cat:檔案檢視
cat [OPTION]... [FILE]...
-E:-E: 顯示行結束符$
-n: 對顯示出的每一行進行編号
-A:顯示所有控制符
-b:非空行編号
-s:壓縮連續的空行成一行
more:分頁檢視檔案
more [OPTIONS...] FILE...
-d: 顯示翻頁及退出提示
less:一頁一頁地檢視檔案或STDIN輸出
檢視時有用的指令包括:
/文本搜尋文本
n/N跳到下一個或上一個比對
less 指令是man指令使用的分頁器
head:顯示文本前n行
head [OPTION]... [FILE]...
-c #: 指定擷取前#位元組
-n #: 指定擷取前#行
-#:指定行數
tail:顯示文本後n行
tail [OPTION]... [FILE]...
-c #: 指定擷取後#位元組
-n #: 指定擷取後#行
-#:
-f: 跟蹤顯示檔案新追加的内容,常用日志監控
cut:顯示檔案或STDIN資料的指定列
cut-d:-f1/etc/passwd
cat /etc/passwd|cut-d:-f7
cut-c2-5/usr/share/dict/words
paste:合并兩個檔案同行号的列到一行
paste [OPTION]... [FILE]...
-d:分隔符:指定分隔符,預設用TAB
-s:所有行合成一行顯示
paste f1 f2
paste -s f1 f2
uniq:從輸入中删除前後相接的重複的行
uniq[OPTION]... [FILE]...
-c: 顯示每行重複出現的次數
-d: 僅顯示重複過的行
-u: 僅顯示不曾重複的行
連續且完全相同方為重複
常和sort 指令一起配合使用:
sort userlist.txt | uniq-c
sort:文本排列
-n 按數字排列
-r 倒序排列,預設升序
-t 指定分隔符
-k 指定哪一列
-f 忽略大小寫
-u 删除重複行
diff :比較
diff f1 f2 比較兩個檔案的不同之處
diff -u f1 f2 > diff.log
rm -f f2
patch -b f1 diff.log
mv f1 f2
mv f1.orig f1
grep:文本搜尋工具,根據使用者指定的“模式”對目标文本逐行進行比對檢查;列印比對到的行
模式:由正規表達式字元及文本字元所編寫的過濾條件
grep [OPTIONS] PATTERN [FILE...]
grep root /etc/passwd
grep "$USER" /etc/passwd
grep '$USER' /etc/passwd
grep `whoami` /etc/passwd
--color=auto 關鍵字高亮顯示
-v 反向搜尋
-i 忽略大小寫
-n 顯示行号
-c 不顯示搜尋結果,僅顯示比對的行數
-o 僅顯示比對到的字元串
-q 靜默輸出
-A # 顯示搜尋行及其向下相臨的#行
-B # 顯示搜尋行及其向上相臨的#行
-C # 顯示搜尋行及其向上和向下相臨的#行
-e char1 -e char2 [-e charN] 多個選項間or關系
-w 比對整個單詞
-E 或egrep 支援擴充正規表達式
-F 或fgrep 不支援正規表達式
正規表達式
REGEXP:由一類特殊字元及文本字元所編寫的模式,其中有些字元(元字元)不表示字元字面意義,而表示控制或通配的功能
程式支援:grep,sed,awk,vim, less,nginx,varnish等
分類:
基本正規表達式:BRE
擴充正規表達式:ERE
grep -E,egrep
正規表達式引擎:
采用不同算法,檢查處理正規表達式的軟體子產品
PCRE(Perl Compatible Regular Expressions)
元字元分類:字元比對、比對次數、位置錨定、分組
man 7 regex
基本正規表達式元字元
字元比對:
. 比對任意單個字元
[] 比對指定範圍内的任意單個字元
[^] 比對指定範圍外的任意單個字元
[:alnum:] 字母和數字
[:alpha:] 代表任何英文大小寫字元,亦即A-Z, a-z
[:lower:] 小寫字母[:upper:] 大寫字母
[:blank:] 空白字元(空格和制表符)
[:space:]水準和垂直的空白字元(比[:blank:]包含的範圍廣)
[:cntrl:] 不可列印的控制字元(倒退、删除、警鈴...)
[:digit:] 十進制數字[:xdigit:]十六進制數字
[:graph:] 可列印的非空白字元
[:print:] 可列印字元
[:punct:] 标點符号
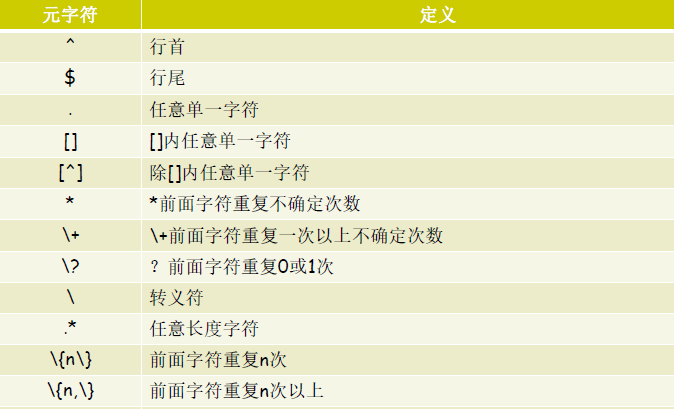
比對次數:用在要指定次數的字元後面,用于指定前面的字元要出現的次數
* 比對前面的字元任意次,包括0次
貪婪模式:盡可能長的比對
.*任意長度的任意字元
\?比對其前面的字元0或1次
\+比對其前面的字元至少1次
\{n\}比對前面的字元n次
\{m,n\}比對前面的字元至少m次,至多n次
\{,n\}比對前面的字元至多n次
\{n,\}比對前面的字元至少n次
位置錨定:定位出現的位置
^ 行首錨定,用于模式的最左側
$ 行尾錨定,用于模式的最右側
^PATTERN$ 用于模式比對整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或\b詞首錨定,用于單詞模式的左側
\> 或\b詞尾錨定;用于單詞模式的右側
\<PATTERN\>比對整個單詞
分組:\(\) 将一個或多個字元捆綁在一起,當作一個整體進行處理,如:\(root\)\+
分組括号中的模式比對到的内容會被正規表達式引擎記錄于内部的變量中,這些變量的命名方式為: \1, \2, \3, ...
\1表示從左側起第一個左括号以及與之比對右括号之間的模式所比對到的字元
示例:\(string1\+\(string2\)*\)
\1 :string1\+\(string2\)*
\2 :string2
後向引用:引用前面的分組括号中的模式所比對字元,而非模式本身
或者:\|
示例:a\|b: a或b C\|cat: C或cat \(C\|c\)at:Cat或cat
egrep及擴充的正規表達式
egrep= grep -E
egrep[OPTIONS] PATTERN [FILE...]
擴充正規表達式的元字元:
次數比對:
*:比對前面字元任意次
?: 0或1次
+:1次或多次
{m}:比對m次
{m,n}:至少m,至多n次
位置錨定:
^ :行首
$ :行尾
\<, \b :語首
\>, \b :語尾
分組:
()
後向引用:\1, \2, ...
或者:
a|b: a或b
C|cat: C或cat
(C|c)at:Cat或cat
字元比對:
. 任意單個字元
[] 指定範圍的字元
[^] 不在指定範圍的字元
![FCC——Convert HTML Entities[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)