經常逛淘寶的同學應該會發現,淘寶移動用戶端首頁下拉有一個“猜你喜歡”的闆塊,經常會推薦一些你曾經在淘寶搜尋過的相關物品,偶爾确實給大家帶來小驚喜,那麼淘寶是怎麼做到的呢?
最近,阿裡團隊在arXiv.org上發表了兩篇關于實時競價(RTB)系統中的算法的論文,稱不僅能幫助商家在廣告競價中給出合理的政策,還能最大化商家的利潤。
以下是第一篇論文部分内容:
<b>基于多智能體強化學習的實時競價案例</b>
實時廣告為廣告商提供了一個為每個展位的訪客競價的平台。為了優化特定目标,如最大化廣告投放帶來的收入,廣告商不僅需要估計廣告和使用者興趣之間的相關性,最重要的是需要對其他廣告商在市場競價方面做出戰略回應。本文提出了一個實用的分布協同多智能體競價系統(DCMAB),并用于平衡廣告商之間交易的競争和合作關系。并利用阿裡行業的實際資料已經證明了該模組化方法的有效性。
競價優化是實時競價最關心的問題之一,其目的是幫助廣告商為每次拍賣的展示給出合理的出價,最大化競價系統的關鍵績效名額(KPI),如點選量或利潤。傳統的競價算法缺陷在于将競價優化作為一個靜态問題,進而無法實作合理的實時競價問題。
多智能體強化學習的關鍵在于如何設計使每個智能體良好合作的機制和學習算法。淘寶有數量龐大的廣告商,多智能體強化學習正好可以用來解燃眉之需。
淘寶的展示廣告系統
在淘寶廣告系統中,大多廣告商不僅投放廣告,也在淘寶電子商務平台上銷售他們的産品。淘寶廣告系統可以分為三部分如下圖所示:第一步是進行比對。通過挖掘使用者的行為資料獲得使用者的偏好預測,當接受到使用者請求時,根據實際情況,從整個廣告語料庫中實時比對部分候選廣告(通常按照順序)。其次,實時預測系統(RTP)預測每個推薦廣告的點選率(pCTR)和轉化率(pCVR)。最後,對候選廣告進行實時競價和排名顯示。
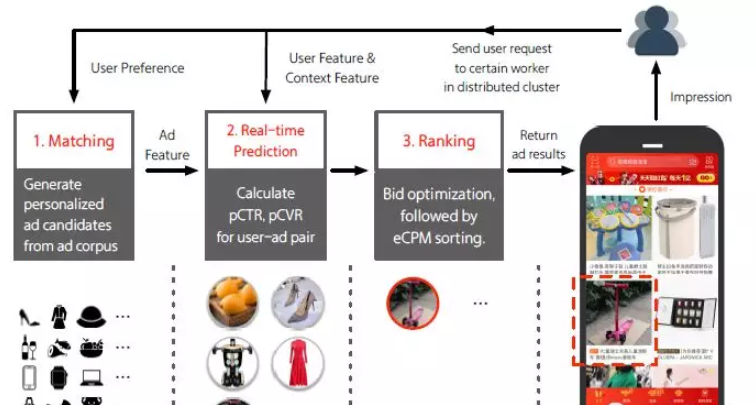
淘寶廣告系統概述
比對、實時預測和排名依次處理使用者的請求,然後傳回特定數量的廣告。這些廣告展示在淘寶用戶端的“猜你喜歡”闆塊中。
多智能體廣告競價算法原理
将實時競價看作一個随機遊戲,也叫做Markov對策。Markov 對策是将多步對策看作一個随機過程,并将傳統的Markov 決策過程( MDP)擴充到多個參與者的分布式決策過程(參考文獻:李曉萌, 楊煜普, 許曉鳴. 基于 MarkoV對策和強化學習的多智能體協作研究[J]. 上海交通大學學報, 2001, 35(2):288-292.)。

商家和消費者被分在不同的叢集中。每個商家群集都有一個Agent來調整不同消費者叢集的廣告競價。 對于行動a_ij,i疊代的是商家叢集數,j為消費者叢集數。 bratio_k代表商戶k的基本調整率。
由于輸出行為(競價調整)處于連續空間中,論文采用梯度确定性政策來學習競價算法。
(a)淘寶廣告系統中的DCMAB工作流程圖
狀态伺服器負責維護Agent的工作狀态,包括總體資訊g,消費分布d和消費靜态特征x^q。
(b)DCMAB 網絡結構設計
DCMAB示意圖
算法實作流程圖如下:
實驗
資料集和評估設定
資料集來自阿裡的行業資料,廣告的推薦效果展示在淘寶App首頁“猜你喜歡”中;
廣告商的收入作為主要的評估依據。
對比方法
手動設定競價(Manual)
上下文老虎機(Bandit)
Advantageous Actor-critic (A2C)
連續動作控制(DDPG)
分布協同多智能體競價系統(DCMAB)
實驗結果
表中為不同算法下廣告商自主競價的收益
表中列出了不同算法的收斂性能(假定算法的訓練收斂性能在後50個資料集沒有變化的情況下)。 表中每行資料顯示對應算法的結果,每一列資料是本次實驗中不同Agent叢集的結果和廣告商的總收入。研究人員對每個算法進行了4次實驗并給出了平均收入和标準差。
各種算法的學習曲線與基線的對比
實驗結果表明,DCMAB收斂比DDPG更穩定,驗證了将所有Agent的行為輸入行為-價值(action-value)函數這種模組化的有效性。DCMAB和DDPG的學習速度快于A2C和老虎機,顯示了基于記憶回訪的梯度确定性政策的優點。
第二篇論文是關于預算限制競價,給大家做簡單介紹,感興趣的同學可以下載下傳全文閱讀。
<b>基于無模型強化學習的預算限制競價</b>
實時競價(RTB)幾乎是線上展示廣告最重要的機制,每個頁面視圖的合理出價對良好的營銷結果起着至關重要的作用。預算限制競價是RTB機制中的典型場景,即廣告商希望在有限預算下最大化獲得使用者印象的總價值。
但是,由于交易環境的複雜性和不穩定性,實時競價的最優化政策往往很難實作。為解決上述問題,本文将預算限制競價視為馬爾可夫的決策過程進行處理。與之前的基于模型的工作完全不同,本文提出一種基于無模型增強學習的新型架構,順序調節競價參數而不是直接生成報價。
基于這個思路,通過部署深度神經網絡并學習如何給出适當回報,進而引導智能體提供最佳政策;本文也設計了一個自适應貪婪政策來動态調整探索行為和進一步提高性能。通過在真實資料集上測試表明,本文提出的架構真實有效。
原文釋出時間為:2018-03-8
本文作者:文摘菌