateJsonBodyElement函數需要解釋一下。前面提到過我們一次允許給伺服器送出25個字元串做批量翻譯,是以傳進來的是個List<string>,經過這個函數的簡單處理,會得到以下JSON格式的資料作為HTTP的Body:
OcrResult.cs檔案是OCR服務傳回的JSON資料所對應的類,用于反序列化:
需要說明的是,伺服器傳回的boundingBox是個string類型,在後面使用起來不太友善,需要把它轉換成整數,是以增加了CovertBBFromString2Int()函數。還有就是傳回的是一個個的詞(Word),而不是一句話,是以增加了CombineWordToSentence()來把詞連成句子。
TranslateResult.cs檔案翻譯服務傳回的JSON所對應的類,用于反序列化:
小提示:在VS2017中,這種類不需要手工鍵入,可以在Debug模式下先把傳回的JSON拷貝下來,然後建立一個.cs檔案,在裡面用Paste Special從JSON直接生成類就可以了。
好啦,大功告成!現在要做的事就是點選F5來編譯執行程式。如果一切順利的話,将會看到界面設計部分所展示的視窗。
我們第一步先點選"Show"按鈕,會得到:
再點選"OCR"按鈕,等兩三秒(取決于網絡速度),會看到左側圖檔中紅色的矩形圍攏的一些文字。有些文字沒有被識别出來的話,就沒有紅色矩形。
最後點選"Translate"按鈕,稍等一小會兒,會看到右側圖檔的變化:
Wow! 大部分的日文被翻譯成了中文,而且位置也擺放得很合适。
目前的代碼中沒有很多容錯機制,比如當伺服器傳回錯誤時,通路API的代碼會傳回一個NULL對象,在上層沒有做處理,直接崩潰。再比如,當使用者不按照從左到右的順序點選上面三個button時,會産生意想不到的情況。
本應用處理單頁的漫畫,并且提供了互動,目的是讓大家直覺了解工作過程,實際上這個過程可以做成批量自動化的,也就是輸入一大堆URL,做背景識别/翻譯/重新生成圖檔後,把圖檔批量儲存在本地,再進行後處理。
當然,識别引擎不是萬能的,很多時候不可能準确識别/翻譯出所有對白文字。是以,可以考慮提供一個類似本應用的互動工具,讓漫畫翻譯從業者在機器處理之後,對有錯誤的地方進行糾正。
小提示:請嚴格遵守知識産權保護法!在合法的情況下做事。
還記得前面提到過新舊引擎的話題嗎?我們在界面上做了一個Radio Button "Recognize Text",但是并沒有使用它。因為這個新引擎目前還隻能支援英文的OCR,是以,如果大家對漫威Marvel漫畫(英文為主)感興趣的話,就可以用到這個引擎啦,與舊OCR引擎相比,不能同日而語,超級棒!
舊OCR引擎的文檔在這裡:https://westus.dev.cognitive.microsoft.com/docs/services/5adf991815e1060e6355ad44/operations/56f91f2e778daf14a499e1fc
新Recognize Text引擎的文檔在這裡:
https://westus.dev.cognitive.microsoft.com/docs/services/5adf991815e1060e6355ad44/operations/587f2c6a154055056008f200
新的引擎在API互動設計上,有一個不同的地方:當你送出一個請求後,伺服器會立刻傳回Accepted (202),然後給你一個URL,用于查詢狀态的。于是需要在用戶端程式裡設個定時器,每隔一段時間(比如200ms),通路那個URL,來獲得最終的OCR結果。
傳回的結果JSON格式也有所不同,大家可以自己試着實作一下:
在下圖中,如綠色橢圓區域所示,OCR引擎犯了一個小錯誤,它把上下兩個不同對白氣泡的文字框在了一起。
這個是可以在自己的程式裡做後期糾錯處理來矯正的。大家可以仔細分析OCR的傳回結果,看看如何實作。文檔在這裡:
https://westus.dev.cognitive.microsoft.com/docs/services/5adf991815e1060e6355ad44/operations/56f91f2e778daf14a499e1fc
觀察力好的同學,可能會發現一個問題,如下圖所示,左側圖的一個對白氣泡裡,有四句話,但其實它們是一句話,分開寫到4列而已。
這種情況帶來的問題是:這四句話分别送給翻譯引擎做翻譯,會造成前後不連貫,語句不通順。可以考慮的解決方案是,先根據矩形的位置資訊,把這四句話合并成同一句話,再送給翻譯引擎。這就是标準的聚類問題,通過搜尋引擎可以找到一大堆參考文檔,比如這些:
https://blog.csdn.net/summer_upc/article/details/51475512
https://www.ibm.com/developerworks/cn/analytics/library/ba-1607-clustering-algorithm/index.html