我們可以用redis-trib.rb fix 來修複叢集/redis-3.0.1/src/redis-trib.rb fix 127.0.0.1:7000 ,如果還是啟動不了的話,可以把相關的cluster-config-file節點同步資訊删掉。
節點
CLUSTER MEET <ip> <port> 将 ip 和 port 所指定的節點添加到叢集當中,讓它成為叢集的一份子。
CLUSTER FORGET <node_id> 從叢集中移除 node_id 指定的節點。
CLUSTER REPLICATE <node_id> 将目前節點設定為 node_id 指定的節點的從節點。
CLUSTER SAVECONFIG 将節點的配置檔案儲存到硬碟裡面。
槽(slot)
CLUSTER ADDSLOTS <slot> [slot ...] 将一個或多個槽(slot)指派(assign)給目前節點。
CLUSTER DELSLOTS <slot> [slot ...] 移除一個或多個槽對目前節點的指派。
CLUSTER FLUSHSLOTS 移除指派給目前節點的所有槽,讓目前節點變成一個沒有指派任何槽的節點。
CLUSTER SETSLOT <slot> NODE <node_id> 将槽 slot 指派給 node_id 指定的節點,如果槽已經指派給另一個節點,那麼先讓另一個節點删除該槽>,然後再進行指派。
CLUSTER SETSLOT <slot> MIGRATING <node_id> 将本節點的槽 slot 遷移到 node_id 指定的節點中。
CLUSTER SETSLOT <slot> IMPORTING <node_id> 從 node_id 指定的節點中導入槽 slot 到本節點。
CLUSTER SETSLOT <slot> STABLE 取消對槽 slot 的導入(import)或者遷移(migrate)。
鍵
CLUSTER KEYSLOT <key> 計算鍵 key 應該被放置在哪個槽上。
CLUSTER COUNTKEYSINSLOT <slot> 傳回槽 slot 目前包含的鍵值對數量。
CLUSTER GETKEYSINSLOT <slot> <count> 傳回 count 個 slot 槽中的鍵。
單機指令
1. KEYS/RENAME/DEL/EXISTS/MOVE/RENAMENX:
flushdb
set mykey 2
sadd mysetkey 1 2 3
hset mmtest username "stephen"
keys my*
del mykey mykey2
#将目前資料庫中的mysetkey鍵移入到ID為1的資料庫中,從結果可以看出已經移動成功
move mysetkey 1
select 1
renamenx oldkey newkey
2. PERSIST/EXPIRE/EXPIREAT/TTL:
3. TYPE/RANDOMKEY/SORT:
<a href="http://blog.csdn.net/u010258235/article/details/50060127" target="_blank">http://blog.csdn.net/u010258235/article/details/50060127</a>
很全面,配置也有提到
鍵分布模型?
Redis 叢集的鍵空間被分割為 16384 個槽(slot),叢集的最大節點數量也是 16384 個。
重配置指的是将某個/某些槽從一個節點移動到另一個節點。
節點握手(已實作)?
MOVED 轉向?
如果該指令是叢集可以執行的指令,那麼節點會查找這個指令所要處理的鍵所在的槽。
叢集線上重配置(live reconfiguration)
Redis 叢集支援在叢集運作的過程中添加或者移除節點。
實際上,節點的添加操作和節點的删除操作可以抽象成同一個操作,那就是,将哈希槽從一個節點移動到另一個節點:
添加一個新節點到叢集,等于将其他已存在節點的槽移動到一個空白的新節點裡面。
從叢集中移除一個節點,等于将被移除節點的所有槽移動到叢集的其他節點上面去。
要了解 Redis 叢集如何将槽從一個節點移動到另一個節點,我們需要對 CLUSTER 指令的各個子指令進行介紹,這些命理負責管理叢集節點的槽轉換表(slots translation table)。
以下是 CLUSTER 指令可用的子指令:
CLUSTER ADDSLOTS slot1 [slot2] ... [slotN]
CLUSTER DELSLOTS slot1 [slot2] ... [slotN]
CLUSTER SETSLOT slot NODE node
CLUSTER SETSLOT slot MIGRATING node
CLUSTER SETSLOT slot IMPORTING node
最開頭的兩條指令 ADDSLOTS 和 DELSLOTS 分别用于向節點指派(assign)或者移除節點,當槽被指派或者移除之後,節點會将這一資訊通過 Gossip 協定傳播到整個叢集。 ADDSLOTS 指令通常在新建立叢集時,作為一種快速地将各個槽指派給各個節點的手段來使用。
CLUSTER SETSLOT slot NODE node 子指令可以将指定的槽 slot 指派給節點 node 。
至于 CLUSTER SETSLOT slot MIGRATING node 指令和 CLUSTER SETSLOT slot IMPORTING node 指令,前者用于将給定節點 node 中的槽 slot 遷移出節點,而後者用于将給定槽 slot 導入到節點 node :
當一個槽被設定為 MIGRATING 狀态時,原來持有這個槽的節點仍然會繼續接受關于這個槽的指令請求,但隻有指令所處理的鍵仍然存在于節點時,節點才會處理這個指令請求。
如果指令所使用的鍵不存在與該節點,那麼節點将向用戶端傳回一個 -ASK 轉向(redirection)錯誤,告知用戶端,要将指令請求發送到槽的遷移目标節點。
當一個槽被設定為 IMPORTING 狀态時,節點僅在接收到 ASKING 指令之後,才會接受關于這個槽的指令請求。
如果用戶端沒有向節點發送 ASKING 指令,那麼節點會使用 -MOVED 轉向錯誤将指令請求轉向至真正負責處理這個槽的節點。
上面關于 MIGRATING 和 IMPORTING 的說明有些難懂,讓我們用一個實際的執行個體來說明一下。
假設現在,我們有 A 和 B 兩個節點,并且我們想将槽 8 從節點 A 移動到節點 B ,于是我們:
向節點 B 發送指令 CLUSTER SETSLOT 8 IMPORTING A
向節點 A 發送指令 CLUSTER SETSLOT 8 MIGRATING B
每當用戶端向其他節點發送關于哈希槽 8 的指令請求時,這些節點都會向用戶端傳回指向節點 A 的轉向資訊:
如果指令要處理的鍵已經存在于槽 8 裡面,那麼這個指令将由節點 A 處理。
如果指令要處理的鍵未存在于槽 8 裡面(比如說,要向槽添加一個新的鍵),那麼這個指令由節點 B 處理。
這種機制将使得節點 A 不再建立關于槽 8 的任何新鍵。
與此同時,一個特殊的用戶端 redis-trib 以及 Redis 叢集配置程式(configuration utility)會将節點 A 中槽 8 裡面的鍵移動到節點 B 。
鍵的移動操作由以下兩個指令執行:
CLUSTER GETKEYSINSLOT slot count
上面的指令會讓節點傳回 count 個 slot 槽中的鍵,對于指令所傳回的每個鍵, redis-trib 都會向節點 A 發送一條 MIGRATE 指令,該指令會将所指定的鍵原子地(atomic)從節點 A 移動到節點 B (在移動鍵期間,兩個節點都會處于阻塞狀态,以免出現競争條件)。
以下為 MIGRATE 指令的運作原理:
MIGRATE target_host target_port key target_database id timeout
執行 MIGRATE 指令的節點會連接配接到 target 節點,并将序列化後的 key 資料發送給 target ,一旦 target 傳回 OK ,節點就将自己的 key 從資料庫中删除。
從一個外部用戶端的視角來看,在某個時間點上,鍵 key 要麼存在于節點 A ,要麼存在于節點 B ,但不會同時存在于節點 A 和節點 B 。
因為 Redis 叢集隻使用 0 号資料庫,是以當 MIGRATE 指令被用于執行叢集操作時, target_database 的值總是 0 。
target_database 參數的存在是為了讓 MIGRATE 指令成為一個通用指令,進而可以作用于叢集以外的其他功能。
我們對 MIGRATE 指令做了優化,使得它即使在傳輸包含多個元素的清單鍵這樣的複雜資料時,也可以保持高效。
不過,盡管 MIGRATE 非常高效,對一個鍵非常多、并且鍵的資料量非常大的叢集來說,叢集重配置還是會占用大量的時間,可能會導緻叢集沒辦法适應那些對于響應時間有嚴格要求的應用程式。
ASK 轉向?
在之前介紹 MOVED 轉向的時候,我們說除了 MOVED 轉向之外,還有另一種 ASK 轉向。
當節點需要讓一個用戶端長期地(permanently)将針對某個槽的指令請求發送至另一個節點時,節點向用戶端傳回 MOVED 轉向。
另一方面,當節點需要讓用戶端僅僅在下一個指令請求中轉向至另一個節點時,節點向用戶端傳回 ASK 轉向。
比如說,在我們上一節列舉的槽 8 的例子中,因為槽 8 所包含的各個鍵分散在節點 A 和節點 B 中,是以當用戶端在節點 A 中沒找到某個鍵時,它應該轉向到節點 B 中去尋找,但是這種轉向應該僅僅影響一次指令查詢,而不是讓用戶端每次都直接去查找節點 B :在節點 A 所持有的屬于槽 8 的鍵沒有全部被遷移到節點 B 之前,用戶端應該先通路節點 A ,然後再通路節點 B 。
因為這種轉向隻針對 16384 個槽中的其中一個槽,是以轉向對叢集造成的性能損耗屬于可接受的範圍。
因為上述原因,如果我們要在查找節點 A 之後,繼續查找節點 B ,那麼用戶端在向節點 B 發送指令請求之前,應該先發送一個 ASKING 指令,否則這個針對帶有 IMPORTING 狀态的槽的指令請求将被節點 B 拒絕執行。
接收到用戶端 ASKING 指令的節點将為用戶端設定一個一次性的标志(flag),使得用戶端可以執行一次針對 IMPORTING 狀态的槽的指令請求。
從用戶端的角度來看, ASK 轉向的完整語義(semantics)如下:
如果用戶端接收到 ASK 轉向,那麼将指令請求的發送對象調整為轉向所指定的節點。
先發送一個 ASKING 指令,然後再發送真正的指令請求。
不必更新用戶端所記錄的槽 8 至節點的映射:槽 8 應該仍然映射到節點 A ,而不是節點 B 。
一旦節點 A 針對槽 8 的遷移工作完成,節點 A 在再次收到針對槽 8 的指令請求時,就會向用戶端傳回 MOVED 轉向,将關于槽 8 的指令請求長期地轉向到節點 B 。
注意,即使用戶端出現 Bug ,過早地将槽 8 映射到了節點 B 上面,但隻要這個用戶端不發送 ASKING 指令,用戶端發送指令請求的時候就會遇上MOVED 錯誤,并将它轉向回節點 A 。
容錯?
節點失效檢測?
以下是節點失效檢查的實作方法:
當一個節點向另一個節點發送 PING 指令,但是目标節點未能在給定的時限内傳回 PING 指令的回複時,那麼發送指令的節點會将目标節點标記為PFAIL (possible failure,可能已失效)。
等待 PING 指令回複的時限稱為“節點逾時時限(node timeout)”,是一個節點選項(node-wise setting)。
每次當節點對其他節點發送 PING 指令的時候,它都會随機地廣播三個它所知道的節點的資訊,這些資訊裡面的其中一項就是說明節點是否已經被标記為 PFAIL 或者 FAIL 。
當節點接收到其他節點發來的資訊時,它會記下那些被其他節點标記為失效的節點。這稱為失效報告(failure report)。
如果節點已經将某個節點标記為 PFAIL ,并且根據節點所收到的失效報告顯式,叢集中的大部分其他主節點也認為那個節點進入了失效狀态,那麼節點會将那個失效節點的狀态标記為 FAIL 。
一旦某個節點被标記為 FAIL ,關于這個節點已失效的資訊就會被廣播到整個叢集,所有接收到這條資訊的節點都會将失效節點标記為 FAIL 。
簡單來說,一個節點要将另一個節點标記為失效,必須先詢問其他節點的意見,并且得到大部分主節點的同意才行。
因為過期的失效報告會被移除,是以主節點要将某個節點标記為 FAIL 的話,必須以最近接收到的失效報告作為根據。
在以下兩種情況中,節點的 FAIL 狀态會被移除:
如果被标記為 FAIL 的是從節點,那麼當這個節點重新上線時, FAIL 标記就會被移除。
保持(retaning)從節點的 FAIL 狀态是沒有意義的,因為它不處理任何槽,一個從節點是否處于 FAIL 狀态,決定了這個從節點在有需要時能否被提升為主節點。
如果一個主節點被打上 FAIL 标記之後,經過了節點逾時時限的四倍時間,再加上十秒鐘之後,針對這個主節點的槽的故障轉移操作仍未完成,并且這個主節點已經重新上線的話,那麼移除對這個節點的 FAIL 标記。
在第二種情況中,如果故障轉移未能順利完成,并且主節點重新上線,那麼叢集就繼續使用原來的主節點,進而免去管理者介入的必要。
叢集狀态檢測(已部分實作)?
從節點選舉?
釋出/訂閱(已實作,但仍然需要改善)?
Redis Cluster failover機制
節點心跳
失效檢測
從選舉與提升
模拟當機(實作故障轉移)
程式開發
排行榜
遊戲伺服器中涉及到很多排行資訊,比如玩家等級排名、金錢排名、戰鬥力排名等。
一般情況下僅需要取排名的前N名就可以了,這時可以利用資料庫的排序功能,或者自己維護一個元素數量有限的top集合。
但是有時候我們需要每一個玩家的排名,玩家的數量太多,不能利用資料庫(全表排序壓力太大),自己維護也會比較麻煩。
使用Redis可以很好的解決這個問題。它提供的有序Set,支援每個鍵值(比如玩家id)擁有一個分數(score),每次往這個set裡添加元素,
Redis會對其進行排序,修改某一進制素的score後,也會更新排序,在擷取資料時,可以指定排序範圍。
更重要的是,這個排序結果會被儲存起來,不用在伺服器啟動時重新計算。
通過它,排行榜的實時重新整理、全服排行都不再成為麻煩事。
消息隊列(可跨服)
Redis提供的List資料類型,可以用來實作一個消息隊列。
由于它是獨立于遊戲伺服器的,是以多個遊戲伺服器可以通過它來交換資料、發送事件。
Redis還提供了釋出、訂閱的事件模型。
利用這些,我們就不必自己去實作一套伺服器間的通信架構,友善地實作伺服器組。
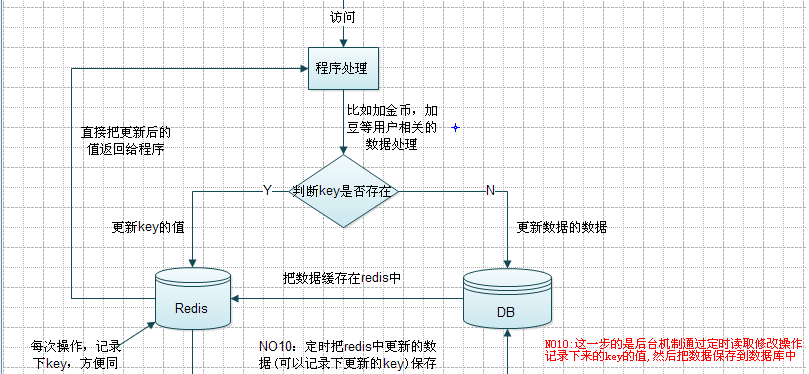
資料庫緩存
Redis提供了較為豐富資料類型,使我們可以更為容易地将資料對象緩存起來(序列化、protobuffer)。
當需要請求某一資料時,先從Redis中查找,如果沒有再查資料庫,同時交給Redis緩存起來。
當對資料進行修改時,則先将修改後的資料儲存到Redis,然後儲存至資料庫(2)。
第2步可以有另外的思路:
A不實時儲存到資料庫,而是交由另外的線程(甚至是專門的程式)去儲存,以提高邏輯層的響應速度。
B部分資料交給Redis儲存(Reids自身有持久化功能),像玩家已經完成過的任務ID集合,利用Redis的Set類型儲存更為合适。
C玩家瞬時變化的資料不見得每次修改都需要儲存(比如金錢、經驗),但如果遊戲伺服器自己維護在記憶體中,出現當機就會導緻回檔。
Redis是獨立于遊戲伺服器的,交由它來儲存,可以防止當機回檔的問題,也可以減少遊戲伺服器自己維護資料所占用的記憶體。
本文轉自 liqius 51CTO部落格,原文連結:http://blog.51cto.com/szgb17/1914456,如需轉載請自行聯系原作者
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)