Hadoop是一個技術生态圈,zookeeper是hadoop生态圈裡一個非常重要的技術,當我研究學習hadoop的相關技術時候,有兩塊知識曾經讓我十分的困惑,一個是hbase,一個就是zookeeper,hbase的困惑源自于它在颠覆了我對資料庫模組化的了解,而zookeeper的困惑卻是我無法了解它到底是幹嘛的。
前不久我結合我了解的一種遠端調用服務的設計來幫助我了解zookeeper在實際的生産中運用,該文章的位址是:
其實這篇文章寫完後,我自己感覺并不是太好,因為寫本文的時候,對遠端調用服務的設計以及zookeeper的了解都不是很到位,但是這篇文章還是受到了大家很大的關注,被部落格園作為了推薦文章,還有很多網友希望我寫一篇更加詳盡的文章,還有童鞋留言說這個設計方案和淘寶開源的dubbo和hsf類似。我相信大家的關注就是意味着這個主題是當下技術的熱點,是以今天我要寫一篇主題和上篇文章一樣的博文,這是上篇文章的更新版,不管是遠端調用服務還是zookeeper我都會給出更加詳盡的講解。不過這裡還是要說明下,這篇文章裡遠端服務的設計我還是沒有參照dubbo,因為最近實在太忙,沒有時間研究淘寶的dubbo,但是我希望學習過dubbo的童鞋可以幫我對比下我的方案和dubbo的差別,差別就會産生新的問題,也會有新的知識需要研究。
本文是該主題的上篇,主要是講解遠端調用服務的相關知識,下篇則是根據遠端調用服務架構設計中zookeeper的相關應用方法詳細講解關于zookeeper的知識。
首先我們要再深入了解下為什麼應用軟體服務裡需要一個遠端調用服務,遠端調用服務解決了軟體設計中的什麼問題,它的架構設計又有什麼理論根據了?
我曾寫了一篇關于分布式網站架構設計的文章,文章位址是:
在文章開頭我就把這個新的網站架構方案和傳統的企業軟體的B/S架構作了對比,我将一個網站裡提供業務服務的元件抽象為獨立的服務系統,接收使用者資訊的邏輯部分抽象為前端系統,服務系統和前端系統使用netty這樣的通訊元件進行通訊,而到了講解遠端調用服務的架構設計時候我将netty通訊元件進一步抽象為一個通訊獨立系統及遠端調用服務,這就是為什麼要設計遠端調用服務的緣起了,遠端調用服務又會帶來了網站架構的更新,如果傳統的企業B/S架構為1.0版,我将前端和業務服務端分離為獨立系統則是2.0版,那麼引入了遠端調用服務網站就是3.0版了,3.0版的架構帶來的好處就是可以将N多的前端系統和N多的業務服務端系統融為一個整體,網站的規模會越來越大,提供的服務也會越來越多,這既避免重複造輪子的問題還使得網站規模越來越大。
3.0版本的網站架構帶來了新的網站架構總圖,如下所示:
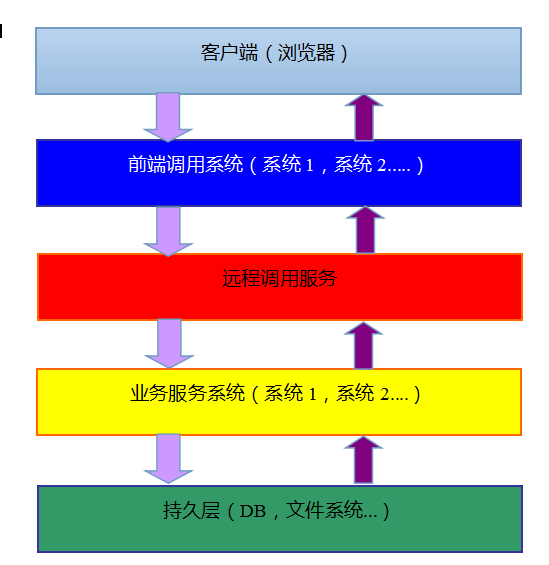
有了遠端調用服務,我們可以做到業務級别的叢集,例如:一個制造企業,一般都會有采購業務,生産業務、銷售業務以及财務業務,按照傳統的思路我們都會給每個業務獨立開發一個系統,如果引用了遠端調用服務,我們可以将這些業務都做成獨立的服務,這些服務組成業務叢集,而這些服務都是用統一的遠端調用服務作為操作的入口,換句話說不管什麼樣的服務對于調用者來說都是統一的,這樣前端的調用者可以做到應用的統一,所謂的應用的統一淘寶網站是最典型的代表,我們在一個同一的網站裡可以操作各種不同的應用,而不會發生因為應用的不同我們就得重新通路新的位址或者重新登入到另外一個系統裡做其他業務的操作。而服務端這邊,完全可以擺脫傳統的用戶端和服務端耦合的開發,增強了整個服務端的專業性和穩定性,這樣更易于服務端的擴充性和可維護性。如果服務端之間也需要互相調用也可以通過遠端調用服務實作,由于遠端調用服務的統一性,這樣就避免了服務調用之間封包和調用方式的不統一,規範了整個開發的流程。如果遠端調用服務還有負載均衡功能,整個服務叢集就變成了一個私有的雲,是以說遠端調用服務是雲計算的重要組成部分,這個說法一點都不為過。
遠端調用服務的理論依據是什麼,這個問題的表述可能有點問題,其實我要講的是遠端調用服務的技術原型就是SOA(Service-Oriented Architecture),在雲計算出現前,SOA曾一度是IT的技術熱點,雖然之後很多人說中國的SOA做的一點不好,就和早年的DHTML一樣,诟病遠多于贊賞,寫本文時候我在京東裡搜尋了下SOA,從書籍的出版日期和書籍評價數就可以看出SOA已經有點無人問津的凄涼了。下面我要簡單介紹下SOA,SOA的定義:
SOA是一個軟體架構,它包含四個關鍵概念:應用程式前端、服務、服務庫和服務總線。一個服務包含一個合約、一個或多個接口以及一個實作。
應用程式前端可以了解為我上面所講述的調用者和前端系統,服務庫可以了解為服務叢集,這裡還有個服務是什麼呢?服務就是調用者和服務提供者完成某一個特定業務的合約,換句話說就是封裝的業務規則,打個比方,我們在淘寶去購物,下訂單,付款,查物流,确定付款這些操作在服務端都有獨立的服務提供,但是從購物這個概念去了解,這些獨立的服務才能構成這個完整的購物行為,如果其中有地方出了問題,會有相應不同的操作,那麼這個就絕對不是調用者簡單調用服務接口的問題,需要更高層次的業務封裝,将上面這些操作封裝為一個統一的服務,這個就是所謂的服務。最後一個要素服務總線,這就是我們本文所談的重要主題:遠端調用服務了。
這裡談談SOA的目的是想起到抛磚引玉的作用,讓那些想深入研究遠端調用服務的人可以從SOA的角度了解遠端調用服務,而那些還是不明白遠端調用是何物的童鞋可以通過SOA的概念來了解遠端調用服務。
遠端調用服務技術詳解,詳解,嗚嗚~~,這兩個字很有壓力,我怕有童鞋看了這個标題會以為我會将整套技術實作方案寫到裡面,這個難度太高了,寫幾萬字估計都說不清楚,再說真的寫的那麼細緻,估計很多人都看不懂了(嘿嘿,我自己也沒有技術實作過哦,這些都是構思,構思哦),是以詳解就是詳解原理。
下面我将上篇文章的架構圖放進來,大家再仔細看看這張圖:

傳統的服務調用都是服務提供者和服務調用者的直接調用,從架構圖裡我們看到這裡多了一個遠端調用管理元件,遠端調用管理元件是一個獨立的服務系統,為了保證該系統的穩定性,它也一定是一個分布式的系統,但是這個分布式系統和Web的分布式系統是完全不同的分布式系統,傳統Web應用叢集是基于HTTP協定的無狀态的特點設計的,因為每個HTTP請求都是一個獨立的事務,不同請求之間是沒有任何關系的,是以我們可以将Web應用部署到不同伺服器上,請求不管到了那台伺服器,都能正常的給使用者提供相應的服務,但是Web應用的session機制是有狀态的,是以傳統Web叢集都是要有session同步的操作,大型網站往往會把session功能抽象為獨立的緩存系統,但是這裡的遠端調用管理元件的叢集原理或者說分布式原理是有别于Web應用叢集分布式原理的,遠端調用管理元件可以當做一個注冊中心,它會記錄下服務提供者和服務調用者的相關資訊,并将這些資訊推送給服務提供者或者服務調用者,為了保證系統的執行效率,這些注冊資訊都是記錄在記憶體裡,我們試想下,如果這些注冊資訊丢失,整個系統将會不可用,是以遠端調用管理元件的叢集是一種保證資料可靠性和服務提供健壯性的叢集,而不是建立在HTTP無狀态特性基礎上的叢集。我們這裡假想下遠端調用服務的叢集運作場景,我們假如有5台伺服器作為遠端調用服務運作的伺服器,那麼每台伺服器都必須有注冊資訊的備援備份,當服務運作時候其中一台伺服器發生了故障,這台故障的伺服器上的資料不會丢失,此外叢集應該還要有一個檢查故障的機制,當發現有台伺服器不可用的時候,能及時剔除該伺服器,而zookeeper就是解決這種問題的技術架構。此外除了保證系統的穩定性和可用性外,叢集的資料存儲方式也是很重要的,前面我講到叢集的資料存儲要有一個備援機制,除了備援機制還要有一個很适合快速通路和讀寫的資料模型,而zookeeper正好包含這種資料模型,是以我設計的遠端調用服務是一個很适合zookeeper應用的場景,至于zookeeper的詳細知識我會在下篇裡詳細講到。
遠端調用管理元件還有一個心跳機制,心跳機制的作用是檢測服務提供者的健康性及服務提供者是否可用,服務提供者啟動時候會将自己的注冊資訊發送給遠端調用管理元件,這個注冊資訊裡包含服務端的ip位址和端口号,遠端調用管理元件會啟動一個線程,根據定時對這個ip位址和端口号去ping這個ip和端口号對應的應用是否可用,如果不可用遠端調用管理元件會反複嘗試幾次,這個次數和多久檢測心跳都是可以配置的,如果反複幾次還是不通,那麼就認定該服務不可用了。有網友在QQ上問我,為什麼不檢測服務調用者的心跳,這個完全沒必要哦,調用者是主動方,提供者是被動方,這就好比你通路網站,如果你生病了不去通路了,系統沒有必要檢查你是否已經生病了。
遠端調用架構需要使用序列化和反序列化技術,這點也讓很多童鞋不太了解,不了解的原因還是對序列化和反序列化技術的不了解,序列化技術主要是應用與資料持久化(資料存到硬碟)或者網絡通訊,不管是資料存儲到硬碟還是進行網絡通訊,這些資料都會轉化為二進制,序列化就是将正在運作的對象轉化為可以存儲和傳輸的二進制資料,而反序列化是可以将這些二進制資料反向還原成原來的對象資訊,還原的對象還是可以被程式操作的,而我們設計的遠端調用架構傳遞就是不同系統之間可以互相使用的程式代碼,是以我們需要使用序列化和反序列化技術。這裡就有一個問題,例如我們傳輸一個對象,這個對象對應的類是N多個類的繼承子類,而且這個對象裡可能還會引用其他的對象例如String,ArrayList等等,那麼為了讓反序列化的對象可用,序列化的時候就會将這些資訊也包含在二進制資料裡,并且這些資訊一起進行網絡傳輸,這就導緻資料傳輸量特别大,而jdk自帶的序列化機制會導緻這些附帶資訊更大,是以有必要使用比jdk更好的序列化機制,讓資料量變小,并且序列化和反序列化的效率更高,上篇文章裡我推薦了一種序列化架構hession,當然使用者想使用什麼序列化機制這個我也讓使用者可以自己配置,這也是外部配置檔案的一個選項。
前面文章裡我還講到了壓縮技術并且推薦了google公司使用snappy,這個壓縮技術也是為了讓網絡傳輸的資料量變小,提升網絡的傳輸效率。
對于服務提供者和服務調用者我會提供一個jar包,這些工程都要引入這個jar包,同時還需要一個配置檔案來定義一些需要使用者定義的參數,例如我們使用一個名字叫ycdy_config.properties配置檔案,裡面的key值介紹如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<code>Config_center_url=ip:port;這個就是配置遠端管理中心的ip位址和端口号;</code>
<code>Server_type=provider/consumer;配置是服務調用者還是提供者,不配置預設是提供者;</code>
<code>Provider_post=9999,這是服務提供者的端口号,調用者可以不配置,其實調用配置了也沒啥用,如果提供者不配置,會有預設值的;</code>
<code>Provider_session_timeout=9000;服務提供者的逾時時間,如果實際調用超過了這個時間,那麼說明服務調用逾時,适用于服務調用者,提供者無效</code>
<code>Tick_time=3000;心跳時間,這是遠端調用中心檢測服務端心跳的間隔時間,适用于服務提供者;</code>
<code>Again_time=3;當服務提供者不通的時候,心跳反複檢測的次數,超過了次數就标記該服務不可用;Provider_session_timeout、Tick_time和Again_time三者之間是有一定關系,這個關系要實作這具體把控了;</code>
<code>Ip_include_pattern=172\\.17\\.138.*|192\\.168\\.0\\..*,這個适用于服務提供者,因為一台伺服器可能存在多個ip位址,當遠端調用服務元件接收到提供者的ip,用這個配置項來辨認那個ip可用,這裡采用正規表達式的方式;</code>
<code>Ip_exclude_pattern=用于服務提供者,需要忽略的ip;</code>
<code>Consumer_policy=random/rotate;适用于調用者,調用者向提供者請求的負載均衡政策,我熟悉的隻有兩種一種是使用随機數,一種使輪詢,是以這裡目前就這兩種選項;</code>
<code>Monitor_log=</code><code>true</code><code>/</code><code>false</code><code>;是否開啟監控日志,适用于服務提供者,任何系統日志時最重要的,否則沒法查生産問題,其實這個配置項應該可以充實點,但是我現在還沒想好,是以先給個提示,具體到了生産看如何實作吧。</code>
大家看到了不管是作為服務提供者還是服務調用者使用的配置檔案是一緻的,而且一個應用既可以配置成服務的調用者也可以配置成服務的提供者,非常的靈活。
遠端調用服務還需要一個重要的技術就是通訊技術,這裡的通訊技術我推薦netty,netty是個非常好的選擇,講到通訊是個複雜的課題,如果以後有空我再做詳細介紹,通訊層的東西是封裝到服務提供者和服務調用者引入的jar包裡,但是通訊的ip位址和端口号則是需要遠端調用管理元件推送過來的。
那麼在應用裡遠端調用服務到底如何使用了?哈哈,這時候spring就要上場了,我們看看服務調用者和服務提供者的spring配置,如下所示:
我們發現這個新配置和以前不同了,這個配置将更加适合生成的開發。
我們首先看看serverProvider的設計,這個bean對應的class是cn.com.sharpxiajun.RmifSpringProviderBean,裡面有個參數是一個interfaceName即提供者對外的接口,這裡我會使用反射機制将接口注入到RmifSpringProviderBean,而target則是具體的實作對象了,這就是業務對象,注意interfaceName一定要是接口,因為調用者會根據接口進行轉化,如果是類的話,那麼通用性就很差了。
clientConsumer的設計,這個bean所對應的class是cn.com.sharpxiajun.RmifSpringConsumerBean,其中interfaceName的value值對應的就是遠端定義的接口,和提供者的interfaceName保持一緻,當提供者的資料傳導調用者後,就會根據這個雙方約定好的接口反序列化成可以操作的對象,serialType是選擇序列化機制,不寫的話就是調用jdk的序列化機制,這裡附帶提下啊,外部的序列化程式也是放到jar包裡的哦,還有一個選項是compressEnabled作用是是否啟用傳輸封包壓縮。
當調用者調用提供者服務時候,jar包裡netty程式會根據推送的資訊(主要是ip,端口)和spring配置的bean結合起來就可以完成一次服務的調用。
好了,上篇寫好了,本篇主要是講解遠端調用服務的架構設計,我自我感覺這篇文章比上篇更接地氣,希望看了本文的童鞋,能對遠端調用架構設計的原理更加清晰。
其實netty的使用學問也很大,也是遠端調用服務的核心之一,本文這塊講的比較少,以後有時間我盡量補充上這塊知識。
下篇文章我将詳細介紹遠端調用架構裡使用到的zookeeper技術。
這是2013年的最後一篇博文了,祝大家新年快樂哦。
QQ:519841366
本頁版權歸作者和部落格園所有,歡迎轉載,但未經作者同意必須保留此段聲明,
且在文章頁面明顯位置給出原文連結,否則保留追究法律責任的權利