PostgreSQL , 多表并行 , parallel append , sharding , 外部表 , 繼承 , 分區表 , union , pg_pathman , inherit
append是資料庫執行計劃中很場景的一個NODE,資料來自掃描多個對象的集合時,都需要APPEND。比如:
1、掃描分區表
2、掃描主表(包含若幹繼承表時)
3、UNION ALL語句。(union 暫時不支援)
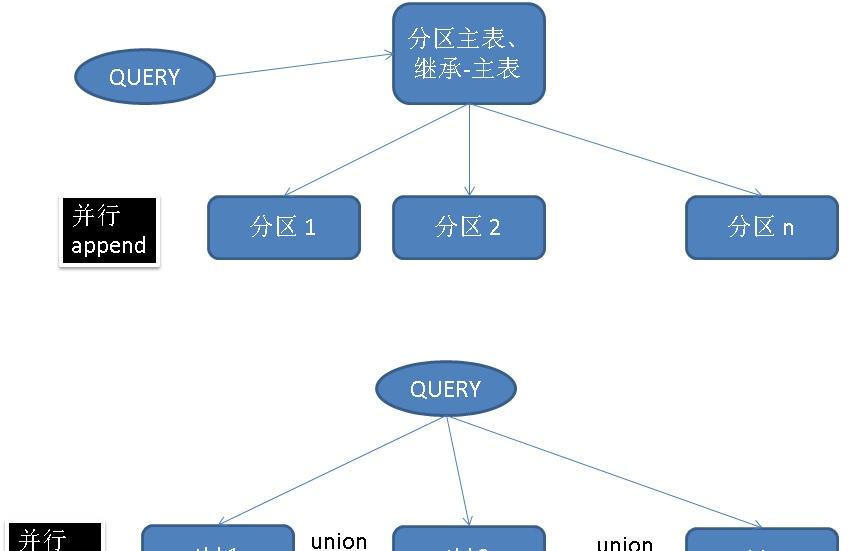
使用parallel append的功能,可以設計出非常靈活的架構,例如sharding可以在資料庫核心層面并行,不需要依賴中間件例如plproxy了。(暫時還不支援直接用foreign table+inherit的模式,不過可以用pg_pathman)

1、建立本地分區表
2、寫入1億測試資料
3、設定分區并行度為0,防止單個分區并行掃描太快,看不出性能差異。
這裡測試了兩個CASE,一個含并行聚合,一個不含并行計算(全量傳回)。實際上parallel append适合一路并行,而不适合上層沒什麼計算,串行接收大量APPEND資料的場景。
1、含并行聚合(上層直接對接partial agg worker,是以流式處理掉了),并行append
2、串行APPEND
3、不含并行聚合(上層傳回所有資料,性能反而下降),并行append
4、串行APPEND
1、并行append
1、準備資料
2、parallel append
3、串行append
1、建立postgres_fdw
2、建立外部資料源
3、設定外部資料源通路秘鑰
4、建立外部表
5、建立外部表繼承關系
2、寫入2億測試資料
3、串行append測試
4、并行append測試
1、測試外部表的繼承表主表
2、使用union all查詢多個外部表
1、parallel append功能,在每個參與append的資料分片計算并傳回的記錄數比較少時,性能提升幾乎是線性的。
2、當每個參與append的資料分片都要傳回大量資料時,需要注意是否有用到支援并行的聚合,如果沒有,那麼上層還需要處理大量資料量PARALLEL APPEND效果就不明顯。否則不要使用parallel append。(實際上parallel append适合一路并行,而不适合上層沒什麼計算,串行接收大量APPEND資料的場景。)
3、parallel append + 外部表 + pushdown,可以實作sharding 架構下的并發計算。(例如求SUM,AVG,COUNG,MIN,MAX等,不過針對外部表的parallel append核心層面還沒有支援好,需要CUSTOM SCAN)
4、parallel append VS append 性能
case
parallel append耗時
串行 append耗時
parallel append性能提升
點評
1億,4個并行分片,每個分片傳回少量資料
2.37 秒
6.99 秒
2.95 倍
幾乎線性提升
1億,4個并行分片,每個分片傳回大量資料(但是下一個NODE包括并行聚合)
6.46 秒
21.7 秒
3.36 倍
1億,4個并行分片,每個分片傳回大量資料(下一個NODE需要串行傳回大量資料)
76.5 秒
18.3 秒
- 4.18 倍
append的下一個NODE需要傳回大量資料時不适合使用并行append
2億,64個并行分片,每個分片傳回少量資料
0.655 秒
14.18 秒
21.65 倍
并行越大,提升越明顯,這裡還需要考慮記憶體帶寬瓶頸(20多倍時,處理速度為 12.9 GB/s)
<a href="https://commitfest.postgresql.org/16/987/">https://commitfest.postgresql.org/16/987/</a>
<a href="https://github.com/digoal/blog/blob/master/201610/20161027_01.md">《PostgreSQL 9.6 sharding based on FDW & pg_pathman》</a>
<a href="https://github.com/digoal/blog/blob/master/201610/20161024_01.md">《PostgreSQL 9.5+ 高效分區表實作 - pg_pathman》</a>