失敗是成功之母:HER有自我審視能力
最近幾個月,OpenAI的研究人員集中精力于建構具有更強的學習能力的人工智能。得益于他們的增強學習系統OpenAI baselines,機器學習算法可以進行自主學習。目前,這個新的算法保證人工智能可以像人類一樣從自己的錯誤中汲取教訓。
這個進步源于OpenAI的研究人員在近期公布的名為“後見之明經驗複現(Hindsight Experience Reply, HER)”的開源算法。正如名字所示,HER幫助人工智能系統在完成一項任務後,具有自我審視的能力。OpenAI的部落格中提到,人工智能認為失敗乃成功之母。
以下是視訊介紹:
研究人員寫到:“建構HER的關鍵在于利用人類的直覺:在實作某個任務時,雖然我們沒有成功,但是在這個過程中我們學到一些不一樣的東西,既然如此,為何不能将我們最終學到的知識作為我們最初的目标呢?“
簡而言之,這意味着每一次失敗的嘗試都是為了實作一個意想不到的“虛拟”目标,而非既定目标。
回想一下你學騎單車的經曆,在最開始的幾次嘗試中,你無法掌握平衡。但是這些經驗告訴了你怎麼騎車是不正确的,怎麼做不能保持平衡。就像在人類的學習過程中,每一次的失敗讓我們距離成功更進一步。
獎勵每一次失敗,并且失敗也不沮喪
通過使用HER,OpenAI希望他們的人工智能系統可以利用上述的方法來學習。與此同時,這種算法也被作為增強學習模型中的獎勵機制的替代算法。為了訓練人工智能,使其具有獨立的學習能力,它需要包含一個獎勵機制:如果人工智能算法達到了預期目标,就可以得到一個小獎勵,就像獎勵給小孩子一塊奶油餅幹一樣,否則就什麼都得不到。另外一個系統根據人工智能距離預期目标的距離來給出獎勵。
但是這兩種算法并不是完美的。第一個算法會阻礙學習,因為一個人工智能算法在訓練過程中要麼得到獎勵,要麼沒得到。另一方面,根據IEEE Spectrum報道的内容顯示,第二系統在實作時,需要衡量與目标的距離并給出獎勵,這個過程是很需要技巧的。如果把每一個任務都當作是後見之明的目标,即使人工智能系統沒有完成指定的任務,HER也會提供一個獎勵。這樣幫助人工智能更快更好地學習。
OpenAI 在他的的部落格中提到:“通過進行這種獎勵機制的替換,強化學習算法在實作某些目标後會獲得一個學習信号,即使這個學習任務不是它最初希望實作的。如果重複這個過程,系統最終可以實作任意的目标,包括最初的既定目标。
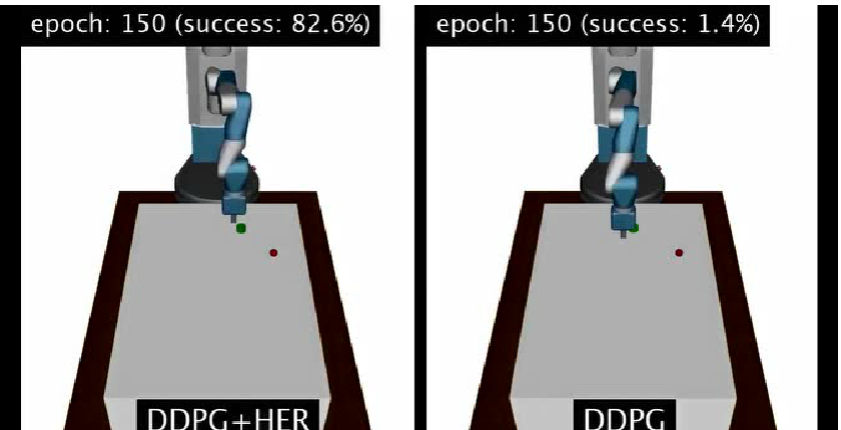
這種方法并不意味着使用HER方法可以完全簡化人工智能系統學習某個任務的過程。研究者表示:“在機器人上使用HER進行學習仍然很難實作,因為這個過程需要大量的資料“。
無論如何,正如OpenAI的模型所顯示的,HER有助于鼓勵人工智能系統像人類一樣從錯誤中學習,兩者的主要差別在于人工智能在面對失敗的時候不會像一些脆弱的人類那樣傷心沮喪。
原文釋出時間為:2018-03-4
本文作者:小潘
本文來自雲栖社群合作夥伴新智元,了解相關資訊可以關注“AI_era”微信公衆号
![241 Different Ways to Add Parentheses(C代碼版)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)