kafka是一款基于釋出與訂閱的消息系統。它一般被稱為“分布式送出日志”或者“分布式流平台”。檔案系統或者資料庫送出日志用來提供所有事物的持久化記錄,通過重建這些日志可以重建系統的狀态。同樣地,kafka的資料是按照一定順序持久化儲存的,可以按需讀取。
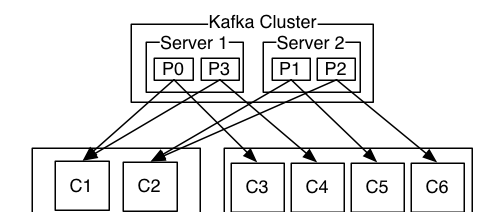
一個topic 可以配置幾個partition,produce發送的消息分發到不同的partition中,consumer接受資料的時候是按照group來接受,kafka確定每個partition隻能同一個group中的同一個consumer消費,如果想要重複消費,那麼需要其他的組來消費。Zookeerper中儲存這每個topic下的每個partition在每個group中消費的offset
新版kafka把這個offsert儲存到了一個__consumer_offsert的topic下
這個__consumer_offsert 有50個分區,通過将group的id哈希值%50的值來确定要儲存到那一個分區. 這樣也是為了考慮到zookeeper不擅長大量讀寫的原因。
是以,如果要一個group用幾個consumer來同時讀取的話,需要多線程來讀取,一個線程相當于一個consumer執行個體。當consumer的數量大于分區的數量的時候,有的consumer線程會讀取不到資料。
假設一個topic test 被groupA消費了,現在啟動另外一個新的groupB來消費test,預設test-groupB的offset不是0,而是沒有建立立,除非當test有資料的時候,groupB會收到該資料,該條資料也是第一條資料,groupB的offset也是剛初始化的ofsert, 除非用顯式的用–from-beginnging 來擷取從0開始資料
位置:zookeeper
路徑:[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics/__consumer_offsets/partitions
在zookeeper的topic中有一個特殊的topic __consumer_offserts
計算方法:(放入哪個partitions)
int hashCode = Math.abs("ttt".hashCode());
int partition = hashCode % 50;
先計算group的hashCode,再除以分區數(50),可以得到partition的值
使用指令檢視: kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition 11 --broker-list localhost:9092,localhost:9093,localhost:9094 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter"

auto.offset.reset:預設值為largest,代表最新的消息,smallest代表從最早的消息開始讀取,當consumer剛開始建立的時候沒有offset這種情況,如果設定了largest,則為當收到最新的一條消息的時候開始記錄offsert,若設定為smalert,那麼會從頭開始讀partition
Topic在邏輯上可以被認為是一個queue,每條消費都必須指定它的Topic,可以簡單了解為必須指明把這條消息放進哪個queue裡。為了使得Kafka的吞吐率可以線性提高,實體上把Topic分成一個或多個Partition,每個Partition在實體上對應一個檔案夾,該檔案夾下存儲這個Partition的所有消息和索引檔案。若建立topic1和topic2兩個topic,且分别有13個和19個分區,則整個叢集上會相應會生成共32個檔案夾(本文所用叢集共8個節點,此處topic1和topic2 replication-factor均為1),如下圖所示。
對于傳統的message queue而言,一般會删除已經被消費的消息,而Kafka叢集會保留所有的消息,無論其被消費與否。當然,因為磁盤限制,不可能永久保留所有資料(實際上也沒必要),
是以Kafka提供兩種政策删除舊資料。一是基于時間,二是基于Partition檔案大小。
例如可以通過配置$KAFKA_HOME/config/server.properties,讓Kafka删除一周前的資料,也可在Partition檔案超過1GB時删除舊資料,配置如下所示。
這裡要注意,因為Kafka讀取特定消息的時間複雜度為O(1),即與檔案大小無關,是以這裡删除過期檔案與提高Kafka性能無關。選擇怎樣的删除政策隻與磁盤以及具體的需求有關。另外,Kafka會為每一個Consumer Group保留一些metadata資訊——目前消費的消息的position,也即offset。這個offset由Consumer控制。正常情況下Consumer會在消費完一條消息後遞增該offset。當然,Consumer也可将offset設成一個較小的值,重新消費一些消息。因為offet由Consumer控制,是以Kafka broker是無狀态的,它不需要标記哪些消息被哪些消費過,也不需要通過broker去保證同一個Consumer Group隻有一個Consumer能消費某一條消息,是以也就不需要鎖機制,這也為Kafka的高吞吐率提供了有力保障。
Producer發送消息到broker時,會根據Paritition機制選擇将其存儲到哪一個Partition。如果Partition機制設定合理,所有消息可以均勻分布到不同的Partition裡,這樣就實作了負載均衡。如果一個Topic對應一個檔案,那這個檔案所在的機器I/O将會成為這個Topic的性能瓶頸,而有了Partition後,不同的消息可以并行寫入不同broker的不同Partition裡,極大的提高了吞吐率。可以在$KAFKA_HOME/config/server.properties中通過配置項num.partitions來指定建立Topic的預設Partition數量,也可在建立Topic時通過參數指定,同時也可以在Topic建立之後通過Kafka提供的工具修改。
在發送一條消息時,可以指定這條消息的key,Producer根據這個key和Partition機制來判斷應該将這條消息發送到哪個Parition。Paritition機制可以通過指定Producer的paritition. class這一參數來指定,該class必須實作kafka.producer.Partitioner接口。本例中如果key可以被解析為整數則将對應的整數與Partition總數取餘,該消息會被發送到該數對應的Partition。(每個Parition都會有個序号,序号從0開始)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<code>import</code> <code>kafka.producer.Partitioner;</code>
<code>import</code> <code>kafka.utils.VerifiableProperties;</code>
<code>public</code> <code>class</code> <code>JasonPartitioner<T> </code><code>implements</code> <code>Partitioner {</code>
<code> </code><code>public</code> <code>JasonPartitioner(VerifiableProperties verifiableProperties) {}</code>
<code> </code><code>@Override</code>
<code> </code><code>public</code> <code>int</code> <code>partition(Object key, </code><code>int</code> <code>numPartitions) {</code>
<code> </code><code>try</code> <code>{</code>
<code> </code><code>int</code> <code>partitionNum = Integer.parseInt((String) key);</code>
<code> </code><code>return</code> <code>Math.abs(Integer.parseInt((String) key) % numPartitions);</code>
<code> </code><code>} </code><code>catch</code> <code>(Exception e) {</code>
<code> </code><code>return</code> <code>Math.abs(key.hashCode() % numPartitions);</code>
<code> </code><code>}</code>
<code> </code><code>}</code>
<code>}</code>
如果将上例中的類作為partition.class,并通過如下代碼發送20條消息(key分别為0,1,2,3)至topic3(包含4個Partition)。
<code>public</code> <code>void</code> <code>sendMessage() </code><code>throws</code> <code>InterruptedException{</code>
<code> </code><code>for</code><code>(</code><code>int</code> <code>i = </code><code>1</code><code>; i <= </code><code>5</code><code>; i++){</code>
<code> List messageList = </code><code>new</code> <code>ArrayList<KeyedMessage<String, String>>();</code>
<code> </code><code>for</code><code>(</code><code>int</code> <code>j = </code><code>0</code><code>; j < </code><code>4</code><code>; j++){</code>
<code> messageList.add(</code><code>new</code> <code>KeyedMessage<String, String>(</code><code>"topic2"</code><code>, j+</code><code>""</code><code>, </code><code>"The "</code> <code>+ i + </code><code>" message for key "</code> <code>+ j));</code>
<code> }</code>
<code> producer.send(messageList);</code>
<code> producer.close();</code>
則key相同的消息會被發送并存儲到同一個partition裡,而且key的序号正好和Partition序号相同。(Partition序号從0開始,本例中的key也從0開始)。下圖所示是通過Java程式調用Consumer後列印出的消息清單。
本節所有描述都是基于Consumer hight level API而非low level API。
使用Consumer high level API時,同一Topic的一條消息隻能被同一個Consumer Group内的一個Consumer消費,但多個Consumer Group可同時消費這一消息。
這是Kafka用來實作一個Topic消息的廣播(發給所有的Consumer)和單點傳播(發給某一個Consumer)的手段。一個Topic可以對應多個Consumer Group。如果需要實作廣播,隻要每個Consumer有一個獨立的Group就可以了。要實作單點傳播隻要所有的Consumer在同一個Group裡。用Consumer Group還可以将Consumer進行自由的分組而不需要多次發送消息到不同的Topic。
實際上,Kafka的設計理念之一就是同時提供離線處理和實時處理。根據這一特性,可以使用Storm這種實時流處理系統對消息進行實時線上處理,同時使用Hadoop這種批處理系統進行離線處理,還可以同時将資料實時備份到另一個資料中心,隻需要保證這三個操作所使用的Consumer屬于不同的Consumer Group即可。
下面這個例子更清晰地展示了Kafka Consumer Group的特性。
首先建立一個Topic (名為topic1,包含3個Partition),
然後建立一個屬于group1的Consumer執行個體,并建立三個屬于group2的Consumer執行個體,
最後通過Producer向topic1發送key分别為1,2,3的消息。
結果發現屬于group1的Consumer收到了所有的這三條消息,同時group2中的3個Consumer分别收到了key為1,2,3的消息。
文章參考:
https://blog.csdn.net/weixin_38004638/article/details/90231607
https://www.cnblogs.com/liuwei6/p/6900686.html