自從熟悉了linux socket程式設計(主要做posix socket的TCP/IP)之後,就一直以來就想寫一篇對TCP/IP有一個比較全面的涵蓋使用者空間、核心以及網卡的文章,以便幫助大家在遇到基于socket的TCP/IP問題或困惑時能進行有目的的、恰當的分析以便解決問題。隻是一是本人上學時是個“不學無術”的不良少年。工作後自己也是不斷學習中,還有比較忙(都是懶的借口吧,不然怎麼還有時間看龍珠),一直沒動筆,今天就花一下午時間來做一個介紹。如果大家發現了謬誤之處,請及時留言,我好更正之、學習之。話不多說,下面就進入正題。
現如今的internet services可以說就是基于TCP/IP建構的。了解資料是如何通過network傳輸的,無論對你調試net IO的性能還是解決問題還是學習新的技術都是有很大助益的。本文将會全面的,盡力細緻的通過核心及硬體中的資料流和控制流來介紹這方面的知識。
PS: 有一個我自認為實作的還不錯的項目,有興趣的童鞋可以參與github c/c++連接配接複用庫實作。
我們如何設計一個資料傳輸協定以便保證資料快速、有序、無誤?TCP/IP正是為了這樣的需求被創造的。下面的幾個特征用于幫助了解什麼是TCP/IP協定(棧)。由于對于TCP來講IP是緊密相關的,我們放到一起介紹。更多的内容,大家可以參考大學教材《計算機網絡》(謝希仁著)以及《TCP/IP協定》三卷(國外)。
面向連接配接的(Connection-oriented)
一個tcp connection有兩個端(endpoint),每一個endpoint可以用一個***(ip、port)來表達,是以兩端的話就可以用(local IP address, local port number, remote IP address, remote port number)***來表達。
資料是雙向流動的
雙向的傳遞二進制流。
按序傳送的
接受者接收資料一定是會按照發送者發送資料的順序的。通過一個32-bit integer做标記。通過ACK來保證可靠性,如果發送者收不到接受者的ACK,則會重新發送。
流量控制
發送方會根據接收方提供的的視窗大小來決定如何發送資料,不會超過接收方的緩沖能力。
擁塞控制
擁塞視窗(congestion window)差別于receive window,是發送方自己根據包ACK的狀态結合特定的擁塞算法計算出的一個window。它表達的目前的網絡狀态。發送發發送的資料上限受到流量控制和擁塞控制共同的作用。
資料通過網絡協定棧發送,如下圖1。

圖1:資料發送的流動過程
借用于國外大神的圖(下文也會借用很多,不一一說明了),其表達了資料的流動過程。這裡為了防止大家不認真看,我要強調一下右側黑色方塊表達使用者write的新的資料,而灰色的代表發送緩沖區中已有的資料,大括号圈的灰黑兩塊結合代表了一個TCP封包段。整個過程可以分為三個區域,user、kernel和device,其中user和kernel的部分要吃CPU的。這裡的device就是我們說的網卡(Network Interface Card)。
核心socket關聯了兩個緩沖區:
在核心中有一個TCP control block(TCB)關聯到socket。TCB包含了連接配接需要處理的一系列資料,這裡面包含了TCP的state(LISTEN, ESTABLISHED, TIME_WAIT),receive window, congestion window, sequence number, resending timer等等。
核心中如果目前的TCP狀态允許資料發送,則一個新的TCP封包段(或者說包)就會被建立。
圖2:TCP封包段
之後封包段流向IP層。IP層在TCP的封包段上加上IP頭并執行IP路由。IP路由是尋找到達目的IP的下一跳的一個程式。IP層計算完并加上IP頭的checksum之後就會把資料發送到鍊路層。鍊路層通過ARP和下一跳的IP位址查找到下一跳的MAC位址,之後鍊路層把其頭加到資料中。至此主機端資料包完成。之後就是調用網卡驅動了。此時如果有包捕獲程式比如tcpdump或者Wireshark處于運作中,核心會把資料包拷貝給它們一份。
驅動根據硬體廠商定義的協定請求傳送資料。網卡在接到資料傳送請求之後把資料包從主存拷貝到它的存儲空間中,之後把資料打到網線。這時,為了遵從以太網标準,網卡會添加IFG(幀間隔)到資料包以便區分資料包的開始。網卡發送完資料包之後就會産生一個CPU中斷,每一個中斷都一個特定的中斷号,OS根據中斷号選擇合适的驅動對中斷進行處理(驅動啟動的時候會注冊一個對應中斷号的處理函數)。
現在我們來看看是怎麼接收資料的,如圖3。
圖3:資料流入過程
首先網卡把接收到的資料包寫入到它的記憶體之中。然後對其進行校驗,通過後發送到主機的主存之中。主存中的buffer是驅動配置設定好的,驅動會把配置設定好的buffer描述告訴網卡,如果沒有足夠的buffer接受網卡的資料包,網卡會将資料包丢棄。一旦資料包拷貝到主存完成,網卡會通過中斷告知主機OS。
之後驅動會檢查它是否能處理這個新的包。如果能處理,驅動會把資料包包裝成OS認識的結構(linux sk_buffer)并推送到上層。
鍊路層接收到幀後檢查通過的話會按照協定解幀并推送至IP層。
IP層會在解包之後根據包中包含的IP資訊決定推送至上層還是轉發到其他IP。如果判斷需要推送至上層,則會解掉IP標頭并推送至TCP層。
TCP在解報之後會根據其四元組找到對應的TCB,之後通過TCP協定處理這個封包。在接收到封包後,會把封包加到接受封包,之後根據TCP的狀态發送一個ACK給對端。
當然上述過程會受到NAT等等Netfilter的作用,這裡不談了,也沒深研究過。當然為了性能,大牛們方方面面也做了很多努力,比如大到RDMA、DPDK等大的軟硬體技術,小到zero-copy、checksum offload等。
下面介紹一下關鍵資料結構sk_buff(skb)。
圖4:sk_buffer(意為socket buffer?)
一個skb就是一個發送緩沖區可發送的資料包。從圖4中可以看到其各個指針。不同層級的資料標頭的添加和删除、資料包的聯合和分割都是通過控制這些指針來實作的。真正的資料結構可能比這複雜很多,但是基本思路是一緻的。
TCP control block
一個TCB代表了一個connection,這裡TCB是一個抽象,linux用tcp_sock這個結構表達。下圖5可以看出tcp_sock和fd、socket之間的關系。
圖5:TCP connection結構
當調用系統調用的時候,OS先找到file結構。對于類unix系統,socket、本地file、device都被抽象成file。是以file擁有最少的資訊。對于socket,有其自己的結構關聯到file,tcp_sock也會關聯到socket。tcp_sock隻是socket的一類,其他還有諸如inet_sock等支援各種協定的sock。所有TCP相關的資訊都在tcp_sock中,比如序号啊,各種視窗等。
發送和接收緩沖區就是sk_buffer的list。dst_entry就是路由的結果,為了避免太頻繁的路由,他們是sock關聯的。dst_entry允許簡單的ARP查找,它也是路由表的一部分。tcp_sock通過對四元組進行hash來索引。
這一部分的知識可能是網上最難搜尋到的部分,很大一部分原因應該是很少有人關注吧,但是了解了這部分知識會讓你更通透。
驅動和網卡之間是異步通信。驅動在請求發送資料之後CPU就去幹别的事情去了。網卡發送完包之後通過中斷通知CPU,CPU再通過驅動程式了解到結果。和發送資料一樣,接收資料也是異步的。網卡把資料倒騰到主存之後再通過中斷通知CPU。
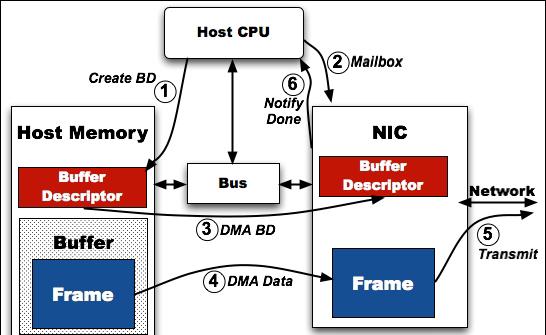
是以,預留一些空間來緩存發送和接受的buffer是必要的。大多數情況下,網卡使用環結構,這個環基本上就是一個隊列,它具有固定的條目數,每一個條目存儲一個發送或者接受的資料。條目被順序的輪流使用,可以複用。如下圖6,可以看到資料傳送過程。
圖6:驅動與網卡發送資料流
驅動接收上層的資料并建立一個網卡可以了解的資料包描述(send descriptor),包含了主存位址和大小。由于網卡隻認識實體位址,是以驅動還需将虛拟位址轉換成實體位址,之後把send descriptor放到Tx ring之中。下一步通過通知網卡有新的資料了,之後網卡通過DMA(直接記憶體通路)擷取中繼資料和資料發送出去。發送完之後通過DMA把結果寫回,之後發送中斷通知。
資料的接收和發送反推過程差不多,自己看圖7說話吧;-)。
圖7:驅動與網卡接收資料流
協定棧中的控制流分為幾個階段。圖8顯示了buffer的發送過程。
圖8:buffer發送流
首先應用程式建立資料并加入到發送緩沖區。如果緩沖區不足則調用失敗或者阻塞調用線程。是以應用程式向核心灌入資料的速率收到緩沖區大小的限制。
之後TCP建立包并通過傳輸隊列(qdisc)發送給驅動。qdisc是一個FIFO結構并且是固定大小,這個大小可以通過ifconfig指令檢視,其中的txqueuelen便是,一般情況下它是千級别的。
在驅動和網卡之間是TX ring。之前提到它是定長的,如果它沒有足夠的空間,那麼當傳輸隊列(qdisc)也滿了之後包就會被drop,就形成了之下而上的反壓。
下圖9表現了buffer接收流。
圖9:buffer接收流
很容易通過發送流反推。值得注意的是驅動和協定棧之間沒有了隊列,資料是通過poll直接擷取的。如果主機處理的速度沒有網卡接收的快,則Rx ring會滿,就會有包被丢棄。一般情況下丢棄不會是因為TCP連接配接導緻的,因為TCP連接配接有流量控制,但是UDP是沒有的。可以通過ifconfig指令看到很多資訊,比如drop、error等包的數量。
現代的軟硬體TCP/IP協定棧單連結發送速率到1~2GiB/s完全沒有任何問題(經過實測)。如果你想探索更優秀的性能,你可以嘗試RMDA等技術,他們通過繞過核心以減少拷貝等方式優化了性能,當然可能依賴硬體。