目錄
一、概述
二、基本概念
三、元件
1. source
1.1 NetCat Source
1.2 Avro Source
1.3 Exec Source
1.4 Spooling Directory Source
1.5 Squence Generator Source
1.6 HTTP Source
1.7 自定義Custom Source
2. Channel
2.1 Memory Channel
2.2 File Channel
2.3 JDBC Channel
2.4 記憶體溢出通道
3. Sink
3.1 Logger Sink
3.2 File_roll Sink
3.3 HDFS Sink
3.4 Avro Sink
四、流動方式
1. 多級流動
2. 扇出流
3. 扇入案
五、Source模式
1. 複制模式
2. 路由模式
六、interceptor
1. 時間戳Timestamp Interceptor
案列:存到HDFS上,并且按天存放
2. Search And Replace Interceptor
3. Regex Filtering Interceptor
七、Processor
1. 崩潰恢複 Failover Sink Processor
2. 負載均衡 Load Balancing Sink Processor
八、事務機制
1. source——channel:put事務流程
2. channel——sink:Take事務
Flume是Cloudera設計的,後來貢獻給了Apache
Flume是一個分布式、可靠的、用于進行日志收集的系統 - 采集、彙總、傳輸
Flume中傳輸的每一條資料是一條日志
Event:在Flume中,将它傳輸的每一條日志封裝成一個Event對象,也就意味着在Flume中傳輸的Event對象。Event對象展現形式是一個json串,這個json串分為了兩部分:headers和body
Agent:在Flume中,傳輸資料用的元件就是Agent。Agent中包含了三個子元件:
Source:從資料源采集資料
Channel:臨時存儲資料
Sink:将資料發往目的地
3. 流動方式:單級流動,多級流動,扇入流動,扇出流動 (每一個Sink隻能綁定一個Channel)
NetCat Source用來監聽一個指定端口,并接收監聽到的資料,接收的資料是字元串形式
在測試時使用,實際開發少
配置:
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = netcat a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 8090 a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity=1000 a1.sinks.k1.type = logger a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
用戶端:
[root@lj02 software]# rpm -ivh nc-1.84-22.el6.x86_64.rpm //安裝nc
[root@lj02 software]# nc lj02 8090 hello OK
avro-source接收到的是經過avro序列化後的資料,然後反序列化資料繼續傳輸。
利用Avro source可以實作多級流動、扇出流、扇入流等效果
可以接收通過flume提供的avro用戶端發送的日志資訊
a1.sources=s1 a1.channels=c1 a1.sinks=k1 a1.sources.s1.type=avro a1.sources.s1.bind=0.0.0.0 a1.sources.s1.port=8090 a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.sinks.k1.type=logger a1.sources.s1.channels=c1 a1.sinks.k1.channel=c1
啟動伺服器端:
[root@lj02 bin]# flume-ng agent -n a1 -c ../conf/ -f ../data/2avrosource.conf -Dflume.root.logger=INFO,console
出現Avro source s1 started. 說明啟動成功
avro用戶端啟動
[root@lj02 bin]# flume-ng avro-client -H 0.0.0.0 -p 8090 -F /home/a.txt -c ../conf/
在伺服器端可以看見檔案裡面的資料
Event: { headers:{} body: 6A 6A 6A 6A 6A 6A 6A 6A 6A 6A 6A 6A 6A 6A 6A 6A jjjjjjjjjjjjjjjj }
可以将指令産生的輸出作為源來進行傳遞
配置
a1.sources.s1.type = exec a1.sources.s1.command = cat /home/a.txt a1.channels.c1.capacity =1000 a1.channels.c1.transactionCapacity =100
伺服器端啟動:[root@lj02 bin]# flume-ng agent -n a1 -c ../conf/ -f ../data/3execsource -Dflume.root.logger=INFO,console
直接顯示結果:
2019-07-05 11:28:39,750 (pool-3-thread-1) [INFO - org.apache.flume.source.ExecSource$ExecRunnable.run(ExecSource.java:376)] Command [cat /home/a.txt] exited with 0
flume會持續監聽指定的目錄,把放入這個目錄中的檔案當做source來處理
注意:一旦檔案被放到“自動收集”目錄中後,便不能修改,如果修改,flume會報錯。也不能有重名的檔案,負責flume也會報錯
a1.sources.s1.type = spooldir a1.sources.s1.spoolDir = /home/flumedata
伺服器端啟動:
[root@lj02 bin]# flume-ng agent -n a1 -c ../conf/ -f ../data/4spolldirsource.conf -Dflume.root.logger=INFO,console
檔案再被監聽後,名稱後面會有變化 a.txt.COMPLETED 檔案已被監聽。
一個簡單的序列發生器,不斷的産生事件,值是從0開始每次遞增1,主要用來測試
a1.sources.s1.type = seq a1.sources.s1.batchSize = 5
[root@lj02 data]# ../bin/flume-ng agent -n a1 -c ../conf/ -f ../data/5seqgensource.conf -Dflume.root.logger=INFO,console
列印結果:是有順序的一大批數字
此Source接受HTTP的GET和POST請求作為Flume的事件
GET方式隻用于試驗,是以實際使用過程中以POST請求居多
如果想讓flume正确解析Http協定資訊,比如解析出請求頭、請求體等資訊,需要提供一個可插拔的"處理器"來将請求轉換為事件對象,這個處理器必須實作HTTPSourceHandler接口。這個處理器接受一個 HttpServletRequest對象,并傳回一個Flume Envent對象集合
a1.sources.s1.type = http a1.sources.s1.port = 8070 a1.channels.c1.capacity = 500 a1.channels.c1.transactionCapacity = 100
執行啟動指令
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f httpsource.conf -Dflume.root.logger=INFO,console
另一個機器執行:執行curl 指令,模拟一次http的Post請求:
curl -X POST -d '[{"headers":{"name":"lj","age":"20"},"body":"you are beautiful"}]' http://0.0.0.0:8090
通常情況下,Flume提供的source應該是夠用的,但是有時候因為業務場景的需求,可能會導緻Flume中提供的source不夠用,那這個時候就需要自定義Source
實作Configurable,作用是用于擷取檔案中的配置
實作EventDrivenSource或者PollableSource
3.1 EventDrivenSource:事件驅動source,被動等待 - 隻要處理完資料就會一直等待,等待有新資料過來 - Avro Source、HTTP Source、NetCat Source - 覆寫start和stop方法,啟動邏輯放在start中,中止回收是放在stop中
3.2 PollableSource:輪訓發送Source,主動産生資料發送資料 - 自帶了線程,會不斷的調用這個線程往channel發資料 - Sequence Generator Source、Spooling Directory Source、Exec Source - 覆寫process方法,source的執行邏輯是放在process方法中
事件将被存儲在記憶體中(指定大小的隊列裡)
非常适合那些需要高吞吐量且允許資料丢失的場景下
将資料臨時存儲到計算機的磁盤的檔案中
性能比較低,但是即使程式出錯資料不會丢失
[root@hlj01 data]# vim filechannel.conf
a1.channels.c1.type = file a1.channels.c1.dataDirs = /home/flumechannels
啟動:
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f filechannel.conf -Dflume.root.logger=INFO,console
另一台機器:
[root@hlj01 data]# cd /home/
[root@hlj01 home]# mkdir flumechannels
[root@hlj01 home]# nc 0.0.0.0 8090
gahgha
注:Ctrl+倒退鍵,可以修改資料
事件會被持久化(存儲)到可靠的資料庫裡
目前隻支援嵌入式Derby資料庫。但是Derby資料庫不太好用,是以JDBC Channel目前僅用于測試,不能用于生産環境。
是檔案型,切換路徑資料就找不到,在哪個路徑操作,就會産生 derby.meta檔案
是單連接配接,隻能一個用戶端連接配接,不能調節連接配接數量(大資料講究高并發,分布式)
優先把Event存到記憶體中,如果存不下,在溢出到檔案中
目前處于測試階段,還未能用于生産環境
記錄指定級别(比如INFO,DEBUG,ERROR等)的日志,通常用于調試
要求,在 --conf(-c )參數指定的目錄下有log4j的配置檔案
根據設計,logger sink将body内容限制為16位元組,進而避免螢幕充斥着過多的内容。如果想要檢視調試的完整内容,那麼你應該使用其他的sink,也許可以使用file_roll sink,它會将日志寫到本地檔案系統中
每隔指定時長生成檔案儲存這段時間内收集到的日志資訊.
[root@hlj01 data]# vim filerollsink.conf
a1.sinks.k1.type = file_roll a1.sinks.k1.sink.directory = /home/flumedata //檔案被存儲的目錄 a1.sinks.k1.sink.rollInterval = 3600 //channel中的資料每隔1小時産生一個新檔案
啟動測試
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f filerollsink.conf -Dflume.root.logger=INFO,console
換機器:
[root@hlj01 home]# mkdir flumedata
lijing
換機器:我剛剛寫的兩條資料已經自動到了指定目錄下自動生成的檔案裡面了
[root@hlj01 data]# cd /home/flumedata/
[root@hlj01 flumedata]# ls
1560142854808-1
[root@hlj01 flumedata]# cat 1560142854808-1
lijing
目前它支援建立文本檔案和序列化檔案,并且對這兩種格式都支援壓縮
将事件寫入到Hadoop分布式檔案系統HDFS中
a1.channels.c1.capacity = 1000 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://hlj01:9000/flume //HDFS 目錄路徑 a1.sinks.k1.hdfs.fileType = DataStream //SequenceFile-序列化檔案,DataStream-文本檔案,CompressedStream-壓縮檔案 a1.sinks.k1.hdfs.rollInterval = 3600 //檔案生成的間隔事件
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f hdfssink.conf -Dflume.root.logger=INFO,console
到hdfs檢視
将源資料利用avro進行序列化之後寫到指定的節點上
是實作多級流動、扇出流(1到多) 扇入流(多到1) 的基礎
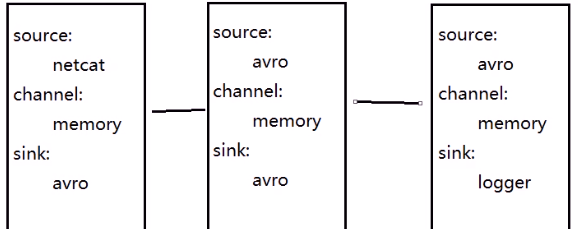
配置:vim multi.conf
01機的配置示例:
a1.sinks.k1.type = avro a1.sinks.k1.hostname = lj02 a1.sinks.k1.port = 8090
傳到其他機器:
[root@lj01 data]# scp -r /home/software/flume-1.6.0/ root@lj02:/home/software/
02機的配置示例:
a1.sources.s1.type = avro a1.sinks.k1.hostname = lj03
03機的配置:
啟動測試: 啟動順序 3 2 1 ,每隔機器都執行下面的啟動指令
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f multi.conf -Dflume.root.logger=INFO,console
複制一個機器01
我們可以看到資料從01機器到了03機器了
編輯配置檔案:vim shanchu.conf
01機的配置檔案
#配置Agent a1 的元件 a1.channels=c1 c2 a1.sinks=k1 k2 #描述/配置a1的source1 a1.sources.s1.type=netcat a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #描述sink a1.sinks.k1.type=avro a1.sinks.k1.hostname=lj02 a1.sinks.k1.port=8090 a1.sinks.k2.type=avro a1.sinks.k2.hostname=lj03 a1.sinks.k2.port=8090 a1.sources.s1.channels=c1 c2 a1.sinks.k2.channel=c2
02,03配置示例:
a1.channels=c1 a1.sinks=k1
啟動測試: 啟動順序 3 2 1
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f shanchu.conf -Dflume.root.logger=INFO,console
效果:01節點發送消息,2,3 節點都收到消息

01節點:
02節點:
a1.sources.s1.bind = /home/flumedata
[root@hadoop01 home]# mkdir flumedata
[root@hadoop01 home]# cd flumedata/
[root@hadoop01 flumedata]# vim a.txt
03節點配置:
啟動指令:
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f shanru.conf -Dflume.root.logger=INFO,console
在複制模式下,當source接收到資料後,會複制多分,分發給每一個avro sink
a1.source.r1.selector.type = replicating(這個是預設的)
使用者可以指定轉發的規則。selector根據規則進行資料的分發。基于扇入模式,用http,source
配置:vim selector.conf
01機器
a1.sources.s1.type=http a1.sources.s1.selector.type=multiplexing //multiplexing 表示路由模式 a1.sources.s1.selector.header=name //指定要監測的頭的名稱 a1.sources.s1.selector.mapping.xiaoli=c1 比對規則 a1.sources.s1.selector.mapping.bobo=c2
02,03配置示例:用 shanchu.conf的内容
[root@hlj01 ~]# curl -X POST -d '[{"headers":{"name":"xiaoli","age":"20"},"body":"hello I am fine"}]' http://0.0.0.0:8090
[root@hlj01 ~]# curl -X POST -d '[{"headers":{"name":"bobo","age":"18"},"body":"hello happy"}]' http://0.0.0.0:8090
對應的節點才會收到資訊。
攔截器采用了責任鍊模式,多個攔截器可以按指定順序攔截
配置檔案:Vim timestamp.conf
a1.sources.s1.interceptors=i1 a1.sources.s1.interceptors.i1.type=timestamp
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f timestamp.conf -Dflume.root.logger=INFO,console
測試:
效果:在頭多了一個時間
Event: { headers:{timestamp=1560151351709} body: 6C 6B 6B
配置檔案:
a1.sinks.k1.hdfs.path = hdfs://hlj01:9000/log/time=%Y-%m-%D a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.rollInterval = 3600
到hdfs檢視:lj02:50070
基于字元串的正則搜尋和替換功能,過濾替換
配置檔案:vim search.conf
a1.sources.s1.interceptors.i1.type= search_replace a1.sources.s1.interceptors.i1.searchPattern= [0-9] //要搜尋和替換的正規表達式 a1.sources.s1.interceptors.i1.replaceString= # //要替換為的字元串 a1.sinks.k1.type = loggera1.sources.s1.channels = c1
[root@hlj01 data]# ../bin/flume-ng agent -n a1 -c ../conf -f search.conf -Dflume.root.logger=INFO,console
[root@hlj01 data]# nc 0.0.0.0 8090
li123jing
接收到 :li###jing
用來包含或刨除事件
a1.sources.s1.interceptors.i1.type= regex_filter a1.sources.s1.interceptors.i1.regex= ^.*[0-9].*$ // 所要比對的正規表達式 a1.sources.s1.interceptors.i1.excludeEvents=true //如果是true則刨除比對的事件,false則包含比對的事件。
Sink Group允許使用者将多個Sink組合成一個實體
Flume Sink Processor 可以通過切換組内Sink用來實作負載均衡的效果,或在一個Sink故障時切換到另一個Sink
a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = failover #優先級 a1.sinkgroups.g1.processor.priority.k1 = 5 //設定優先級,注意,每個sink的優先級必須是唯一的 a1.sinkgroups.g1.processor.priority.k2 =7
優先發給優先級高的,高的挂了。等一會。才發給優先級低的
如果沒有指定優先級,則優先級順序取決于sink們的配置順序,先配置的預設優先級高于後配置的
提供了在多個sink之間實作負載均衡的能力
它支援輪詢(round_robin)或随機方式(random),哈希取模(hash)的負載均衡,預設值是輪詢方式,通過配置指定
也可以通過實作AbstractSinkSelector接口實作自定義的選擇機制
a1.sinkgroups=g1 a1.sinkgroups.g1.sinks=s1 s2 a1.sinkgroups.g1.processor.type=load_balance a1.sinkgroups.g1.processor.selector=round_robin // 輪叫排程算法(輪詢發送)
doPut:将批資料先寫入臨時緩沖區putList(Linkedblockingdequeue)
doCommit:檢查channel記憶體隊列是否足夠合并。
doRollback:channel記憶體隊列空間不足,復原,等待記憶體通道的容量滿足合并
putList就是一個臨時的緩沖區,資料會先put到putList,最後由commit方法會檢查channel是否有足夠的緩沖區,有則合并到channel的隊列
doTake:先将資料取到臨時緩沖區takeList(linkedBlockingDequeue)
将資料發送到下一個節點
doCommit:如果資料全部發送成功,則清除臨時緩沖區takeList
doRollback:資料發送過程中如果出現異常,rollback将臨時緩沖區takeList中的資料歸還給channel記憶體隊列