譯自:Distributed transaction patterns for microservices compared
作為Red Hat的顧問架構師,曾有幸參與過無數個客戶項目。每個客戶都存在各自的挑戰,但我發現其中存在一定的共性。其中,客戶最想了解的一件事情是如何在多個記錄系統中協調寫操作。解答這個問題通常需要耐心地解釋雙寫、分布式事務、替代方案、可能的故障場景以及各個方式的缺點等等。這時候客戶通常會意識到将一體式應用切分為微服務是一個漫長且艱難的過程,需要一定的取舍。
本文不會深入讨論事務系統,概括了在協調寫入多個資源時會用到的主要方法和模式。過去,你可能對其中一種或多種方法有良好或不好的體驗,但在合适的上下文、合适的限制條件下,這些方法都能夠發揮其各自的優點。
可以預見,在需要寫入多個記錄系統時可能會遇到雙寫問題。該需求可能不夠明确,在分布式系統設計過程中可以以不同的方式來表達該需求,例如:
你已經為每個任務選擇了合适的工具,現在需要更新NoSQL資料庫、查詢索引以及單個業務事務的緩存
你設計的服務需要更新其資料庫,并向其他服務發送此次變更
你可能有跨多個服務邊界的業務事務
由于使用者會重試失敗的調用,是以你不得不實作幂等服務操作
本文中使用了一個簡單的場景來評估在分布式事務中處理雙寫的多種方式,該場景中,一個用戶端應用會調用一個微服務。在圖1中,A 服務需要更新其資料庫,但同時需要調用B服務來執行一個寫操作。在我們的讨論中,不關注資料庫的類型以及服務到服務互動所使用的協定。
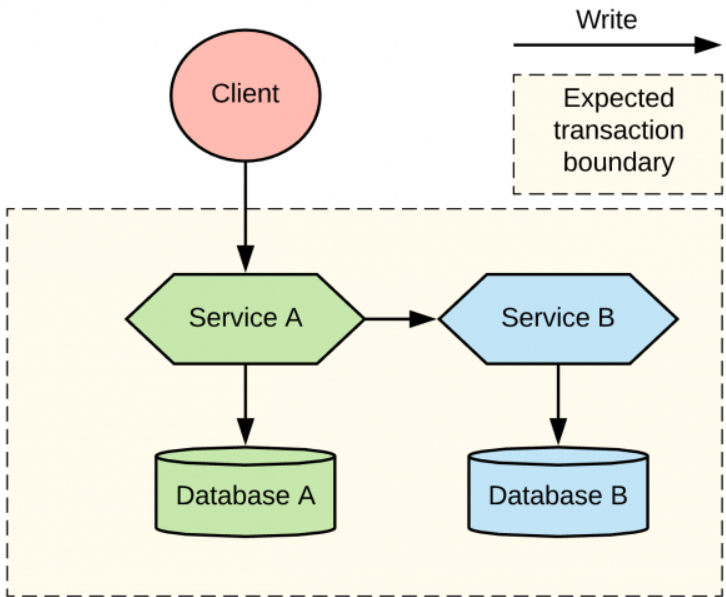
如果A服務寫入資料庫,然後向隊列中給B服務發送通知(将這種方式稱為本地送出-然後釋出(local-commit-then-publish ) ),但這種方式有一定機率無法保證可靠性。當A服務寫入其資料庫,然後向隊列發送消息,A服務有一定機率在送出後且發送消息前發送崩潰,導緻系統處于不一緻狀态。如果在寫入資料庫前發送消息(将這種方式稱為釋出-然後本地送出( publish-then-local-commit)),但此時仍然有一定機率發生資料庫寫入失敗或時序問題(在A服務送出到資料庫前,B服務接收到了該事件)。上述兩種場景都涉及對資料庫和隊列的雙寫,這也是下面需要探究的核心問題。在下面章節中,我将介紹幾種方法來應對這種一直都存在的挑戰。
将應用作為一體式子產品進行開發,聽起來可能在開架構演進的倒車,但實際上這種方式并沒有什麼問題。它不是微服務模式,但可以看作是微服務的例外,可以謹慎地與微服務組合在一起。當對強一緻性的寫入需求大于微服務的獨立部署和擴充時,就可以考慮采用一體式子產品架構。
使用一體式架構并不意味着系統不好或缺乏設計。顧名思義,它傳達了使用一個開發單元、以子產品方式進行設計的系統。注意,這是有意設計和實作的一體式子產品,而非随時間意外導緻的一體式的後果。在有目的性的一體式子產品架構中,每個子產品都會遵循微服務原則,每個子產品都封裝了所有對其資料的通路操作,并以記憶體方法調用的方式來暴露和消費操作。
使用這種方式,必須要将兩個微服務(A服務和B服務)轉化為可以部署到一個共享運作時的子產品庫。然後這兩個微服務就可以共享相同的資料庫執行個體。由于服務以庫的形式部署到相同的運作時中,是以就可以讓這兩個服務參與到相同的事務中。由于子產品共享相同的資料庫執行個體,是以可以使用一個本地事務一次性送出或復原所有操作。由于我們期望在更大規模的部署中以庫來部署服務,并參與到現有的事務中,是以在部署方法上也會存在一定的差異。
即使在一體式架構中,也有辦法隔離代碼和資料。例如,可以将子產品劃分到不同的包、構模組化塊和源代碼庫中,并由不同的團隊負責。可以根據命名規範、schemas、資料庫執行個體或資料庫伺服器來對表進行分組,以此來隔離部分資料。圖2描述了應用中不同的代碼和資料隔離級别,靈感來自Axel Fontaine的主題演講: 宏偉的一體式子產品。

最後看下如何在一個現有的事務中加入一個運作時以及封裝好的(可以使用其他子產品的)服務。相比典型的微服務,所有這些限制使得子產品之間的耦合更加緊密,但好處是,封裝的服務可以啟動一個事務,并調用子產品來(在一個操作中)執行資料的更新、送出或事務復原,而無需擔心局部故障或最終一緻性。
如圖3所示,我們将A服務和B服務轉換為子產品,并部署到一個共享的運作時中(或使用其中的一個服務作為共享的運作時)。資料庫表也共享了同一個資料庫執行個體,但對表進行了分組隔離,并由不同的庫服務管理。
在一些行業中,該架構帶來的好處要遠比快速傳遞和快速變更更加重要。表1概括了一體式子產品架構的優劣勢:
表1:一體式子產品的優劣勢
優勢
使用本地事務來保證資料一緻性、讀寫一緻性、復原等,事務語義比較簡單
劣勢
1. 共享運作時下無法進行獨立部署和子產品擴充,且無法進行故障隔離
2. 資料庫中的表的邏輯隔離性不強,後續可能會發展為一個共享的內建層
3. 需要在開發階段協調子產品的耦合性和共享事務上下文,這樣增加了服務間的耦合性
舉例
1. 運作時,如 Apache Karaf 和 WildFly,它們允許子產品化和動态部署服務
2. Apache Camel的<code>direct</code>和<code>direct-vm</code>元件,它們允許通過記憶體調用暴露操作,并支援通過JVM程序保留事務上下文
3. Apache Isis是一個很好的一體式子產品架構的例子。它通過為你的Spring Boot 應用自動生成UI和REST API來支援領域驅動的應用開發
4. Apache OFBiz是另一個一體式子產品和面向服務的架構(SOA)的例子。它是一個全面的企業資源規劃系統,擁有數百個表格和服務,可以自動化企業業務流程,其子產品化架構可以讓開發者快速了解并進行定制。
分布式事務通常是最後的手段,用于:
當寫入不同的資源時無法達到最終一緻性
當需要寫入各種各樣的資料源
當需要處理一次性消息,但無法對系統進行重構來實作幂等的操作
當內建了實作二階段送出規範的第三方黑盒系統或遺留系統
在上述場景中,如果不考慮可擴充性,我們可能會使用考慮分布式事務。
二階段送出需要一個分布式事務管理器(如Narayana),以及一個可靠的存儲層來儲存事務日志。你可能會用到可參與分布式事務的(帶相關XA驅動的)相容DTP XA的資料源,如RDBMS、消息代理和緩存等。如果正好有一個可用的資料源,但運作在一個動态環境中,如kubernetes,你還需要一個類operator的機制來保證隻能存在一個分布式事務管理器。事務管理器必須是高可用的,且能夠一直通路事務日志。
在實作時,可以參考用了kubernetes有狀态模式的Snowdrop Recovery Controller,它實作了單例模式,并使用PV來儲存事務日志。這種類型中,還可以為SOAP web服務引入如Web Services Atomic Transaction這樣的規範。這些技術的共同點是它們都實作了XA規範,并有一個中央事務協調器。
圖4中,A服務使用分布式将所有的變更送出到其資料庫,然後将消息發送到一個隊列,期間不會有消息重複或消息丢失。類似地,B服務使用分布式事務(在一條事務中)來消費消息并送出到資料庫B,且不會有資料重複。或者B服務可以不使用分布式事務,轉而使用本地事務,并實作幂等消費模式。更正式一點,可以在一條事務中使用WS-AtomicTransaction協調A資料庫和B資料庫的寫入,進而避免最終一緻性,但目前這種方式比較少見。
二階段送出協定提供了類似一體式子產品中的本地事務保證,但也有例外。由于原子更新中涉及到兩個或多個不同的資料源,資料源可能因各種原因産生故障或阻塞事務。但由于中央協調器的存在,相比其他方式(後面讨論),可以友善地發現分布式系統的狀态。
表2:二階段送出的優劣勢
1:标準方式,使用開箱即用的事務管理器以及資料源
2:強資料一緻性
1:可擴充性限制
2:當事務管理器故障時可能會導緻恢複失敗
3:支援的資料源有限
4:動态環境中需要存儲和單例模式
1: Jakarta Transactions API
2:WS-AtomicTransaction
3:JTS/IIOP
4:eBay’s GRIT
5:Atomikos
6:Narayana
7:消息代理,如Apache ActiveMQ
8:實作了XA規範的關系型資料源,記憶體資料庫如Infinispan
一體式子產品中,使用本地事務來了解系統的狀态。而在基于二階段送出協定的分布式事務中,需要保證狀态的一緻性,唯一例外是當事務協調器故障時可能會發生無法恢複的失敗。但如果我們想降低一緻性需求,同時仍然需要了解整體分布式系統的狀态并從一個地方進行協調,這時可以考慮使用編制模式,使用其中一個服務作為協調器和整體分布狀态變更的協調者。編制器服務負責調用其他服務,直到達到期望的狀态或在故障時采取正确的動作,編制器使用它的本地資料庫來跟蹤狀态變更,并負責恢複與狀态變更有關的故障。
最有名的編制技術的實作是BPMN規範實作,如 jBPM 和Camunda項目。對這類系統的需求并沒有随着分布式架構(如微服務或無服務)而消亡,反而在增加。可以看下最新的有狀态編制引擎,它們并沒有遵循這類規範,但卻提供了相似的有狀态行為,如Netflix的Conductor, Uber的Cadence, 和 Apache的Airflow。無服務有狀态功能,如Amazon StepFunctions, Azure Durable Functions, 和Azure Logic Apps都屬于這類。此外還有很多開源庫,可以幫助實作有狀态協調和復原行為,如Apache Camel的Saga 模式實作和NServiceBus Saga
圖5展示了将A服務作為有狀态協調器,負責調用B服務,并在需要時通過補償操作執行故障恢複。這種方法的關鍵特性是A服務和B服務都有本地事務邊界,但A服務了解并負責編制整體互動流程,這也是為什麼其邊界會涉及B服務的後端。在實作方面,可以設定同步互動(如圖所示),或在服務間使用消息隊列(這種情況下也可以使用二階段送出)。
編制是一種可能會涉及重試和復原來讓分布式系統達到最終一緻狀态的方法,編制要求參與的服務能夠提供幂等操作來讓協調器重試某個操作。參與的服務必須提供可恢複的後端,這樣協調器可以通過復原來恢複整體狀态。這種方式的最大好處是能夠通過本地事務讓可能不支援分布式事務的各種服務達到一緻性狀态。協調器和參與的服務僅需要本地事務,且總能夠通過查詢協調器了解到系統的狀态(即使是部分一緻的狀态)。
表3:編制的優劣勢
1. 在各種分布式元件中協調狀态
2. 不需要XA事務
3.可以在協調器層面了解到分布式狀态
1. 複雜的分布式程式設計模型
2. 參與的服務可能要提供幂等補償操作
3. 最終一緻性
4. 補償操作也可能無法執行故障恢複
1. jBPM
2. Camunda
3. MicroProfile Long Running Actions
4. Conductor
5. Cadence
6. Step Functions
7. Durable Functions
8. Apache Camel Saga pattern implementation
9. NServiceBus Saga pattern implementation
10. The CNCF Serverless Workflow specification
11. Homegrown implementations
可以看到,到目前為止,單個業務操作可能會涉及多個服務間的調用,且端到端的業務事務處理并沒有明确的時間。為了處理這種場景,編制模式使用一個中央控制器服務來告訴參與者應該做什麼。
編制的替代方案是編排,它也是一種服務協調模式,但不需要中央控制點來協調參與者之間的事件互動。這種模式下,每個服務會執行本地事務,然後釋出事件并觸發其他服務的本地事務。由系統中參與的每個元件決定業務事務的工作流(而不會依賴中央控制點)。在過去,服務間互動時經常會使用異步消息層來實作編排方式。圖6展示了編排模式架構。
為了讓基于消息的編排能夠正常工作,每個參與的服務需要執行一個本地事務并通過向消息設施中釋出指令或事件來觸發下一個服務。類似地,其他參與的服務需要消費消息并執行本地事務,其本身就是在更進階别的雙寫問題中的雙重寫問題。當通過開發一個帶雙寫的消息層來實作編排方式時,需要将其設計為一個跨本地資料庫和消息代理的二階段送出,或者可以使用 分布-然後本地送出 或 本地送出-然後釋出 的模式:
釋出-然後本地送出:首先嘗試釋出一個消息,然後送出到本地事務。雖然這種方式聽起來不錯,但實際中會有很多挑戰。例如,你可能需要釋出一個本地事務送出時生成的ID,但這種方式下無法首先擷取到這個ID。且本地事務可能會失敗,但無法復原已釋出的消息。這種方式缺乏讀寫一緻語義,大多數場景下并不适用。
本地送出-然後釋出:首先送出到本地事務,然後釋出消息。這種方式在本地事務送出之後且消息釋出前有很小的機率會出現故障。但即使這樣,你也可以通過讓服務實作幂等和重試來解決這種問題,即重新送出本地事務并釋出消息。如果你可以控制下遊消費者并使其幂等時,就可以考慮使用這種方式(同時也是一個不錯的選項)。
各種實作了編排的架構都會限制每個服務隻能用本地事務寫入單個資料源。下面看下如何在無雙寫場景下工作。
假設A服務接收到請求,并寫入A資料庫。B服務周期性輪詢服務A并檢測新的變更。當它讀取到變更時,B服務會使用此次變更更新其資料庫以及對應的索引或時間戳。此時兩個服務僅會使用本地事務寫入各自的資料庫并進行送出。圖7展示了這種方式,也可以稱為服務編排,或稱之為使用了良好的舊資料流水線。
最簡單的場景下,B服務會連接配接到A服務的資料庫,并讀取由A服務負責的表。業界會嘗試使用共享表來避免這種耦合,但這種情況下,任何A服務的實作變更都有可能會影響到B服務。我們可以對這種場景做稍許優化,如使用發件箱模式,給A服務配置設定一張表,作為公共接口。這張表僅包含B服務需要的内容,且易于查詢和跟蹤變更。如果還不夠好,可以讓B服務通過API管理層來查詢變更(而不通過直接連接配接A資料庫)。
從根本上講,上述方式都有相同的缺點:B服務必須要不斷輪詢A服務。這樣會導緻不必要的、持續的系統負載以及在擷取變更時的不必要的延遲。通過輪詢微服務來擷取變更并不簡單,下面看下如何來優化這種架構。
一種提升編排架構的方式是使用像Debezium這樣的工具,這樣就可以使用A資料庫的事務日志來捕獲資料變更(CDC)。圖8展示了這種方式。
Debezium可以監控資料庫的事務日志,并向一個Apache Kafka topic中投遞相關的變更。使用這種方式時,B服務隻需要監聽topic中的普通事件,而無需輪詢A服務的資料庫或使用APIs。取消使用輪詢資料庫的方式來擷取變更流,并在服務間引入隊列,使得分布式系統更可靠、可擴充,并為後續在新場景中引入新客戶提供了可能性。使用Debezium 為基于編制或編排的Sagq模式實作了發件箱模式。
這種方式的副作用是B服務可能會接收到重複的消息。可以通過在業務邏輯層實作幂等或通過去重器(如Apache ActiveMQ Artemis的消息去重探測或Apache Camel的幂等消費模式)來解決。
事件源是另一種服務編排實作。這種方式下,會使用一系列狀态變更事件來儲存一個實體的狀态。當實體更新時,不會更新實體的狀态,而會将新事件附加到事件清單中。将新事件附加到事件存儲是一個在本地事務中完成的原子操作。這種方式的好處是事件存儲的行為類似消息隊列,可以為其他服務提供事件消費的能力。
在我們的例子中,當轉為使用事件源時,需要将客戶請求存儲到一個僅支援附加的事件存儲中。A服務可以通過回放事件來修複目前狀态。事件源也需要允許B服務訂閱這些事件。使用這種機制,A服務可以将其存儲層作為與其他服務的互動層。這種方式非常簡潔,并解決了狀态變更時可靠釋出事件的問題,它引入了一種新的、很多開發者不熟悉的程式設計風格,并為狀态恢複和消息壓縮上帶來了額外的複雜度,需要特定的資料存儲。
除了用于檢索資料變更的機制,編排方式還解耦了寫操作,允許獨立擴充服務,并提升了整體系統的可靠性。這種方式的缺點是使用了去中心化的決策流,且很難發現全局的分布式狀态。如果要在大規模服務中發現查詢了多個資料源的請求狀态可能會比較困難。
表4:編排的優劣勢
1. 實作和互動解耦
2. 不需要事務協調器
3. 提升了擴充性和恢複能力
4. 近實時互動
5. 使用Debezium或類似工具時系統的開銷比較小
1. 系統的全局狀态和協調邏輯分散到了所有參與者中
2. 最終一緻性
1. Homegrown database or API polling implementations.
2. The outbox pattern
3. Choreography based on the Saga pattern
4. event sourcing
5. Eventuate
6. Debezium
7. Zendesk's Maxwell
8. Alibaba's Canal
9. Linkedin's Brooklin
10. Axon Framework
11. EventStoreDB
編排模式中沒有中心點來請求系統狀态,但服務的狀态會在分布式系統中進行傳播。編排建立了一系列用于處理服務的流水線,是以當一個消息達到一個整個流程中的特定的步驟時,說明它已經完成了前面的步驟。但如果我們解除這個限制并獨立處理所有的步驟會怎麼樣?這種場景下,B服務可能會直接處理一個請求,而不關心該請求是否已經被A服務處理。
在并行流水線中,我們增加了一個路由服務來接受請求,并在單個本地事務中通過消息代理将其轉發到A服務和B服務。從這步開始,兩個服務都可以獨立且并行處理請求。
這種模式很容易實作,它僅适用于服務之間沒有時間綁定的情況。例如,無論A服務是否處理了相同的請求,B服務都可以處理該請求。而且,這種方式需要一個額外的路由服務或一個同時了解A服務和B服務的用戶端來轉發消息。
Listen to yourself是一種輕量替代方式,其中一個服務作為路由器。使用這種替代方式,當A服務接收到一個請求時,不需要将其寫入資料庫,隻需要将該請求釋出到消息系統,最終該消息會轉發給B服務和A服務本身。圖11 展示了這種模式。
未寫入資料庫的原因是避免雙寫,一旦一個消息進入消息系統,後續會将該消息發送給B服務,且可以在一個完全隔離的事務上下文中,将消息反送給A服務。随着加處理流程的扭曲,A服務和B服務可能會獨立處理請求并寫入各自的資料庫。
表5:并行流水線的優劣勢
簡單,并行處理下的可擴充架構
需要解耦服務間的時間綁定,且難以了解到全局系統狀态
Apache Camel的multicast 和splitter(并行處理)
正如你看到的,在微服務架構中處理分布式事務時并不存在正确或錯誤的模式。每種模式都有其優劣勢。每種模式都解決了一些問題,但同時又引入了其他問題。圖12給出了上文讨論過的雙寫模式下的主要特性。
不管選擇那種方式,你需要解釋和記錄決策背後的動機以及對選擇的長期架構後果負責,還可能需要從實施和維護系統從團隊中獲得支援。圖13給出了根據其資料一緻性和可擴充性屬性得出的評估結果。
下面根據可擴充性和可用性從高到低對各種方法進行評估。
如果你的步驟暫時是解耦的,那麼可以選擇并行流水線方法來運作這些步驟。你可以在系統的某一部分(而不是整個系統)中采用這種模式。下面,假設處理步驟中存在時間耦合,且特定操作和服務必須以一定順序執行,此時你可能會考慮使用編排方式。使用服務編排,可以建立一個可擴充的、事件驅動架構,消息在去中心化的編排流程中流轉。這種場景下,可以使用Debezium 和 Apache Kafka來實作發件箱模式。
如果編排不合适,你可能需要一個中央點來負責協調和做出決策,此時可以考慮編制。這是一個比較流行的架構,可以使用标準的和自定義開源實作。但标準的實作可能會強制你使用特定的事務語義,使用自定義的編制實作可以在期望的資料一緻性和可擴充性之間進行權衡。
到這一步,說明你可能對資料一緻性有非常強的要求。在這種情況中,使用二階段送出的分布式事務可以在某些特定資料源下工作,但它們很難在(為可擴充性和高可用性設計的)動态雲環境上保證可靠性。此時,你可能會使用一體式子產品方式,這種方式保證的資料的高度一緻性,但運作時和資料源是耦合的。