1、NameNode
HDFS采用Master/Slave架構。namenode就是HDFS的Master架構。主要負責HDFS檔案系統的管理工作,具體包括:名稱空間(namespace)管理(如打開、關閉、重命名檔案和目錄、映射關系)、檔案block管理。NameNode提供的是始終被動接收服務的server。一個檔案被分成一個或多個Bolck,這些Block存儲在DataNode集合裡,NameNode就負責管理檔案Block的所有中繼資料資訊。
Secondary NameNode主要是定時對NameNode的資料snapshots進行備份,這樣可盡量降低NameNode崩潰之後導緻資料丢失的風險。具體就是從namenode中獲得fsimage和edits後把兩者重新合并發給NameNode,這樣,既能減輕NameNode的負擔又能安全得備份,一旦HDFS的Master架構失效,就可以借助Secondary NameNode進行資料恢複。
namenode管理着所有所有檔案系統的中繼資料。這些中繼資料包括名稱空間、通路控制資訊、檔案和Block的映射資訊,以及目前Block的位置資訊。還管理着系統範圍内的活動。
2、DataNode
用于存儲并管理中繼資料。DataNode上存儲了資料塊ID和資料塊内容,以及他們的映射關系。
3、用戶端
通路HDFS的程式或HDFS shell指令都可以稱為HDFS的用戶端,在HDFS的用戶端中至少需要指定HDFS叢集配置中的NameNode位址以及端口号資訊,或者通過配置HDFS的core-site.xml配置檔案來指定。
HDFS最重要的兩個元件為:作為Master的NameNode和作為Slave的DataNode。NameNode負責管理檔案系統的命名空間和用戶端對檔案的通路;DataNode是資料存儲節點,所有的這些機器通常都是普通的運作linux的機器,運作着使用者級别的服務程序。
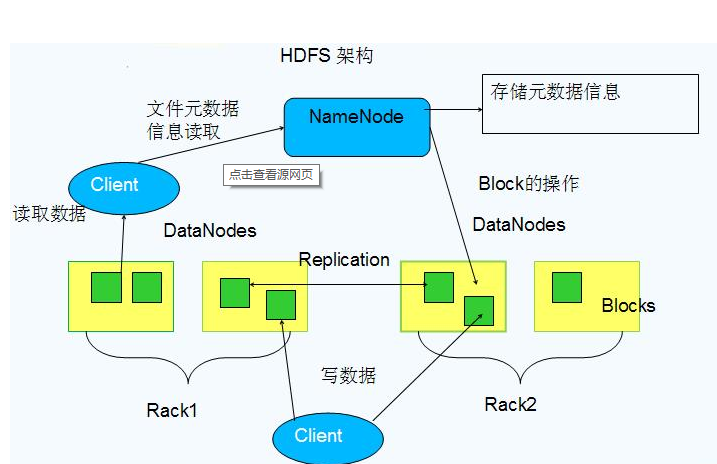
圖展示了HDFS的NameNode、DataNode以及用戶端的存取通路關系。NameNode負責儲存和管理所有的HDFS中繼資料,因而使用者資料不需要通過namenode,也就是說檔案資料的讀寫是直接在datanode上進行的。HDFS存儲的檔案被分割成固定大小的Block,在建立Block的時候,namenode伺服器會給每個block配置設定一個唯一不變的block辨別。datanode伺服器把block以linux檔案的形成儲存在本地磁盤上,并且根據指定的block辨別和位元組範圍來讀寫塊資料。處于可靠性的考慮,每個塊都會複制到多個datanode上。預設使用三個備援備份。
HDFS用戶端代碼以庫的形式被連結到客戶程式中。用戶端和namenode互動隻擷取中繼資料,所有的資料操作都是由用戶端直接和datanode進行互動。

圖為HDFS讀檔案資料流的過程,具體的執行過程為:
1、調用FileSystem的open()打開檔案,見序号1:open
2、DistributedFileSystem使用RPC調用NameNode,得到檔案的資料塊中繼資料資訊,并傳回FSDataInputStream給用戶端,見序号2:get block locations
3、HDFS用戶端調用stream的read()函數開始讀取資料,見序号3:read
4、調用FSDATAInputStream直接從DataNode擷取檔案資料塊,見序号4、5:read
5、讀完檔案時,調用FSDATAInputStream的close函數,見序号6:close
讀檔案時在多個資料塊檔案中選擇一個就可以了,但是寫資料檔案時需要同時寫道多個資料塊檔案中。
圖為HDFS寫檔案資料流的過程,首先用戶端調用create()來建立檔案,然後DistributedFileSystem同樣使用RPC調用namenode首先确定檔案是否不存在,以及用戶端有建立檔案的權限,然後建立檔案。DistributedFileSystem傳回DFSOutputStream,用戶端用于寫資料。用戶端開始寫入資料,DFSOutputStream将資料分成塊,寫入data queue。data queue由data streamer讀取,并通知中繼資料節點配置設定資料節點,用來存儲資料塊(每塊預設複制3塊)。配置設定的資料節點放在pipeline裡。data streamer将資料塊寫入pipeline中的第一個資料節點。第一個資料節點将資料塊發送給第二個資料節點,第二個資料節點将資料發送給第三個資料節點。DFSOutputStream為發出去的資料塊儲存了ack queue,等待pipeline中的資料節點告知資料已經寫入成功。
edits、fsimage、fstime。都是二進制檔案,可以通過Hadoop Writable對象就行序列化。
當用戶端執行寫操作時,首先namenode會在編輯日志中寫下記錄,并在記憶體中儲存一個檔案系統中繼資料,并且不斷更新。
fsimage檔案是檔案系統中繼資料的持久性檢查點,和編輯日志不同,它不會再每個檔案系統的寫操作後進行更新。但是檔案系統會出現編輯日志的不斷增長情況。為了解決這個問題,引入了secondary namenode。它的任務就是為原namenode記憶體中的檔案系統中繼資料産生檢查點,是一個輔助namenode處理fsimage和編輯日志的節點,它從namenode中拷貝fsimage和編輯日志到臨時目錄并定期合并成一個新的fsimage,随後上傳至namenode。具體的檢查點的處理過程如下:
1、secondary namenode首先請求原namenode進行edits的滾動,這樣新的編輯操作就能進入一個新的檔案中。
2、secondary namenode通過http方式讀取原namenode中的fsimage及edits。
3、secondary namenode讀取fsimage到記憶體中,然後執行edits中的每個操作,并建立一個新的統一的fsimage檔案。
4、secondary namenode将新的fsimage發送到原namenode。
5、原namenode用新的fsimage替換舊的,舊的edits檔案用步驟1中的edits進行替換,同時系統會更新fsimage檔案到檔案的記錄檢查點時間。
block的大小是HDFS關鍵的設計參數之一,預設大小為64MB,選擇較大的Block的優點:
1、減少了用戶端和NameNode通信的需求。
2、用戶端能夠對一個塊進行多次操作,這樣就可以通過block伺服器較長時間的TCP連接配接來減少網絡負載。
3、減少namenode節點需要儲存的中繼資料的數量,進而很容易把所有中繼資料放在記憶體中。
當然選擇較大的block也有一定的缺點,當檔案過小時,數百個用戶端并發請求通路會導緻系統局部過載,解決這個問題可以通過自定義更大的HDFS的複制因子來解決。
HDFS中,每個檔案存儲成block序列,除了最後一個block,所有的block都是同樣大小,檔案的所有block為了容錯都會被備援複制存儲。HDFS中的檔案是writer-one,嚴格要求任何時候隻能是一個writer。檔案的複制會全權交給namenode進行管理,namenode周期性的從叢集中的每個datanode接收心跳包和一個blockreport。心跳包表示該datanode節點正常工作,而blockreport包括了該datanode上所有的block組成的清單。
副本的存放是HDFS可靠性和高性能的關鍵。HDFS采用一種機架感覺的政策來改進資料的可靠性、可用性和網絡帶寬的使用率。一個簡單的沒有優化的政策就是将副本存放在不同的機架上。這樣可以有效防止當整個機架失效時資料的丢失,并且允許讀取資料的時候充分利用多個機架的帶寬。
HDFS的預設副本系數為3,副本存放政策是将第一個副本存放在本地機架的節點上,将第二個副本放在同一個機架的另一個節點上,将第三個副本放在不同的機架的節點上。因為是放在兩個機架上,是以減少了讀取資料時需要的網絡傳輸總帶寬。這樣的政策減少了機架之間的資料傳輸,提高了寫操作的效率,機架的錯誤遠比節點的錯誤要少的多,是以不會影響資料的可靠性和可用性。
當系統處于安全模式時,不會接受任何對名稱空間的修改,同時也不會對資料塊進行複制或删除。namenode啟動之後,自動進入安全模式,namenode從所有的datanode接收心跳信号和塊狀态報告。塊狀态報告包括了某個datanode所有的資料塊清單,每個資料塊都有一個指定的最小副本數。當namenode檢測确認某個資料塊的副本數目達到這個最小值,該資料塊就認為是副本安全的。在一定百分比的資料塊被namenode檢測确認是安全的之後(加上30s等待時間),namenode将退出安全模式。
HDFS很容易出現不平衡狀況的問題,同時也會引發其他問題,比如說MapReduce程式無法很好的利用本地計算機的優勢,機器之間無法到達更好的網絡帶寬使用率、機器磁盤無法利用等。HDFS提供了一個工具,用于分析資料塊分布和重新均衡DataNode上的資料分布。
$HADOOP_HOME/bin/start-balancer.sh -t 10%
這個指令,-t參數後面的是HDFS達到平衡狀态的磁盤使用率偏內插補點。如果機器與機器之間的使用率偏差小于10%,那麼我們認為HDFS叢集就達到了平衡狀态。
負載均衡程式作為一個獨立的程序與namenode進行分開執行,HDFS均衡負載處理工程如下:
1、負載均衡服務Rebalancing Server從namenode中擷取datanode的情況,具體包括每一個datanode磁盤使用情況,見序号1:get datanode report
2、Rebalancing Server計算哪些機器需要将資料移動,哪些機器可以接受移動的資料,以及從datanode中擷取需要移動資料的分布情況,見序号2:get partial blockmap
3、Rebalancing Server計算出來哪一台機器的block移動到另一台機器中去,見序号3:copy a block
4、需要移動block的機器将資料移動到目标機器上,同時删除自己機器上的block資料,見序号4、5、6
5、Rebalancing Server擷取本次資料移動的執行結果,并繼續執行這個過程,一直到沒有資料可以移動或HDFS叢集已經達到平衡的标準為止,見序号7
和更新軟體一樣,可以再叢集上更新hadoop,可能更新成功,也可能失敗,如果失敗了,就用rollback進行復原;如果過了一段時間,系統運作正常,就可以finalize正式送出這次更新。相關更新和復原指令如下:
更新過程:
1、通過dfsadmin -upgradeProgress status檢查是否已經存在一個備份,如果存在,則删除。
2、停止叢集并部署Hadoop的新版本
3、使用-upgrade選項運作新的版本(bin/start-dfs.sh -upgrade)
如果想退回老版本:
1、停止叢集并部署hadoop的老版本。
2、用復原選項啟動叢集,指令如下:bin/start-dfs.sh -rollback
1、通路時延:HDFS的設計主要是用于大吞吐量的資料,是以一定的時延為代價的。
2、對大量小檔案的處理
大量小檔案處理時難免産生大量線程時延。解決辦法:利用SequenceFile、MapFile、Har等方式歸檔小檔案。就是把小檔案歸檔管理,HBase就是這種原理。橫向擴充。多Master設計。
3、多使用者寫,任意檔案修改
用于建立一個hadoop歸檔檔案,hadoop archive是特殊的檔案格式。一個hadoop archive對應一個檔案系統目錄。拓展名是.har。
1)建立一個archive:使用方法如下:
例如:需要将目錄/usr/work/dir1和/usr/work/dir2歸檔為work.har,并儲存在目标目錄/data/search下,指令如下:
2)檢視archive檔案
用于hadoop叢集之間複制資料。
fsck是HDFS檔案系統的檢查工具。當使用者發現HDFS上的檔案可能受損時,可以使用這個指令進行檢查,方法如下:
當神已無能為力,那便是魔渡衆生