A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
【GiantPandaCV導語】ViT的興起挑戰了CNN的地位,随之而來的是MLP系列方法。三種架構各有特點,為了公平地比較幾種架構,本文提出了統一化的架構SPACH來對比,得到了具有一定insight的結論。
近期Transformer MLP系列模型的出現,增加了CV領域的多樣性,MLP-Mixer的出現表明卷積或者注意力都不是模型性能優異的必要條件。不同架構的模型進行比較的過程中,會使用不同的正則化方法、訓練技巧等,為了比較的公平性,本文提出了SPACH的統一架構,期望對幾種架構進行對比,同時探究他們各自的特點。
這個架構總體來說有兩種模式:多階段和單階段。每個階段内部采用的是Mixing Block,而該Mixing Block可以是卷積層、Transformer層以及MLP層。
經過實驗發現了以下幾個結論:
多階段架構效果優于單節段架構(通過降采樣劃分階段)
局部性模組化具有高效性和重要性。
通過使用輕量級深度卷積(depth wise conv),基于卷積的模型就可以取得與Transformer模型類似的性能。
在MLP和Transformer的架構的支路中使用一些局部的模組化可以在有效提升性能同時,隻增加一點點參數量。
MLP在小型模型中具有非常強的性能表現,但是模型容量擴大的時候會出現過拟合問題,過拟合是MLP成功路上的攔路虎。
卷積操作和Transformer操作是互補的,卷積的泛化性能更強,Transformer結構模型容量更大。通過靈活組合兩者可以掌控從小到大的所有模型。
本文提出一統MLP、Transformer、Convolution的架構:SPACH
下表展示的是各個子產品中可選的參數,并提出了三種變體空間。
其中各個子產品設計如下:
(a)展示的是卷積部分操作,使用的是3x3深度可分離卷積。
(b)展示的是Transformer子產品,使用了positional embedding(由于目前一些研究使用absolute positional embedding會導緻子產品模型的平移不變性,是以采用Convolutional Position Encoding(CPE)。
(c)展示的是MLP子產品,參考了MLP-Mixer的設計,雖然MLP-Mixer中并沒有使用Positional Embedding,但是作者發現通過增加輕量級的CPE能夠有效提升模型性能。
注:感覺這三種子產品的設計注入了很多經驗型設計,比如卷積并沒有用普通卷積,用深度可分離卷積其實類似MLP中的操作,此外為MLP引入CPE的操作也非常具有技巧性。
三種子產品具有不同的屬性:
所謂dynamic weight是Transformer中可以根據圖檔輸入的不同動态控制權重,這樣的模型的容量相較CNN更高。CNN中也有這樣的趨勢,dynamic network的出現也是為了實作動态權重。(感謝zzk老師的講解)Transformer側重是關系的學習和模組化,不完全依賴于資料,CNN側重模闆的比對和模組化,比較依賴于資料。
Transformer
CNN
Dynamic Attention
Multi-scale Features by multi-stage
Global Context Fusion
Shift,scale and distortion invariance
Better Generalization(學習關系,不完全依賴資料)
Local Spatial Modeling
實驗設定:
資料集選擇ImageNet-1K
輸入分辨率224x224
訓練設定參看DeiT
AdamW優化器訓練300個epoch
weight decay: 0.05 (T用的weight decay更小)
learning rate:0.005 對應 512 batch size(T用的lr更小)
結論1:multi-stage 要比 single-stage性能更好
具體性能如下表所記錄,Multi-Stage能夠顯著超過Single Stage的模型。
可以發現,有一個例外,在xxs尺度下,Transformer進度損失了2.6個百分點,因為多階段模型恰好隻有單階段模型一半的參數量和Flops。
随着參數量的增加,模型最高精度先後由MLP、Conv、Transformer所主導。
結論2:局部模組化非常重要
上表展示了具有局部模組化以及去除局部模組化的效果,可以發現使用卷積旁路的時候吞吐量略微降低,但是精度有顯著提高。
結論3:MLP的細節分析
MLP性能不足主要源自于過拟合問題,可以使用兩種機制來緩解這個問題。
Multi-Stage的網絡機制,可以從以上實驗發現,multi-stage能夠有效降低過拟合,提高模型性能。
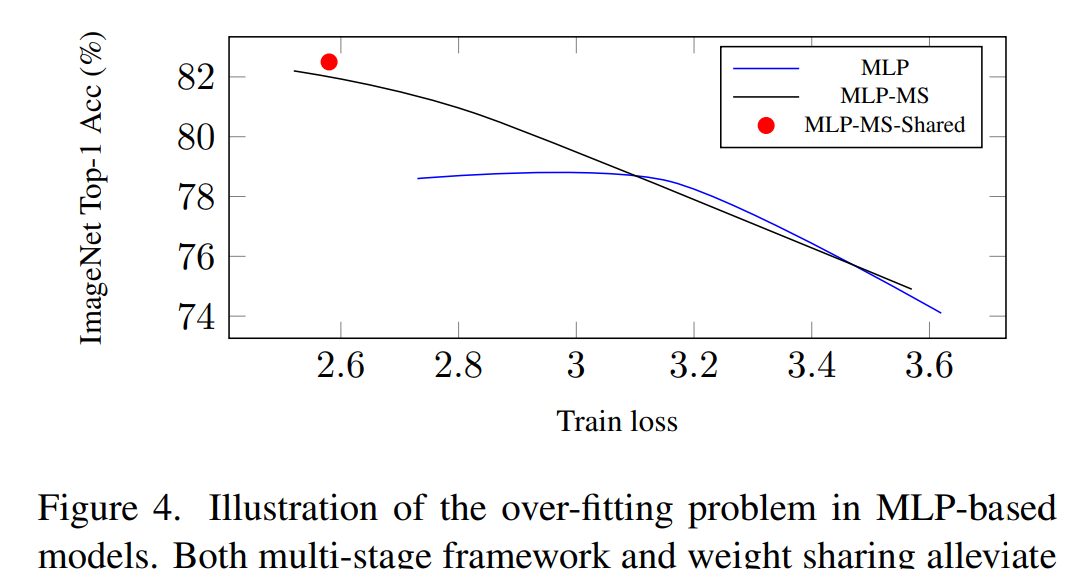
權重共享機制,MLP在模型參數量比較大的情況下容易過拟合,但是如果使用權重共享可以有效緩解過拟合問題。具體共享的方法是對于某個stage的所有Mixing Block均使用相同的MLP進行處理。

結論4:卷積與Transformer具有互補性
作者認為卷積具有的泛化能力更強,而Transformer具有更大的模型容量,如下圖所示,在Loss比較大的情況下,整體的準确率是超過了Transformer空間的。
結論5: 混合架構的模型
在multi-stage的卷積網絡基礎上将某些Mixing Block替換為Transformer的Block, 并且處于對他們模組化能力的考量,選擇在淺層網絡使用CNN,深層網絡使用Transformer,得到兩種模型空間:
SOTA模型比較結果:
整體結論是:
Transformer能力要比MLP強,是以不考慮使用MLP作為混合架構
混合Transformer+CNN的架構性能上能夠超越單獨的CNN架構或者Transformer架構
FLOPS與ACC的權衡做的比較出色,能夠超越Swin Transformer以及NAS搜尋得到的RegNet系列。
最後作者還向讀者進行提問:
MLP性能欠佳是由于過拟合帶來的,能夠設計高性能MLP模型防止過拟合呢?
目前的分析證明卷積或者Transformer并不是一家獨大,如何用更好的方式融合兩種架構?
是否存在MLP,CNN,Transformer之外的更有效地架構呢?
對照下圖逐漸給出各個Mixing Block:
(a)卷積子產品 ,kernel為3的深度可分離卷積
(b)Transformer
(c)MLP子產品,分為channel mlp和spatial mlp,與MLP-Mixer保持一緻
SPACH骨幹網絡的建構: MixingBlock
SPACH建構:
https://github.com/microsoft/SPACH
https://zhuanlan.zhihu.com/p/411145994
https://arxiv.org/pdf/2108.13002v2.pdf
代碼改變世界