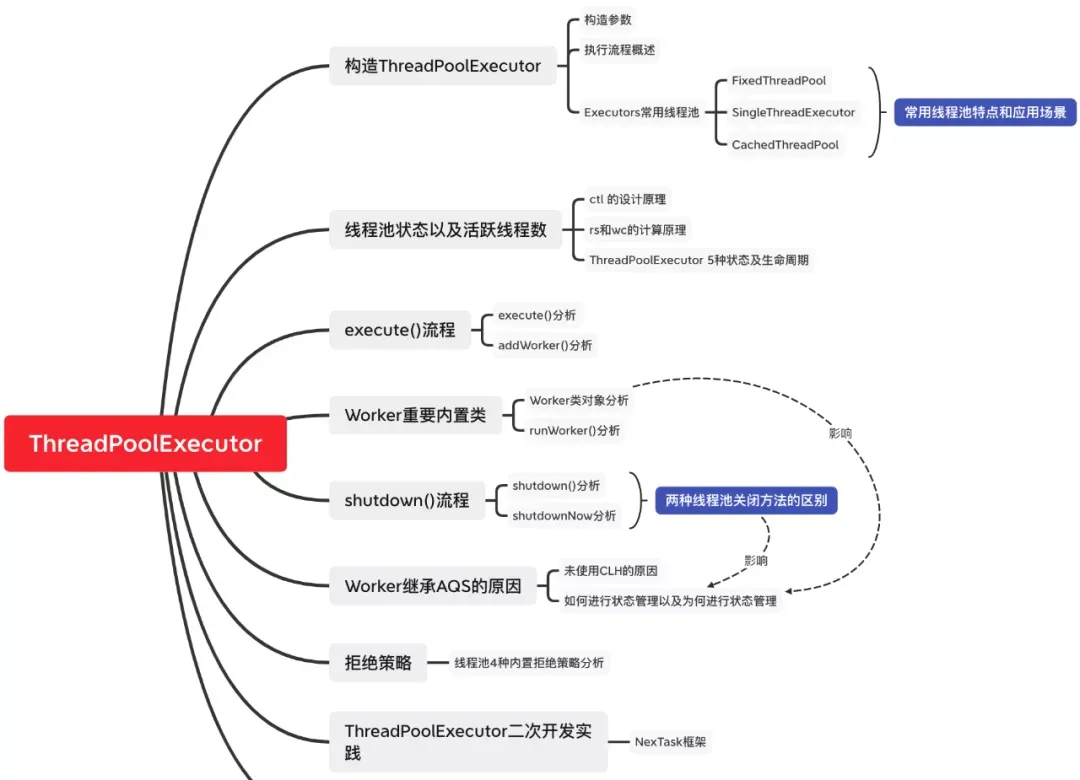
本文内容主要圍繞JDK中的ThreadPoolExecutor展開,首先描述了ThreadPoolExecutor的構造流程以及内部狀态管理的機理,随後用大量篇幅深入源碼探究了ThreadPoolExecutor線程配置設定、任務處理、拒絕政策、啟動停止等過程,其中對Worker内置類進行重點分析。
本文内容主要圍繞JDK中的ThreadPoolExecutor展開,首先描述了ThreadPoolExecutor的構造流程以及内部狀态管理的機理,随後用大量篇幅深入源碼探究了ThreadPoolExecutor線程配置設定、任務處理、拒絕政策、啟動停止等過程,其中對Worker内置類進行重點分析,内容不僅包含其工作原理,更對其設計思路進行了一定分析。文章内容既包含了源碼流程分析,還具有設計思路探讨和二次開發實踐。
大家可以通過如下構造方法建立線程池(其實還有其它構造器,大家可以深入源碼進行檢視,但最終都是調用下面的構造器建立線程池);
其中的構造參數的作用如下:
corePoolSize:核心線程數。送出任務時,當線程池中的線程數 小于 corePoolSize 時,會 新 建立一個核心線程執行任務。當線程數 等于 corePoolSize 時,會将任務 添加進任務隊列。
maximumPoolSize:最大線程數。送出任務時,當 任務隊列已滿 并且線程池中的總線程數 不大于 maximumPoolSize 時,線程池會令非核心線程執行送出的任務。當 大于 maximumPoolSize 時,會執行拒絕政策。
keepAliveTime:非核心線程 空閑時 的存活時間。
unit:keepAliveTime 的機關。
workQueue:任務隊列(阻塞隊列)。
threadFactory:線程工廠。線程池用來新建立線程的工廠類。
handler:拒絕政策,線程池遇到無法處理的情況時會執行該拒絕政策選擇抛棄或忽略任務等。
由構造參數的作用我們可知,線程池中由幾個重要的元件:核心線程池 、** 空閑(非核心)線程池** 和 阻塞隊列。這裡首先給出線程池的核心執行流程圖,大家首先對其有個印象,之後分析源碼就會輕松一些了。
下面對流程圖中一些注釋說明下:cap表示池的容量,size表示池中正在運作的線程數。對于阻塞隊列來說,cap表示隊列容量,size表示已經入隊的任務數量。cpS<cpc表示運作中的核心線程數小于線程池設定核心線程數的情況。

1)當核心線程池 未 “滿” 時,會建立新的核心線程執行送出的任務。這裡的 “滿” 指的是核心線程池中的數量(size)小于容量(cap),此時會通過線程工廠新建立線程執行送出任務。
2)當核心線程池 已 “滿” 時,會将送出的任務push進任務隊列中,等待核心線程的釋放。一旦核心線程釋放後,将會從任務隊列中pull task繼續執行。因為使用的是阻塞隊列,對于已經釋放的核心線程,也會阻塞在擷取任務的過程中。
3)當任務隊列也滿了時(這裡的滿是指真的滿了,當然暫不考慮無界隊列情況),會從空閑線程池中繼續建立線程執行送出的任務。但空閑線程池中的線程是有存活時間(keepAliveTime)的,當線程執行完任務後,隻能存活 keepAliveTime 時長,時間一過,線程就得被銷毀。
4)當空閑線程池的線程數不斷增加,直到ThreadPoolExecutor中的總線程數大于 maximumPoolSize 時,會拒絕執行任務,将送出的任務交給 RejectedExecutionHandler 進行後續處理。
上面所說的核心線程池和空閑線程池隻是抽象出來的一個概念,後面我們将對其具體内容進行分析。
在進入 ThreadPoolExecutor 的源碼分析前,我們先介紹下常用的線程池(其實并不常用,隻是JDK自帶了)。這些線程池可由 Executors 這個工具類(或叫線程池工廠)來建立。
固定線程數線程池的建立方式如下:其中核心線程數與最大線程數固定且相等,采用以連結清單為底層結構的無界阻塞隊列。
特點:
核心線程數與最大線程數相等,是以不會建立空閑線程。keepAliveTime 設定與否無關緊要。
采用無界隊列,任務會被無限添加,直至記憶體溢出(OOM)。
由于無界隊列不可能被占滿,任務在執行前不可能被拒絕(前提是線程池一直處于運作狀态)。
應用場景:
适用于線程數固定的場景
适用負載比較重的伺服器
單線程線程池的建立方式如下:其中核心線程數與最大線程數都為1,采用以連結清單為底層結構的無界阻塞隊列。
特點
與 FixedThreadPool 類似,隻是線程數為1而已。
應用場景
适用單線程的場景。
适用于對送出任務的處理有順序性要求的場景。
緩沖線程池的建立方式如下:其中核心線程數為0,最大線程數為Integer.MAX_VALUE(可以了解為無窮大)。采用同步阻塞隊列。
核心線程數為0,則初始就建立空閑線程,并且空閑線程的隻能等待任務60s,60s内沒有送出任務,空閑線程将被銷毀。
最大線程數為無窮大,這樣會造成巨量線程同時運作,CPU負載過高,導緻應用崩潰。
采用同步阻塞隊列,即隊列不存儲任務。送出一個消費一個。由于最大線程數為無窮大,是以,隻要送出任務就一定會被消費(應用未崩潰前)。
适用于耗時短、異步的小程式。
适用于負載較輕的伺服器。
ThreadPoolExecutor 中有兩個非常重要的參數:**線程池狀态 **(rs) 以及 活躍線程數(wc)。前者用于辨別目前線程池的狀态,并根據狀态量來控制線程池應該做什麼;後者用于辨別活躍線程數,根據數量控制應該在核心線程池還是空閑線程池建立線程。
ThreadPoolExecutor 用一個 Integer 變量(ctl)來設定這兩個參數。我們知道,在不同作業系統下,Java 中的 Integer 變量都是32位,ThreadPoolExecutor 使用前3位(3129)表示線程池狀态,用後29位(280)表示活躍線程數。
這樣設定的目的是什麼呢?
我們知道,在并發場景中同時維護兩個變量的代價是非常大的,往往需要進行加鎖來保證兩個變量的變化是原子性的。而将兩個參數用一個變量維護,便隻需一條語句就能保證兩個變量的原子性。這種方式大大降低了使用過程中的并發問題。
有了上面的概念,我們從源碼層面看看 ThreadPoolExecutor 的幾種狀态,以及 ThreadPoolExecutor 如何同時操作狀态和活躍線程數這兩個參數的。
ThreadPoolExecutor 關于狀态初始化的源碼如下:
ThreadPoolExecutor 使用原子 Integer 定義了 ctl 變量。ctl 在一個int中包裝了活躍線程數和線程池運作時狀态兩個變量。為了達到這樣的目的,ThreadPoolExecutor 的線程數被限制在 2^29-1(大約500 million)個,而不是 2^31-1(2 billion)個,因為前3位被用于辨別 ThreadPoolExecutor 的狀态。如果未來 ThreadPoolExecutor 中的線程數不夠用了,可以把 ctl 設定為原子 long 類型,再調整下相應的掩碼就行了。
COUNT_BITS 概念上用于表示狀态位與線程數位的分界值,實際用于狀态變量等移位操作。此處為 Integer.sixze-3=32-3=29。
CAPACITY 表示 ThreadPoolExecutor 的最大容量。由下圖可以看出,經過移位操作後,一個int值的後29位達到最大值:全為1。這29位表示活躍線程數,全為1時表明達到 ThreadPoolExecutor 能容納的最大線程數。前3位為0,表示該變量隻與活躍線程數相關,與狀态無關。這也是為了便于後續的位操作。
RUNNING、SHUTDOWN、STOP、TIDYING、TERMINATED 表示 ThreadPoolExecutor 的5個狀态。這5個狀态對應的可執行操作如下:
RUNNING:可接收新任務,可持續處理阻塞隊列中的任務。 SHUTDOWN:不可接收新任務,可繼續處理阻塞隊列中的任務。 STOP:不可接收新任務,中斷阻塞隊列中所有任務。 TIDYING:所有任務直接終止,所有線程清空。 TERMINATED:線程池關閉。
這5個狀态的計算過程如下圖所示,經過移位計算後,數值的後29位全為0,前3位分别代表不同的狀态。
經過以上的變量定義後,ThreadPoolExecutor 将狀态與線程數分離,分别設定再一個int值的不同連續位上,這也為下面的操作帶來了極大的便利。
接下來我們來看看 ThreadPoolExecutor 是如何擷取狀态和線程數的。
runStateOf() 方法是用于擷取線程池狀态的方法。其中形參 c 一般是 ctl 變量,包含了狀态和線程數,runStateOf()移位計算的過程如下圖所示。
CAPACITY 取反後高三位置1,低29位置0。取反後的值與 ctl 進行 ‘與’ 操作。由于任何值 ‘與’ 1等于原值,‘與’ 0等于0。是以 ‘與’ 操作過後,ctl 的高3位保留原值,低29位置0。這樣就将狀态值從 ctl 中分離出來。
workerCountOf(c) 方法的分析思路與上述類似,就是把後29位從ctl中分離出來,獲得活躍線程數。如下圖所示,這裡就不再贅述。
ctlOf(rs, wc)通過狀态值和線程數值計算出 ctl 值。rs是runState的縮寫,wc是workerCount的縮寫。rs的後29位為0,wc的前三位為0,兩者通過 ‘或’ 操作計算出來的最終值同時保留了rs的前3位和wc的後29位,即 ctl 值。
ThreadPoolExecutor 中還有一些其它操作 ctl 的方法,分析思路與上面都大同小異,大家有興趣可以自己看看。
本小結最後再來看看 ThreadPoolExecutor 狀态轉換的途徑,也可以了解為生命周期。
execute() 源碼如下所示:
源碼分析直接看注釋就行了,每一行都有,灰常灰常的詳細了。
從源碼中可以看到,execute() 方法主要封裝了 ThreadPoolExecutor 建立線程的判斷邏輯,核心線程和空閑線程的建立時機,拒絕政策的執行時機都在該方法進行判斷。這裡通過下面的流程圖對上述源碼進行總結下。
通過建立線程去執行送出的任務邏輯封裝在 addWorker() 方法中。下一小節我們将來分析執行送出任務的具體邏輯。execute() 方法中還有幾個方法這裡說明下。
從 ctl 中擷取活躍線程數,在第二小節已經介紹過了。
依據 ctl 的值判斷 ThreadPoolExecutor 是否運作狀态。源碼中直接判斷 ctl < SHUTDOWN 是否成立,這是因為運作狀态下的 ctl 最高位為1,肯定是負數;而其它狀态最高位為0,肯定是正數。是以判斷 ctl 的大小即可判斷是否為運作态。
3.1.3 reject()
直接調用初始化時的 RejectedExecutionHandler 接口的 rejectedExecution() 方法。這也是典型的政策模式的使用,真正的拒絕操作被封裝在實作了 RejectedExecutionHandler 接口的實作類中。這裡就不進行展開。
addWorker()源碼分析如下:
addWorker() 通過内外兩層死循環判斷 ThreadPoolExecutor 運作狀态并通過CAS成功更新活躍線程數。這是為了保證線程池中的多個線程在并發環境下都能夠按照預期的條件退出循環。
随後方法會 new 一個 Worker 并啟動 Worker 内置的工作線程。這裡通過workerAdded和workerStarted兩個狀态判斷 Worker 是否被成功緩存與啟動。
修改 workerAdded 過程會使用 ThreadPoolExecutor 的 mainlock 上鎖保證原子性,防止多線程并發環境下, 向workers中添加資料以及擷取workers數量這兩個過程出現預期之外的情況。
addWorker() 啟動worker線程的步驟是先new一個Worker對象,然後從中擷取工作線程,再start,是以真正的線程啟動過程還是在Worker對象中。
這裡通過一張流程圖對addWorker總結下:
addWorker 還有幾個方法也在這裡分析下:
從 ctl 中擷取 ThreadPoolExecutor 狀态,詳細分析看第二章。
從 ctl 中擷取 ThreadPoolExecutor 活躍線程數,詳細分析看第二章。
通過CAS的方式令 ctl 中活躍線程數+1。這裡為什麼隻要讓 ctl 的值+1就能更改線程數了呢?因為 ctl 線程數的值存儲在後29位中,在不溢出的情況下,+1隻會影響後29位的數值,隻會令線程數+1。而不影響線程池狀态。
4.2.4 addWorkerFailed()
該方法是在工作線程啟動失敗後執行的方法。什麼情況下會出現這種問題呢?在成功增加活躍線程數後并成功new Worker後,線程池狀态改變為 > SHUTDOWN,既不可接受新任務,又不能執行任務隊列剩餘的任務,此時線程池應該直接停止。
該方法就是在這種情況下:
從workers緩存池中移除新建立的Worker;
通過死循環+CAS確定活躍線程數減1;
執行tryTerminate() 方法,嘗試停止線程池。
執行完 tryTerminate() 方法後,線程池将會進入到 TERMINATED狀态。
Worker對象的源碼分析:
從上面源碼可以看出:Worker實作了Runnable接口,說明Worker是一個任務;Worker又繼承了AQS,說明Worker同時具有鎖的性質,但Worker并沒有像ReentrantLock等鎖工具使用了CLH的功能,因為線程池中并不存在多個線程通路同一個Worker的場景,這裡隻是使用了AQS中狀态維護的功能,這個具體會在下面進行詳細說明。
每個Worker對象會持有一個工作線程 thread,在Worker初始化時,通過線程工廠建立該工作線程并将自己作為任務傳入工作線程當中。是以,線程池中任務的運作其實并不是直接執行送出任務的run()方法,而是執行Worker中的run()方法,在該方法中再執行送出任務的run()方法。
Worker 中的 run() 方法是委托給 ThreadPoolExecutor 中的 runWorker() 執行具體邏輯。
這裡用一張圖總結下:
Worker本身是一個任務,并且持有使用者送出的任務和工作線程。
工作線程持有的任務是this本身,是以調用工作線程的start()方法其實是執行this本身的run()方法。
this本身的run()委托全局的runWorker()方法執行具體邏輯。
runWorker()方法中執行使用者送出任務的run()方法,執行使用者具體邏輯。
runWorker() 源碼如下所示:
runWorker() 是真正執行送出任務的方法,但其并沒有通過Thread.start()方法執行任務,而是直接執行任務的run()方法。
runWorker() 會從任務隊列中不斷擷取任務并執行。
runWorker() 提供了兩個鈎子函數,如果 jdk 的 ThreadPoolExecutor 無法滿足開發人員的需求,開發人員可以繼承 ThreadPoolExecutor并重寫beforeExecute()和afterExecute()方法定制任務執行前需要執行的邏輯。比如設定一些監控名額或者列印日志等。
線程池擁有兩個主動關閉的方法;
shutdown():關閉線程池中所有空閑Worker線程,改變線程池狀态為SHUTDOWN; shutdownNow():關閉線程池中所有Worker線程,改變線程池狀态為STOP,并傳回所有正在等待處理的任務清單。
這裡為什麼要将Worker線程區分為空閑和非空閑呢?
由上面的 runWorker() 方法,我們知道Worker線程在理想情況下會在while循環中不斷從任務隊列中擷取任務并執行,此時的Worker線程就是非空閑的;沒有在執行任務的worker線程則是空閑的。因為線程池的SHUTDOWN狀态不允許接收新任務,隻允許執行任務隊列中剩餘的任務,是以需要中斷所有空閑的Worker線程,非空閑線程則持續執行任務隊列的任務,直至隊列為空。而線程池的STOP狀态既不允許接受新任務,也不允許執行剩餘的任務,是以需要關閉所有Worker線程,包括正在運作的。
shutdown() 源碼如下:
shutdown() 将 ThreadPoolExecutor 的關閉步驟封裝在幾個方法中,并且通過全局鎖保證隻有一個線程能主動關閉 ThreadPoolExecutor。ThreadPoolExecutor 同樣提供了一個鈎子函數 onShutdown() 讓開發人員定制化關閉過程。比如ScheduledThreadPoolExecutor 就會在關閉時對任務隊列進行清理。
下面對其中的方法進行分析。
checkShutdownAccess()
advanceRunState()
該方法中判斷線目前程池狀态 >= SHUTDOWN 是否成立其實也是用到了之前線程池狀态定義的技巧。對于非運作狀态的其它狀态都為正數,且高三位都不同,TERMINATED(011) > TIDYING(010) > STOP(001) > SHUTDOWN(000)而高三位的大小取決了整個數的大小。是以對于不同狀态,無論活躍線程數是多少,線程池的狀态始終決定着 ctl 值的大小。即TERMINATED 狀态下的 ctl 值 > TIDYING 狀态下的 ctl 值恒成立。
interruptIdleWorkers()
剛方法會嘗試擷取Worker的鎖,隻有擷取成功的情況下才會中斷線程。這裡也與前面說的Worker雖然繼承了AQS但卻沒使用CLH有關,後面會進行分析。
tryTerminate() 方法已經在前面分析過了,這裡不過多叙述。
該方法與 shutdown() 比較相似,都将核心步驟封裝在了幾個方法中,其中 checkShutdownAccess() 和 advanceRunState() 相同。下面對不同的方法進行說明
interruptWorkers()
該方法并沒有嘗試去擷取Worker的鎖,而是直接中斷線程。因為STOP狀态下的線程池不允許處理任務隊列中正在等待的任務。
drainQueue()
首先說結論——Worker繼承AQS是為了使用其中狀态管理的功能,并沒有像ReentrantLock使用AQS中CLH的性質。
我們先來看看Worker中與AQS相關的方法:
Worker中的tryAcquire隻是将狀态改為1,而參數未被使用,是以我們可以斷定,Worker中的狀态可能取值為(0, 1)。這裡沒有考慮初始化狀态-1是避免出現混淆。
再看 lock() 方法,lock() 方法被調用的唯一位置就是在 runWorker() 中啟動worker線程前。而 runWorker() 是通過 Worker 中的 run() 調用的。Worker 作為任務隻被傳遞給本身持有的工作線程中,是以 Worker 中的 run() 方法隻能被本身持有的工作線程通過 start() 調用,是以 runWorker() 隻會被 Worker 本身持有的工作線程所調用,lock() 方法也隻會被單線程調用,不存在多個線程競争同一把鎖的情況,也就不存在多線程環境下,隻有一個線程能獲得鎖導緻其他等待線程被添加進CLH隊列的情況。是以 Worker 并沒沒有使用CLH的功能。
這也就很好說明了 tryAcquire() 方法并沒有使用傳遞的參數,因為Worker隻存在兩種狀态,要麼被上鎖(非空閑,state=1),要麼未被上鎖(空閑,state=0)。無需通過傳遞參數設定其他的狀态。
以上分析說明了 Worker 沒有使用 AQS 的 CLH 功能。那麼 Worker 是如何使用狀态管理的功能的呢?
在關閉線程池的 shutdown() 方法中,有一個步驟是中斷所有的空閑 Worker 線程。而在中斷所有 Worker 線程前會判斷 Worker 線程是否能被擷取到鎖,通過 tryLock() -> tryAcquire() 判斷 Worker 的狀态是否為0,隻有能夠擷取到鎖的 Worker 才會被中斷,而能被擷取到鎖的 Worker 即為空閑 Worker(state=0)。而不能被擷取到鎖的 Worker 表名已經執行過 lock() 方法了,此時 Worker 在 While 循環不斷擷取阻塞隊列的任務執行,在shutdown()方法中不能被中斷。
是以 Worker 的狀态管理其實是通過 state 的值(0 或 1)判斷 Worker 是否為空閑的,如果是空閑的,則可以線上程池關閉時被中斷掉,否則得一直在while循環中擷取阻塞隊列中的任務并執行,直至隊列中任務為空後才被釋放。如下圖所示:
本章隻讨論 ThreadPoolExecutor 内置的四個拒絕政策 handler。
直接在調用線程中執行被拒絕的任務。隻要線程池為 RUNNING 狀态,任務仍被執行。如果為非 RUNNING 狀态,任務将直接被忽略,這也符合線程池狀态的行為。
任務被拒絕後直接抛出拒絕異常。
抛棄該任務。拒絕方法為空,表示什麼都不執行,等同于将任務抛棄。
移除阻塞隊列中最早進入隊列中(隊頭)的任務,然後再次嘗試執行execute()方法,将目前任務入隊。這是典型的喜新厭舊的政策。
介紹完了 ThreadPoolExecutor 的核心原理,我們來看看 vivo 自研的 NexTask 并發架構是如何玩轉線程池并提升業務人員的開發速度和代碼執行速度。
NexTask 對業務常用模式、算法、場景進行抽象化,以元件的形式落地。它提供了一個快速、輕量級、簡單易用并且屏蔽了底層技術細節的方式,能夠讓開發人員快速編寫并發程式,更大程度上為開發賦能。
首先給出 NexTask 架構圖,然後我們針對架構圖中使用到了 ThreadPoolExecutor 的地方進行詳細分析。
Executor 是對外提供的接口,開發人員可以使用它具備的簡單易用的API,快速通過任務管理器 TaskProcessManager 建立任務處理器 TaskProcess。
TaskProcessManager 持有一個 ConcurrentHashMap 本地緩存有所的任務處理器,每個任務處理器與特定的業務名稱一一映射。在擷取任務處理器時,通過具體的業務名稱從緩存中擷取,不僅能夠保證各個業務間的任務處理互相隔離,同時能夠防止多次建立、銷毀線程池造成的資源損耗。
每個TaskProcess都持有一個線程池,由線程池的初始化過程可以看到,TaskProcess 采用的是有界阻塞隊列,隊列中最多存放2048個任務,一旦超過這個數量後,将會直接拒絕接收任務并抛出拒絕處理異常。
TaskProcess 會周遊使用者送出的任務清單,并通過 submit() 方法将其送出至線程池處理,submit() 底層其實還是調用的 ThreadPoolExecutor#execute() 方法,隻不過會在調用前将任務封裝成 RunnableFuture,這裡就是FutureTask架構的内容了,就不進行展開。
TaskProcess會在每次處理任務時,建立一個 CountDownLatch,并在任務結束後執行 CountDownLatch.countDown(),這樣就能保證所有任務在執行完成阻塞目前線程,直至所有任務處理完後統一擷取結果并傳回。
JDK雖然為開發人員提供了Executors工具類以及内置的多種線程池,但那些線程池的使用非常局限,無法滿足日益複雜的業務場景。阿裡官方的程式設計規約中也推薦開發人員不要直接使用JDK自帶的線程池,而是根據自身業務場景通過ThreadPoolExecutor進行建立線程池。是以,了解ThreadPoolExecutor内部原理對日常開發中熟練使用線程池也是至關重要的。
本文主要是對ThreadPoolExecutor内部核心原理進行探究,介紹了其構造方法及其各個構造參數的詳細意義,以及線程池核心 ctl 參數的轉化方法。随後花了大量篇幅深入ThreadPoolExecutor源碼介紹線程池的啟動與關閉流程、核心内置類Worker等。ThreadPoolExecutor還有其他方法本文暫未介紹,讀者可以在讀完本文的基礎上自行閱讀其他源碼,相信會有一定幫助。
作者:vivo網際網路伺服器團隊-Xu Weiteng
分享 vivo 網際網路技術幹貨與沙龍活動,推薦最新行業動态與熱門會議。