首先,還是老樣子,清楚目前資料庫中所有的内容,幹幹淨淨開始學習新的一章。
match (n)-[r]-(n1)
delete r,n,n1
match (n)
delete n
接下來,還要使用第二篇博文中的人物和聯系:
CREATE (bradley:MALE:TEACHER {name:'Bradley', surname:'Green',age:24, country:'US'})
CREATE (matthew:MALE:STUDENT {name:'Matthew', surname:'Cooper',age:36, country:'US'})
CREATE (lisa:FEMALE {name:'Lisa', surname:'Adams', age:15,country:'Canada'})
CREATE (john:MALE {name:'John', surname:'Goodman', age:24,country:'Mexico'})
CREATE (annie:FEMALE {name:'Annie', surname:'Behr', age:25,country:'Canada'})
CREATE (ripley:MALE {name:'Ripley', surname:'Aniston',country:'US'})
MATCH (bradley:MALE{name:"Bradley"}),(matthew:MALE{name:"Matthew"})WITH bradley, matthew CREATE (bradley)-[:FRIEND]->(matthew) , (bradley)-[:TEACHES]->(matthew);
MATCH (bradley:MALE{name:"Bradley"}),(matthew:MALE{name:"Matthew"})WITH bradley,matthew CREATE (matthew)-[:FRIEND]->(bradley);
MATCH (bradley:MALE{name:"Bradley"}),(lisa:FEMALE{name:"Lisa"})WITH bradley,lisa CREATE (bradley)-[:FRIEND]->(lisa);
MATCH (lisa:FEMALE{name:"Lisa"}),(john:MALE{name:"John"})WITH lisa,john CREATE (lisa)-[:FRIEND]->(john);
MATCH (annie:FEMALE{name:"Annie"}),(ripley:MALE{name:"Ripley"})WITH annie,ripley CREATE (annie)-[:FRIEND]->(ripley);
MATCH (ripley:MALE{name:"Ripley"}),(lisa:FEMALE{name:"Lisa"})WITH ripley,lisa CREATE (ripley)-[:FRIEND]->(lisa);
一、索引
Neo4j2.0版本在标簽的基礎上引入了索引,可以對标簽進行限制和索引。這種方式即有助于資料完整性檢查,也有利于優化Cypher。上一篇博文最後介紹了限制,本篇關注度的則是索引的用法和功能。
Neo4j的索引和其他RDBMS的定義相類似,主要用于提升節點找尋的性能。對于任何已有資料結構的更改操作,索引自動更新。如果出了錯而導緻索引處于無效狀态,便需要差錯并重新生成它們。
Cypher查詢會自動使用索引,Cypher有一個查詢計劃器和查詢優化器,可以對查詢進行評估并嘗試盡全力依據選索引擇最短執行時間。
建立索引的過程并不複雜:
首先,使用如下語句對标簽MALE和屬性name建立一個索引:
create index on :MALE(name)
核實是否已經建立,書上說需要在neo4j-shell中使用下列指令:schema ls。但我在Web界面上使用則是報錯,沒有此指令。
删除索引使用如下指令:
drop index on :MALE(name)
一旦索引建立,随後但凡在where從句中出現具有索引的屬性時,不論是簡單的等值比較還是其他條件,索引的使用都是自動的。然而,還有一種外顯的指定索引的使用方式,就是using從句。如:
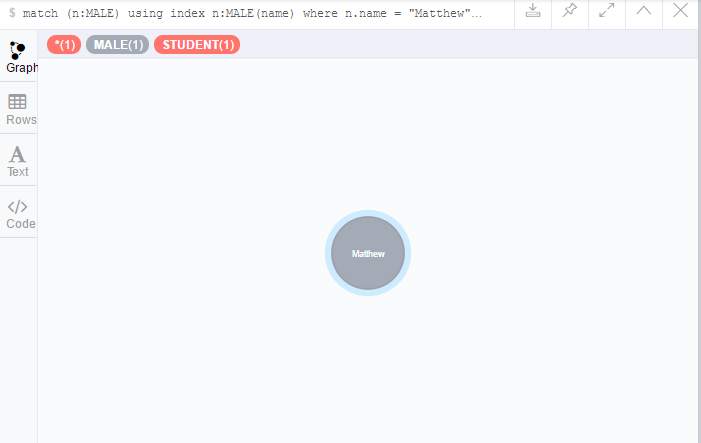
match (n:MALE)
using index n:MALE(name)
where n.name = "Matthew"
return n
結果如下圖所示,很遺憾在非終端中看不到查詢的耗時,盡管目前的學習和測試是在Win 10下完成的,但也可以使用windows準備的Cypher-shell,可以參考另一篇文章《Neo4j入門點滴(五):Windows Shell for Cypher》。
重點來了,必須記住:我們也可以在一個單一查詢中使用using從句并提供多個索引項來給Cypher Query Optimizer提供索引提示,也可以使用scan給Cypher Query Planner先掃描所有标簽然後再執行後續的過濾,這種做法的結果意味着優秀的性能,畢竟使用标簽本身可以不必考慮那些不必要的資料。如:
using scan n:MALE
盡管上述查詢的結果是一樣的,但性能會更好。需要注意的一點,使用scan時使用的是:MALE,而非index時的:MALE(name),這點一定要警惕。
二、Index Sampling
真不太好翻譯,是以還是直接使用英文詞組吧。
其實,所有Cypher查詢執行的第一步就是先要制訂出一個有效的執行計劃。盡管這個計劃由Neo4j自行建立,但建立之前系統需要知道目前資料庫、索引、索引所含的節點數、聯系等多種重要資訊。這些資訊将幫助Neo4j設計一個效率高、效果好的執行計劃,進而使得我們的查詢請求被更快地響應。下一小節在詳細讨論執行計劃的過程,但是有效執行計劃其中一個步驟就是Index Sampling。實際上,Index Sampling就是我們經常對索引進行分析和取樣,確定索引統計資料更新,以及在資料庫增删改資料的并對相應索引進行更改的全部過程。
我們可以通過開啟Neo4j資料庫的下列屬性實作自動index sampling(Linux下是檔案neo4j.properties,windows的還沒找到):
index_background_sampling_enabled:該布爾屬性值預設被設定為False,将其改為True開啟自動sampling。
index_sampling_update_percentage:定義了在觸發sampling之前需要被改變索引的百分比門檻值。
當然,也可以在終端中輸入如下指令手動開啟:
schema sample -a:觸發對所有索引做sampling。
schema sample -l MALE -p name:僅僅觸發标簽(l)和屬性(p)定義的索引的sampling。
三、了解執行計劃
對于所有查詢的執行計劃的生成,Neo4j使用的都是基于成本的優化器(Cost Based Optimizer,CBO),用于制訂精确的執行過程。可以采用如下兩種不同的方式了解其内部的工作機制:
EXPLAIN:是解釋機制,加入該關鍵字的Cypher語句可以預覽執行的過程但并不實際執行,是以也不會産生任何結果。
PROFILE:則是畫像機制,查詢中使用該關鍵字,不僅能夠看到執行計劃的詳細内容,也可以看到查詢的執行結果。
舉例如下:
profile match (n)
where n.name = 'Annie'
如下圖所示:

點選展開後,是這樣:
此外,我還發現,Shell模式下,explain和profile都不如Web界面輸入的資訊多,不知道是不是版本的問題,還是參數設定的問題:
四、分析并優化查詢
還是用剛才Annie那個例子,正如所見,原查詢并不高效,因為AllNodesScan需要對所有節點逐一進行比對。然而,别忘了,Cypher引入的标簽系統可不是擺着看的,試着對剛才的例子添加标簽:
profile match (n:FEMALE)
結果如下圖:
可以看到,優化器由AllNodesScan變為了NodeByLabelScan,過濾的過程也有原來的6-1-1縮減為目前的2-1-1。但這并沒有結束,還可以進一步優化,對,就是使用index。
create index on :FEMALE(name)
其他都不變,隻是提前建立一條索引,這下子優化器就可以用NodeIndexSeek,整個過程由剛才的2-1-1變成了現在的1-1-1,也就是沒有任何不必要的額外付出,一擊命中!
具體的優化參數,可以參考estimated rows和db hits這兩個數值,都是越小越好。前者指需要被掃描行數的預估值,後者是系統實際運作結果的命中(I/O)績效。其實,并不存在放之四海而皆準的通用标準(否則開發者已經就直接把這些标準内化到Neo4j中了),是以還需要積累經驗,經常對Cypher的執行進行分析和優化。
五嶽之巅
2017年5月29日(孟菲斯時間)
09:10
終稿于Dorsy Ave, Memphis, TN