deployment controller是kube-controller-manager元件中衆多控制器中的一個,是 deployment 資源對象的控制器,其通過對deployment、replicaset、pod三種資源的監聽,當三種資源發生變化時會觸發 deployment controller 對相應的deployment資源進行調諧操作,進而完成deployment的擴縮容、暫停恢複、更新、復原、狀态status更新、所屬的舊replicaset清理等操作。
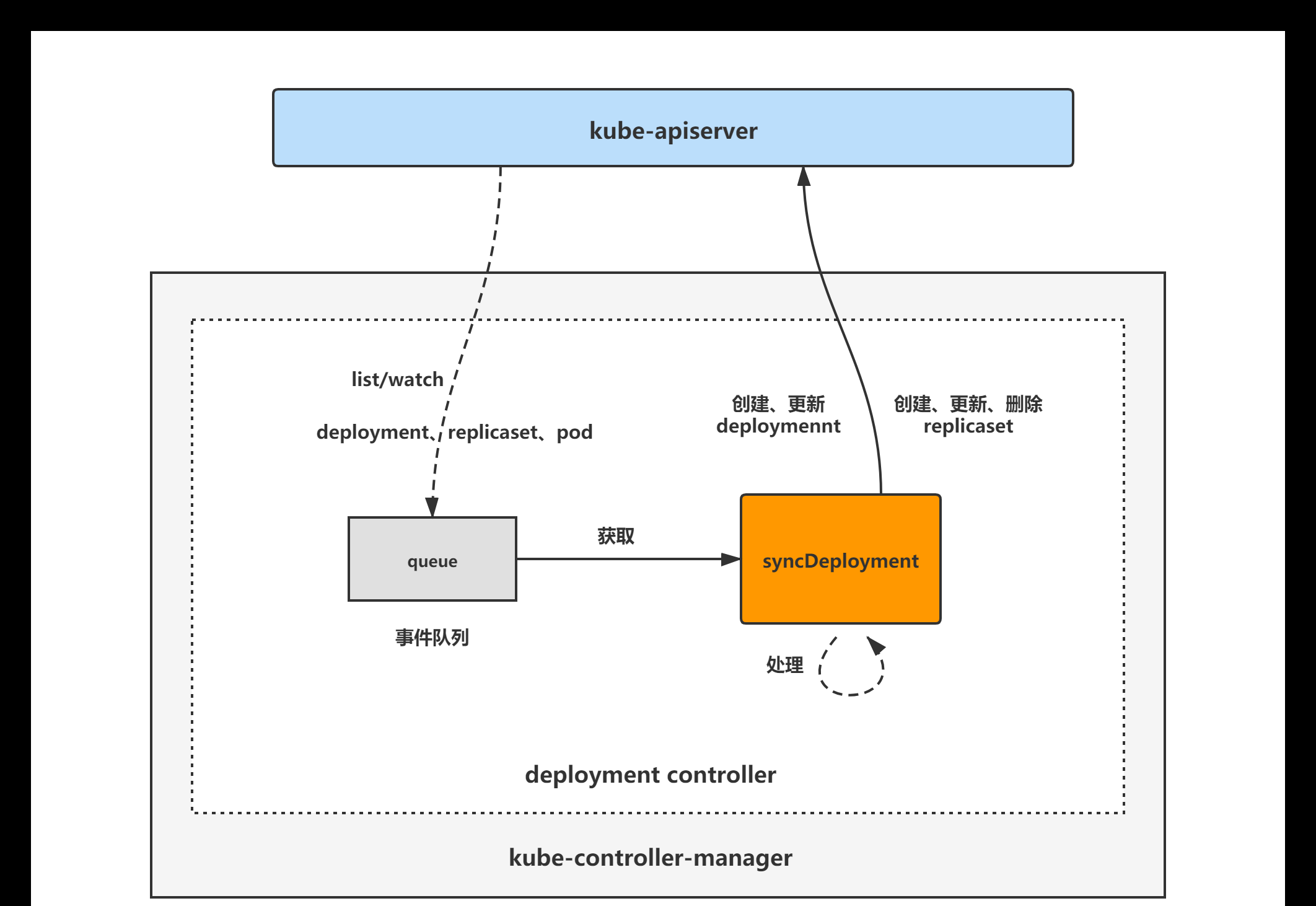
deployment controller的大緻組成和處理流程如下圖,deployment controller對pod、replicaset和deployment對象注冊了event handler,當有事件時,會watch到然後将對應的deployment對象放入到queue中,然後<code>syncDeployment</code>方法為deployment controller調諧deployment對象的核心處理邏輯所在,從queue中取出deployment對象,做調諧處理。
deployment controller分析将分為兩大塊進行,分别是:
(1)deployment controller初始化與啟動分析;
(2)deployment controller處理邏輯分析。
https://github.com/kubernetes/kubernetes/releases/tag/v1.17.4
直接看到startDeploymentController函數,作為deployment controller初始化與啟動分析的入口。
startDeploymentController主要邏輯:
(1)調用deployment.NewDeploymentController建立并初始化DeploymentController;
(2)拉起一個goroutine,跑DeploymentController的Run方法。
從<code>deployment.NewDeploymentController</code>函數代碼中可以看到,deployment controller注冊了deployment、replicaset與pod對象的EventHandler,也即對這幾個對象的event進行監聽,把event放入事件隊列并做處理。并且将<code>dc.syncDeployment</code>方法指派給<code>dc.syncHandler</code>,也即注冊為核心處理方法,在<code>dc.Run</code>方法中會調用該核心處理方法來調諧deployment對象(核心處理方法後面會進行詳細分析)。
主要看到for循環處,根據workers的值(來源于kcm啟動參數<code>concurrent-deployment-syncs</code>配置),啟動相應數量的goroutine,跑<code>dc.worker</code>方法,主要是調用前面講到的deployment controller核心處理方法<code>dc.syncDeployment</code>。
從queue隊列中取出事件key,并調用<code>dc.syncHandle</code>即<code>dc.syncDeployment</code>做調諧處理。queue隊列裡的事件來源前面講過,是deployment controller注冊的deployment、replicaset與pod對象的EventHandler,它們的變化event會被監聽到然後放入queue中。
進行核心處理邏輯分析前,先來了解幾個關鍵概念。
進行代碼分析前,先來看幾個關鍵的概念。
(1)最新的replicaset對象
怎樣的replicaset對象是最新的呢?replicaset對象的pod template與deployment的一緻,則代表該replicaset是最新的。
(2)舊的replicaset對象
怎樣的replicaset對象是舊的呢?除去最新的replicaset對象,其餘的都是舊的replicaset。
(3)ready狀态的pod
pod對象的<code>.status.conditions</code>中,<code>type</code>為<code>Ready</code>的<code>condition</code>中,其<code>status</code>屬性值為<code>True</code>,則代表該pod屬于ready狀态。
而<code>type</code>為<code>Ready</code>的<code>condition</code>中,其<code>status</code>屬性值會pod的各個容器都ready之後,将其值設定為<code>True</code>。
pod裡的容器何時ready?kubelet會根據容器配置的readiness probe就緒探測政策,在探測成功後更新pod的status将該容器設定為ready,yaml示例如下。
(4)available狀态的pod
pod處于ready狀态且已經超過了<code>minReadySeconds</code>時間後,該pod即處于available狀态。
直接看到deployment controller核心處理方法syncDeployment。
主要邏輯:
(1)擷取執行方法時的目前時間,并定義<code>defer</code>函數,用于計算該方法總執行時間,也即統計對一個 deployment 進行同步調諧操作的耗時;
(2)根據 deployment 對象的命名空間與名稱,擷取 deployment 對象;
(3)調用<code>dc.getReplicaSetsForDeployment</code>:對叢集中與deployment對象相同命名空間下的所有replicaset對象做處理,若發現比對但沒有關聯 deployment 的 replicaset 則通過設定 ownerReferences 字段與 deployment 關聯,已關聯但不比對的則删除對應的 ownerReferences,最後擷取傳回叢集中與 Deployment 關聯比對的 ReplicaSet對象清單;
(4)調用<code>dc.getPodMapForDeployment</code>:根據deployment對象的selector,擷取目前 deployment 對象關聯的 pod,根據 deployment 所屬的 replicaset 對象的<code>UID</code>對 pod 進行分類并傳回,傳回值類型為<code>map[types.UID][]*v1.Pod</code>;
(5)如果 deployment 對象的 <code>DeletionTimestamp</code> 屬性值不為空,則調用<code>dc.syncStatusOnly</code>,根據deployment 所屬的 replicaset 對象,重新計算出 deployment 對象的<code>status</code>字段值并更新,調用完成後,直接return,不繼續往下執行;
(6)調用<code>dc.checkPausedConditions</code>:檢查 deployment 是否為<code>pause</code>狀态,是則更新deployment對象的<code>status</code>字段值,為其添加<code>pause</code>相關的<code>condition</code>;
(7)判斷deployment對象的<code>.Spec.Paused</code>屬性值,為<code>true</code>時,則調用<code>dc.sync</code>做處理,調用完成後直接return;
(8)調用<code>getRollbackTo</code>檢查deployment對象的<code>annotations</code>中是否有以下key:<code>deprecated.deployment.rollback.to</code>,如果有且值不為空,調用 <code>dc.rollback</code> 方法執行 復原操作;
(9)調用<code>dc.isScalingEvent</code>:檢查deployment對象是否處于 <code>scaling</code> 狀态,是則調用<code>dc.sync</code>做擴縮容處理,調用完成後直接return;
(10)判斷deployment對象的更新政策,當更新政策為<code>Recreate</code>時調用<code>dc.rolloutRecreate</code>做進一步處理,也即對deployment進行recreate更新處理;當更新政策為<code>RollingUpdate</code>時調用<code>dc.rolloutRolling</code>做進一步處理,也即對deployment進行滾動更新處理。
dc.getReplicaSetsForDeployment主要作用:擷取叢集中與 Deployment 相關的 ReplicaSet,若發現比對但沒有關聯 deployment 的 replicaset 則通過設定 ownerReferences 字段與 deployment 關聯,已關聯但不比對的則删除對應的 ownerReferences。
主要邏輯如下:
(1)擷取deployment對象命名空間下的所有replicaset對象;
(2)調用<code>cm.ClaimReplicaSets</code>對replicaset做進一步處理,并最終傳回與deployment比對關聯的replicaset對象清單。
周遊與deployment對象相同命名空間下的所有replicaset對象,調用<code>m.ClaimObject</code>做處理,<code>m.ClaimObject</code>的作用主要是将比對但沒有關聯 deployment 的 replicaset 則通過設定 ownerReferences 字段與 deployment 關聯,已關聯但不比對的則删除對應的 ownerReferences。
dc.getPodMapForDeployment:根據deployment對象的Selector,擷取目前 deployment 對象關聯的 pod,根據 deployment 所屬的 replicaset 對象的<code>UID</code>對 pod 進行分類并傳回,傳回值類型為<code>map[types.UID][]*v1.Pod</code>。
如果 deployment 對象的 <code>DeletionTimestamp</code> 屬性值不為空,則調用<code>dc.syncStatusOnly</code>,根據deployment 所屬的 replicaset 對象,重新計算出 deployment 對象的<code>status</code>字段值并更新,調用完成後,直接return,不繼續往下執行;
關于具體如何計算出deployment對象的status,可以檢視<code>calculateStatus</code>函數,計算邏輯都在裡面,這裡不展開分析。
先調用<code>getRollbackTo</code>檢查deployment對象的<code>annotations</code>中是否有以下key:<code>deprecated.deployment.rollback.to</code>,如果有且值不為空,調用 <code>dc.rollback</code> 方法執行 <code>rollback</code> 操作;
dc.rollback主要邏輯:
(1)擷取deployment的所有關聯比對的replicaset對象清單;
(2)擷取需要復原的Revision;
(3)周遊上述獲得的replicaset對象清單,比較Revision是否與需要復原的Revision一緻,一緻則調用<code>dc.rollbackToTemplate</code>做復原操作(主要是根據特定的Revision的replicaset對象,更改deployment對象的<code>.Spec.Template</code>);
(4)最後,不管有沒有復原成功,都将deployment對象的<code>.spec.rollbackTo</code>屬性置為nil,然後更新deployment對象。
下面來分析一下dc.sync方法,以下兩種情況下,都會調用dc.sync,然後直接return:
(1)判斷deployment的<code>.Spec.Paused</code>屬性值是否為true,是則調用<code>dc.sync</code>做處理,調用完成後直接return;
(2)先調用<code>dc.isScalingEvent</code>,檢查deployment對象是否處于 <code>scaling</code> 狀态,是則調用<code>dc.sync</code>做處理,調用完成後直接return。
關于Paused字段
deployment的<code>.Spec.Paused</code>為true時代表該deployment處于暫停狀态,false則代表處于正常狀态。當deployment處于暫停狀态時,deployment對象的PodTemplateSpec的任何修改都不會觸發deployment的更新,當<code>.Spec.Paused</code>再次指派為false時才會觸發deployment更新。
dc.sync主要邏輯:
(1)調用<code>dc.getAllReplicaSetsAndSyncRevision</code>擷取最新的replicaset對象以及舊的replicaset對象清單;
(2)調用<code>dc.scale</code>,判斷是否需要進行擴縮容操作,需要則進行擴縮容操作;
(3)當deployment的<code>.Spec.Paused</code>為true且不需要做復原操作時,調用<code>dc.cleanupDeployment</code>,根據deployment配置的保留曆史版本數(<code>.Spec.RevisionHistoryLimit</code>)以及replicaset的建立時間,把最老的舊的replicaset給删除清理掉;
(4)調用<code>dc.syncDeploymentStatus</code>,計算并更新deployment對象的status字段。
dc.scale主要作用是處理deployment的擴縮容操作,其主要邏輯如下:
(1)調用<code>deploymentutil.FindActiveOrLatest</code>,判斷是否隻有最新的replicaset對象的副本數不為0,是則找到最新的replicaset對象,并判斷其副本數是否與deployment期望副本數一緻,是則直接return,否則調用<code>dc.scaleReplicaSetAndRecordEvent</code>更新其副本數為deployment的期望副本數;
(2)當最新的replicaset對象的副本數與deployment期望副本數一緻,且舊的replicaset對象中有副本數不為0的,則從舊的replicset對象清單中找出副本數不為0的replicaset,調用<code>dc.scaleReplicaSetAndRecordEvent</code>将其副本數縮容為0,然後return;
(3)當最新的replicaset對象的副本數與deployment期望副本數不一緻,舊的replicaset對象中有副本數不為0的,且deployment的更新政策為滾動更新,說明deployment可能正在滾動更新,則按一定的比例對新舊replicaset進行擴縮容操作,保證滾動更新的穩定性,具體邏輯可以自己分析下,這裡不展開分析。
當deployment的所有pod都是updated的和available的,而且沒有舊的pod在running,則調用<code>dc.cleanupDeployment</code>,根據deployment配置的保留曆史版本數(<code>.Spec.RevisionHistoryLimit</code>)以及replicaset的建立時間,把最老的舊的replicaset給删除清理掉。
判斷deployment對象的更新政策<code>.Spec.Strategy.Type</code>,當更新政策為<code>Recreate</code>時調用<code>dc.rolloutRecreate</code>做進一步處理。
dc.rolloutRecreate主要邏輯:
(1)調用<code>dc.getAllReplicaSetsAndSyncRevision</code>,擷取最新的replicaset對象以及舊的replicaset對象清單;
(2)調用<code>dc.scaleDownOldReplicaSetsForRecreate</code>,縮容舊的replicaSets,将它們的副本數更新為0,當有舊的replicasets需要縮容時,調用<code>dc.syncRolloutStatus</code>更新deployment狀态後直接return;
(3)調用<code>oldPodsRunning</code>函數,判斷是否有屬于deployment的pod還在running(pod的<code>pod.Status.Phase</code>屬性值為<code>Failed</code>或<code>Succeeded</code>時代表該pod不在running),還在running則調用<code>dc.syncRolloutStatus</code>更新deployment狀态并直接return;
(4)當新的replicaset對象沒有被建立時,調用<code>dc.getAllReplicaSetsAndSyncRevision</code>來建立新的replicaset對象(注意:新建立的replicaset的副本數為0);
(5)調用<code>dc.scaleUpNewReplicaSetForRecreate</code>,擴容剛新建立的replicaset,更新其副本數與deployment期望副本數一緻(即deployment的<code>.Spec.Replicas</code>屬性值);
(6)調用<code>util.DeploymentComplete</code>,檢查deployment的所有pod是否都是updated的和available的,而且沒有舊的pod在running,是則繼續調用<code>dc.cleanupDeployment</code>,根據deployment配置的保留曆史版本數(<code>.Spec.RevisionHistoryLimit</code>)以及replicaset的建立時間,把最老的舊的replicaset給删除清理掉。
(7)調用<code>dc.syncRolloutStatus</code>更新deployment狀态。
dc.getAllReplicaSetsAndSyncRevision會擷取所有的舊的replicaset對象,以及最新的replicaset對象,然後傳回。
關于最新的replicaset對象,怎樣的replicaset對象是最新的呢?replicaset對象的pod template與deployment的一緻,則代表該replicaset是最新的。
關于舊的replicaset對象,怎樣的replicaset對象是舊的呢?除去最新的replicaset對象,其餘的都是舊的replicaset。
syncRolloutStatus方法主要作用是計算出deployment的新的status屬性值并更新,具體的計算邏輯可以自己檢視代碼,這裡不展開分析。
周遊deployment下所有的pod,找到屬于舊的replicaset對象的pod,判斷pod的狀态(即<code>pod.Status.Phase</code>的值)是否都是<code>Failed</code>或<code>Succeeded</code>,是則代表所有舊的pod都沒在running了,傳回false。
dc.getAllReplicaSetsAndSyncRevision方法主要作用是擷取最新的replicaset對象以及舊的replicaset對象清單,當傳入的<code>createIfNotExisted</code>變量值為true且新的replicaset對象不存在時,調用dc.getNewReplicaSet時會建立replicaset對象(建立的replicaset對象副本數為0)。
周遊全部舊的replicaset,調用<code>dc.scaleReplicaSetAndRecordEvent</code>将其副本數縮容為0。
調用<code>dc.scaleReplicaSetAndRecordEvent</code>,将最新的replicset對象的副本數更新為deployment期望的副本數。
判斷deployment對象的更新政策<code>.Spec.Strategy.Type</code>,當更新政策為<code>RollingUpdate</code>時調用<code>dc.rolloutRolling</code>做進一步處理。
dc.rolloutRolling主要邏輯:
(1)調用<code>dc.getAllReplicaSetsAndSyncRevision</code>,擷取最新的replicaset對象以及舊的replicaset對象清單,當新的replicaset對象不存在時,将建立一個新的replicaset對象(副本數為0);
(2)調用<code>dc.reconcileNewReplicaSet</code>,調諧新的replicaset對象,根據deployment的滾動更新政策配置<code>.Spec.Strategy.RollingUpdate.MaxSurge</code>和現存pod數量進行計算,決定是否對新的replicaset對象進行擴容以及擴容的副本數;
(3)當新的replicaset對象副本數在調諧時被更新,則調用<code>dc.syncRolloutStatus</code>更新deployment狀态後直接return;
(4)調用<code>dc.reconcileOldReplicaSets</code>,根據deployment的滾動更新政策配置<code>.Spec.Strategy.RollingUpdate.MaxUnavailable</code>、現存的Available狀态的pod數量、新replicaset對象下所屬的available的pod數量,決定是否對舊的replicaset對象進行縮容以及縮容的副本數;
(5)當舊的replicaset對象副本數在調諧時被更新,則調用<code>dc.syncRolloutStatus</code>更新deployment狀态後直接return;
dc.reconcileNewReplicaSet主要作用是調諧新的replicaset對象,根據deployment的滾動更新政策配置和現存pod數量進行計算,決定是否對新的replicaset對象進行擴容。
(1)當新的replicaset對象的副本數與deployment聲明的副本數一緻,則說明該replicaset對象無需再調諧,直接return;
(2)當新的replicaset對象的副本數比deployment聲明的副本數要大,則調用<code>dc.scaleReplicaSetAndRecordEvent</code>,将replicaset對象的副本數縮容至與deployment聲明的副本數一緻,然後return;
(3)當新的replicaset對象的副本數比deployment聲明的副本數要小,則調用<code>deploymentutil.NewRSNewReplicas</code>,根據deployment的滾動更新政策配置<code>.Spec.Strategy.RollingUpdate.MaxSurge</code>的值計算出新replicaset對象該擁有的副本數量,并調用<code>dc.scaleReplicaSetAndRecordEvent</code>更新replicaset的副本數。
NewRSNewReplicas
當deployment配置了滾動更新政策時,<code>NewRSNewReplicas</code>函數将根據<code>.Spec.Strategy.RollingUpdate.MaxSurge</code>的配置,調用<code>intstrutil.GetValueFromIntOrPercent</code>計算出<code>maxSurge</code>(代表滾動更新時可超出deployment聲明的副本數的最大值),最終根據<code>maxSurge</code>與現存pod數量計算出新的replicaset對象該擁有的副本數。
intstrutil.GetValueFromIntOrPercent
maxSurge的計算也不複雜,當<code>maxSurge</code>為百分比時,因為函數入參<code>roundUp</code>為<code>true</code>,是以計算公式為:<code>maxSurge = ⌈deployment.Spec.Strategy.RollingUpdate.MaxSurge * deployment.Spec.Replicas / 100⌉</code>(結果向上取整) ;
當<code>maxSurge</code>不為百分比時,直接傳回其值。
dc.reconcileNewReplicaSet主要作用是調諧舊的replicaset對象,根據deployment的滾動更新政策配置<code>.Spec.Strategy.RollingUpdate.MaxUnavailable</code>和現存的Available狀态的pod數量進行計算,決定是否對舊的replicaset對象進行縮容。
(1)擷取舊的replicaset對象的副本數總數,如果是0,則代表舊的replicaset對象已經無法縮容,調諧完畢,直接return;
(2)調用<code>deploymentutil.MaxUnavailable</code>,計算擷取<code>maxUnavailable</code>的值,即最大不可用pod數量(這裡注意一點,當deployment滾動更新政策中<code>MaxUnavailable</code>與<code>MaxSurge</code>的配置值都為0時,此處計算<code>MaxUnavailable</code>的值時會傳回1,因為這兩者均為0時,無法進行滾動更新);
(3)根據<code>MaxUnavailable</code>的值、deployment的期望副本數、新replicaset對象的期望副本數、新replicaset對象的處于<code>Available</code>狀态的副本數,計算出<code>maxScaledDown</code>即最大可縮容副本數,當<code>maxScaledDown</code>小于等于0,則代表目前暫不能對舊的replicaset對象進行縮容,直接return;
(4)調用<code>dc.cleanupUnhealthyReplicas</code>,按照replicaset的建立時間排序,先清理縮容<code>Unhealthy</code>的副本(如<code>not-ready</code>的、<code>unscheduled</code>的、<code>pending</code>的pod),具體邏輯暫不展開分析;
(5)調用<code>dc.scaleDownOldReplicaSetsForRollingUpdate</code>,根據deployment的滾動更新政策配置<code>.Spec.Strategy.RollingUpdate.MaxUnavailable</code>計算出舊的replicaset對象該擁有的副本數量,調用<code>dc.scaleReplicaSetAndRecordEvent</code>縮容舊的replicaset對象(是以這裡也可以看到,<code>dc.cleanupUnhealthyReplicas</code>與<code>dc.scaleDownOldReplicaSetsForRollingUpdate</code>均有可能會對舊的replicaset進行縮容操作);
(6)如果縮容的副本數大于0,則傳回true,否則傳回false。
dc.scaleDownOldReplicaSetsForRollingUpdate
dc.scaleDownOldReplicaSetsForRollingUpdate主要邏輯是縮容舊的replicaset對象,主要邏輯如下:
(1)根據deployment的滾動更新政策配置<code>.Spec.Strategy.RollingUpdate.MaxUnavailable</code>和現存的Available狀态的pod數量,計算出<code>totalScaleDownCount</code>,即目前需要縮容的副本數;
(2)對舊的replicaset對象按照建立時間先後排序;
(3)周遊舊的replicaset對象,根據需要縮容的副本總數,縮容replicaset。
其中deployment的擴縮容、暫停恢複、更新、復原、狀态status更新、所屬的舊replicaset清理等操作都在deployment controller的核心處理方法<code>syncDeployment</code>裡進行處理調用。
關于deployment更新這一塊,deployment controller會根據deployment對象配置的更新政策Recreate或RollingUpdate,會調用<code>rolloutRecreate</code>或<code>rolloutRolling</code>方法來對deployment對象進行更新操作。
且經過以上的代碼分析,可以看出,deployment controller并不負責deployment對象的删除,除按曆史版本限制數需要清理删除多餘的replicaset對象以外,deployment controller也不負責replicset對象的删除(實際上,除按曆史版本限制數deployment controller需要清理删除多餘的replicaset對象以外,其他的replicaset對象的删除由garbagecollector controller完成)。

deployment controller的核心處理邏輯在<code>syncDeployment</code>方法中,下圖即<code>syncDeployment</code>方法的處理流程。
無論deployment配置了ReCreate還是RollingUpdate的更新政策,在<code>dc.rolloutRecreate</code>或<code>dc.rolloutRolling</code>的處理邏輯裡,都會判斷最新的replicaset對象是否存在,不存在則會建立。
在建立了deployment對象後,deployment controller會收到deployment的新增event,然後會做調諧處理,在第一次進入<code>dc.rolloutRecreate</code>或<code>dc.rolloutRolling</code>的處理邏輯時,deployment所屬的replicaset對象為空,是以會觸發建立一個新的replicaset對象出來。
(1)先縮容舊的replicaset,将其副本數縮容為0;
(2)等待舊的replicaset的pod全部都處于not running狀态(pod的<code>pod.Status.Phase</code>屬性值為<code>Failed</code>或<code>Succeeded</code>時代表該pod處于not running狀态);
(3)接着建立新的replicaset對象(注意:新建立的replicaset的執行個體副本數為0);
(4)随後擴容剛新建立的replicaset,更新其副本數與deployment期望副本數一緻;
(5)最後等待,直至deployment的所有pod都屬于最新的replicaset對象、pod數量與deployment期望副本數一緻、且所有pod都處于Available狀态,則deployment更新完成。
(1)根據deployment的滾動更新政策配置<code>.Spec.Strategy.RollingUpdate.MaxSurge</code>和現存pod數量進行計算,決定是否對新的replicaset對象進行擴容以及擴容的副本數;
(2)根據deployment的滾動更新政策配置<code>.Spec.Strategy.RollingUpdate.MaxUnavailable</code>、現存的Available狀态的pod數量、新replicaset對象下所屬的available的pod數量,決定是否對舊的replicaset對象進行縮容以及縮容的副本數;
(3)循環以上步驟,直至deployment的所有pod都屬于最新的replicaset對象、pod數量與deployment期望副本數一緻、且所有pod都處于Available狀态,則deployment滾動更新完成。
先來看到deployment滾動更新配置的兩個關鍵參數:
(1)<code>.Spec.Strategy.RollingUpdate.MaxUnavailable</code>:指定更新過程中不可用的 Pod 的個數上限。該值可以是絕對數字(例如5),也可以是deployment期望副本數的百分比(例如10%),運算公式:期望副本數乘以百分比值并向下取整。 如果maxSurge為0,則此值不能為0。MaxUnavailable預設值為 25%。該值越小,越能保證服務穩定,deployment更新越平滑。
(2)<code>.Spec.Strategy.RollingUpdate.MaxSurge</code>:指定可以建立的超出期望 Pod 個數的 Pod 數量。此值可以是絕對數(例如5),也可以是deployment期望副本數的百分比(例如10%),運算公式:期望副本數乘以百分比值并向上取整。 如果 MaxUnavailable 為0,則此值不能為0。 MaxSurge預設值為 25%。該值越大,deployment更新速度越快。
注意:MaxUnavailable與MaxSurge不能均配置為0,但可能在運算之後這兩個值均為0,這種情況下,為了保證滾動更新能正常進行,deployment controller會在滾動更新時将MaxUnavailable的值置為1去進行滾動更新。
例如,當deployment期望副本數為2、MaxSurge值為0、MaxUnavailable為1%時(MaxUnavailable為百分比,根據運算公式運算并向下取整後,取值為0,這時MaxSurge與MaxUnavailable均為0,是以在deployment滾動更新時,會将MaxUnavailable置為1去做滾動更新操作),觸發滾動更新後,會立即将舊 replicaSet 副本數縮容到1,并擴容新的replicaset副本數為1。待新 Pod Available後,可以繼續縮容舊有的 replicaSet副本數為0,然後擴容新的replicaset副本數為2。滾動更新期間確定Available可用的 Pods 總數在任何時候都至少為1個。
例如,當deployment期望副本數為2、MaxSurge值為1%、MaxUnavailable為0時(MaxSurge根據運算公式運算并向上取整,取值為1),觸發滾動更新後,會立即擴容新的replicaset副本數為1,待新pod Available後,再縮容舊replicaset副本數為1,然後再擴容擴容新的replicaset副本數為2,待新pod Available後,再縮容舊replicaset副本數為0。滾動更新期間確定Available可用的 Pods 總數在任何時候都至少為2個。
更多示例如下: