數組的特點是:尋址容易,插入和删除困難;而連結清單的特點是:尋址困難,插入和删除容易。那麼我們能不能綜合兩者的特性,做出一種尋址容易,插入删除也容易的資料結構?答案是肯定的,這就是我們要提起的哈希表,哈希表有多種不同的實作方法,我接下來解釋的是最常用的一種方法—— 拉鍊法,我們可以了解為“連結清單的數組” ,如圖:
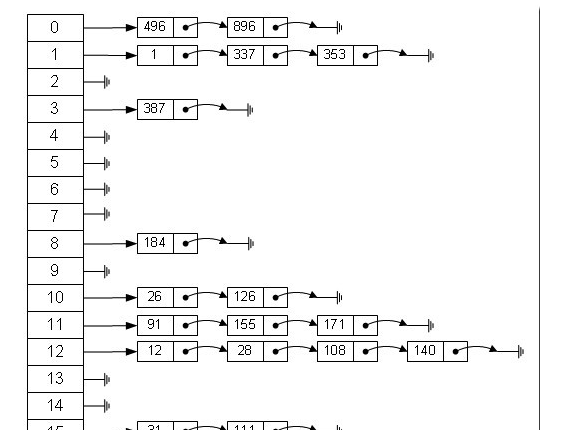
從上圖我們可以發現哈希表是由數組+連結清單組成的,一個長度為16的數組中,每個元素存儲的是一個連結清單的頭結點。那麼這些元素是按照什麼樣的規則存儲到數組中呢。一般情況是通過hash(key)%len獲得,也就是元素的key的哈希值對數組長度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。是以12、28、108以及140都存儲在數組下标為12的位置。
HashMap其實也是一個線性的數組實作的,是以可以了解為其存儲資料的容器就是一個線性數組。這可能讓我們很不解,一個線性的數組怎麼實作按鍵值對來存取資料呢?這裡HashMap有做一些處理。
1.首先HashMap裡面實作一個靜态内部類Entry,其重要的屬性有 key , value, next,從屬性key,value我們就能很明顯的看出來Entry就是HashMap鍵值對實作的一個基礎bean,我們上面說到HashMap的基礎就是一個線性數組,這個數組就是Entry[],Map裡面的内容都儲存在Entry[]裡面。
既然是線性數組,為什麼能随機存取?這裡HashMap用了一個小算法,大緻是這樣實作:
到這裡我們輕松的了解了HashMap通過鍵值對實作存取的基本原理
3.疑問:如果兩個key通過hash%Entry[].length得到的index相同,會不會有覆寫的危險?
這裡HashMap裡面用到鍊式資料結構的一個概念。上面我們提到過Entry類裡面有一個next屬性,作用是指向下一個Entry。打個比方, 第一個鍵值對A進來,通過計算其key的hash得到的index=0,記做:Entry[0] = A。一會後又進來一個鍵值對B,通過計算其index也等于0,現在怎麼辦?HashMap會這樣做:B.next = A,Entry[0] = B,如果又進來C,index也等于0,那麼C.next = B,Entry[0] = C;這樣我們發現index=0的地方其實存取了A,B,C三個鍵值對,他們通過next這個屬性連結在一起。是以疑問不用擔心。也就是說數組中存儲的是最後插入的元素。到這裡為止,HashMap的大緻實作,我們應該已經清楚了。
當然HashMap裡面也包含一些優化方面的實作,這裡也說一下。比如:Entry[]的長度一定後,随着map裡面資料的越來越長,這樣同一個index的鍊就會很長,會不會影響性能?HashMap裡面設定一個因素(也稱為因子),随着map的size越來越大,Entry[]會以一定的規則加長長度。
開放定址法(線性探測再散列,二次探測再散列,僞随機探測再散列)
再哈希法
鍊位址法
建立一個公共溢出區
Java中hashmap的解決辦法就是采用的鍊位址法。
MapTest.java

View Code
當神已無能為力,那便是魔渡衆生